文章目录
运行脚本
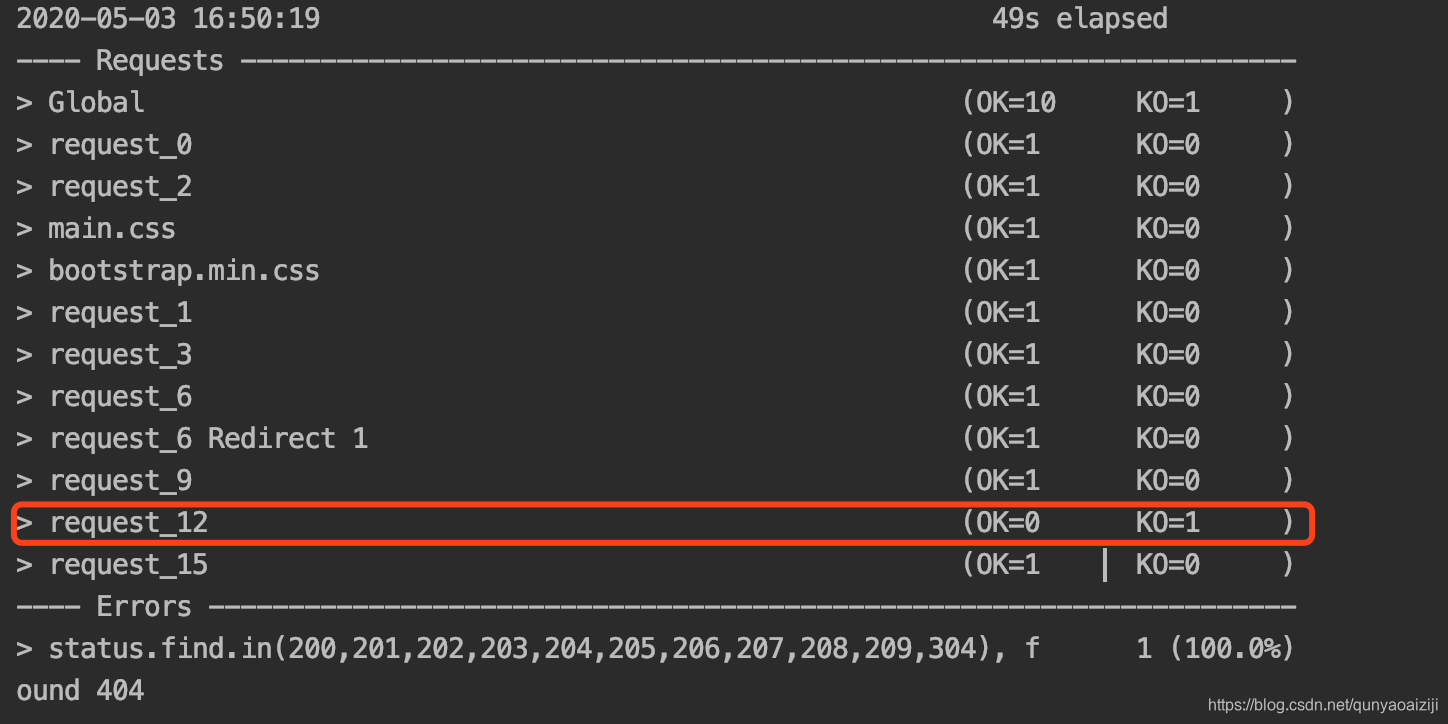
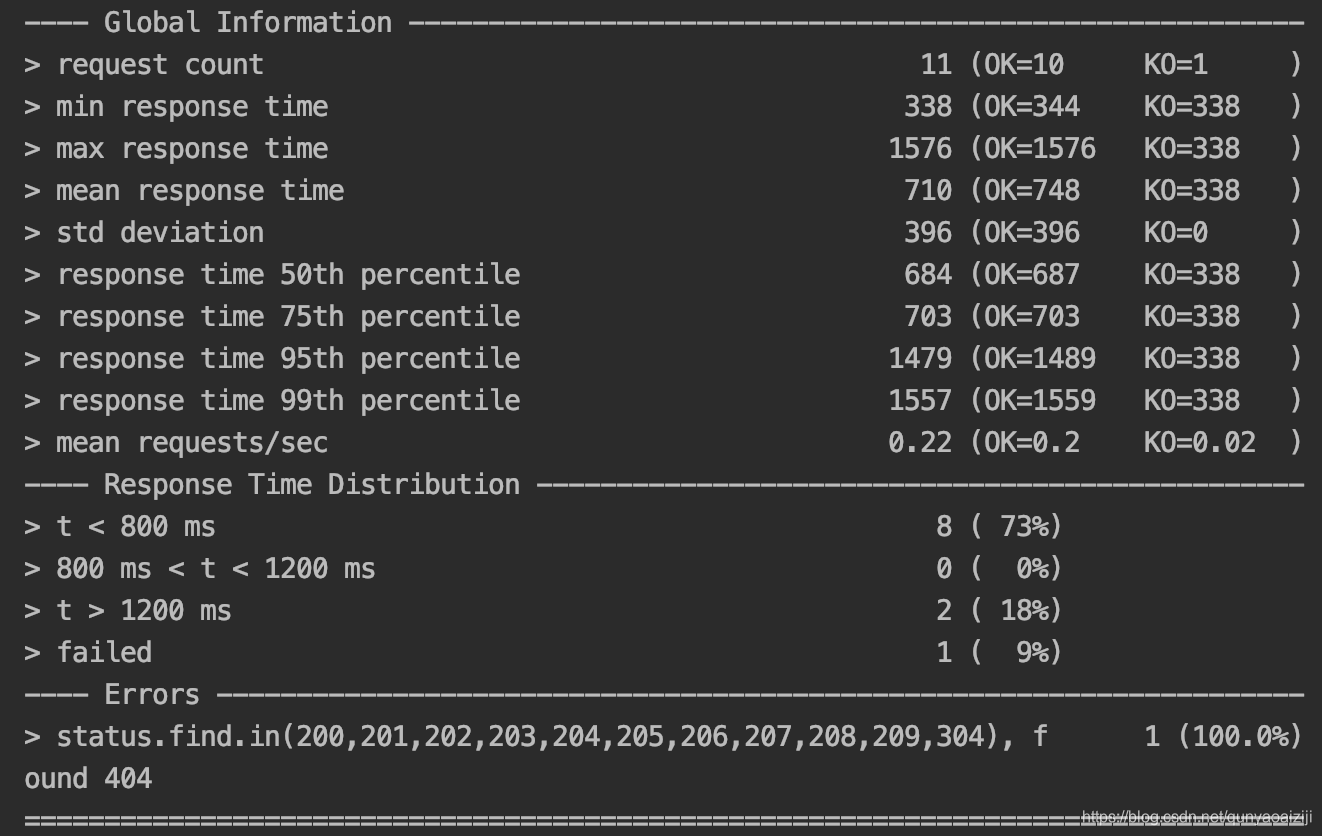
使用上一节录制好的脚本,在项目里打开后,右键运行Engine,即可运行录制的脚本了。运行结果如下图,console日志打印了请求的接口详情,也打印了分析报告,可复制到浏览器查看。但有接口请求失败了,下面就让我们一步步来解析并调试该脚本。
脚本结构
Gatling的脚本主要分为四部分:Http Protocol Configuration,Header Definition,Scenario Definition,Simulation Definition。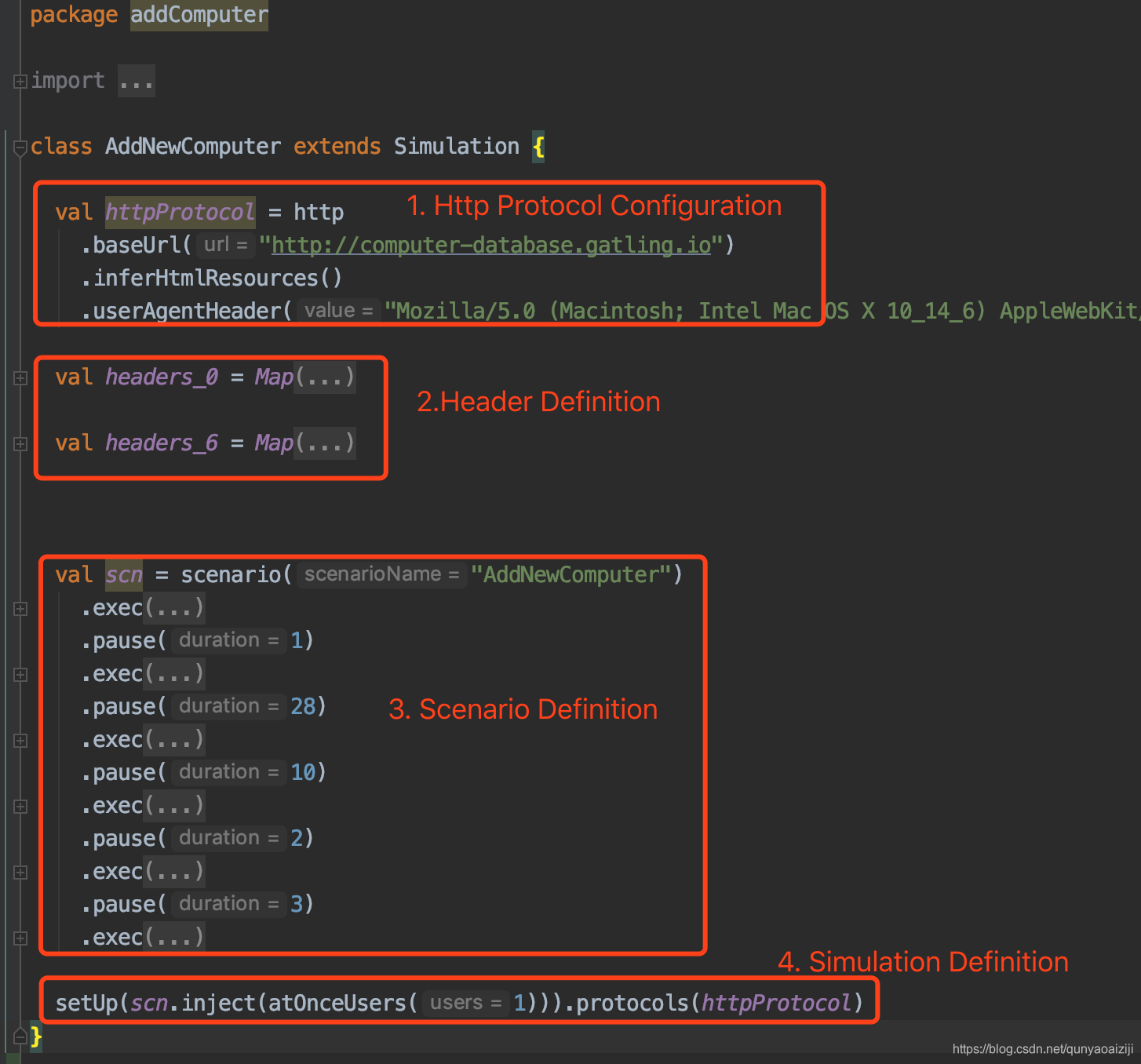
- Http Protocol Configuration
http请求配置,主要是我们访问网站的一些配置,比如url、agent等。 - Header Definition
接口请求里的header,多个header以map的形式展示,包括header的key和value。 - Scenario Definition
性能测试场景,即接口请求。 - Simulation Definition
接口请求的配置,即性能场景的配置,包括并发数并发模式等。
Http Protocol 配置
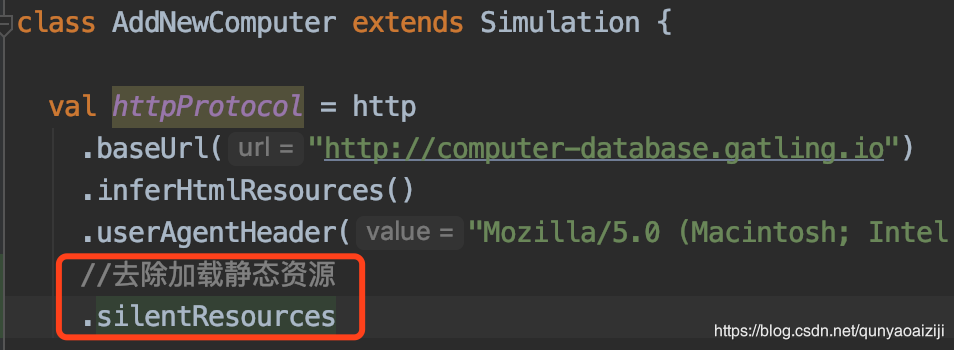
silent
我们录制的脚本没有添加表名单和黑名单,所以其中除了接口请求外,还有很多静态资源请求,我们一般是不需要这些请求的,除了在录制的时候通过添加黑白名单来控制,也可以使用silentResources方法来跳过这些请求。
Scenario配置
requestName
脚本中默认的requestName是“request_${number}”,为了更表意,我们将其改为和接口请求描述一致的名字。如下图所示:
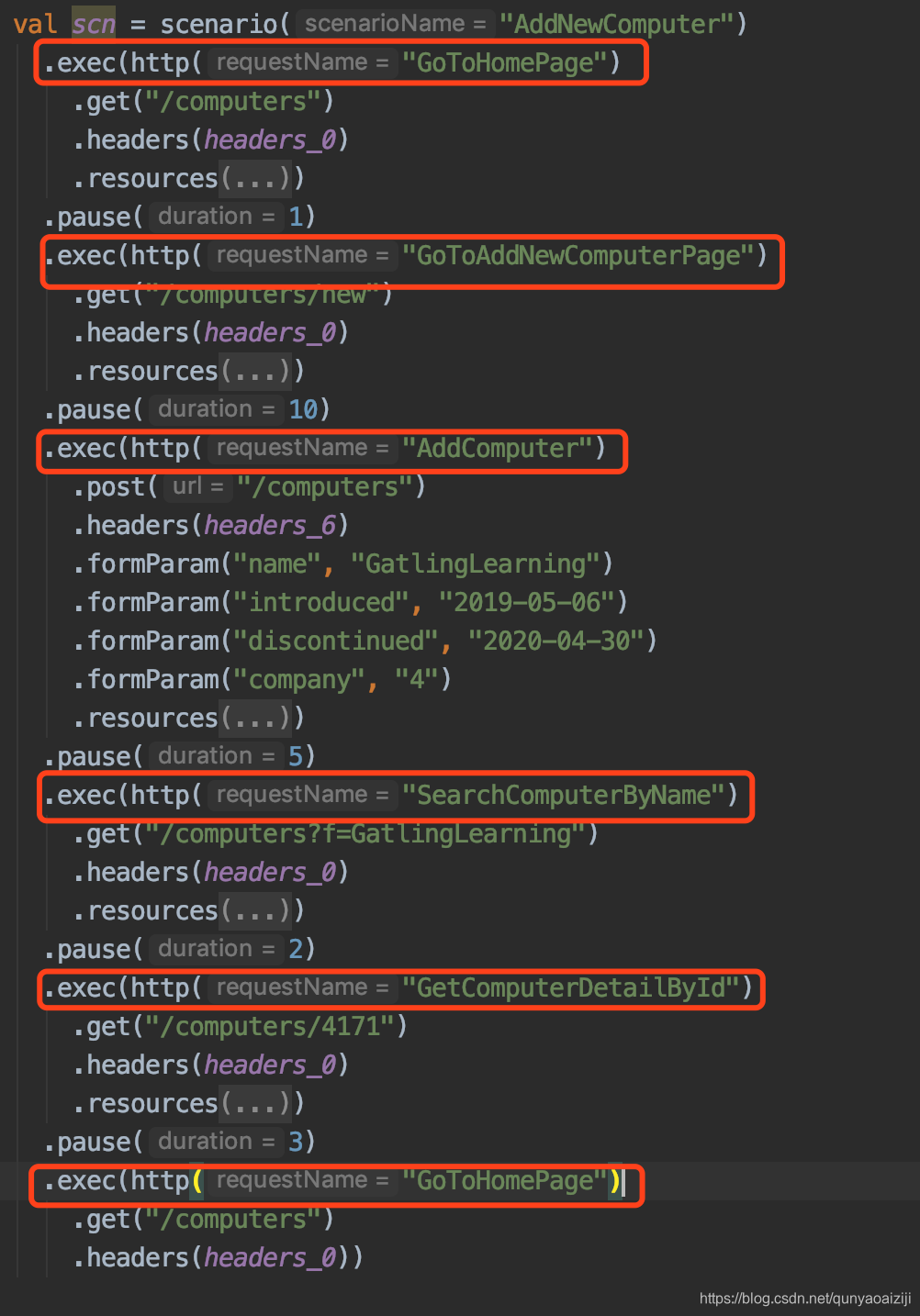
Pause
从脚本中可以看到,有很多pasue方法,顾名思义,是模拟用户在页面停留的时间,单位是秒,我么可以修改这些时间,也可以保留使其与真实场景更为接近。
checks
对于每一个请求的返回是否正确,我们可以做一些校验,使用check方法。可以检验返回码是否正确,当前页面的元素是否正确,返回的body体内容是否正确等。
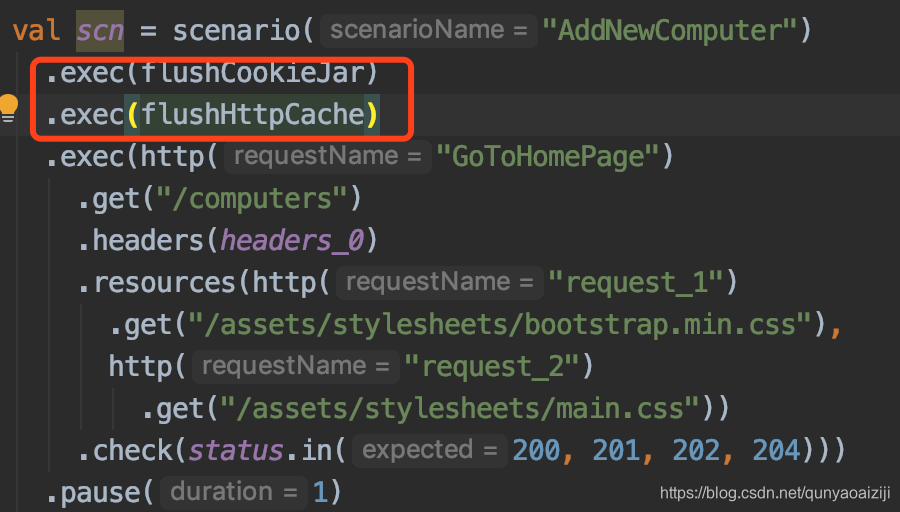
clear cache and cookies
对于某一请求,如果你希望清除浏览器缓存和cookies,可以使用flushHttpCache和flushCookieJar,我们一般在第一次访问首页的时候会这么做。
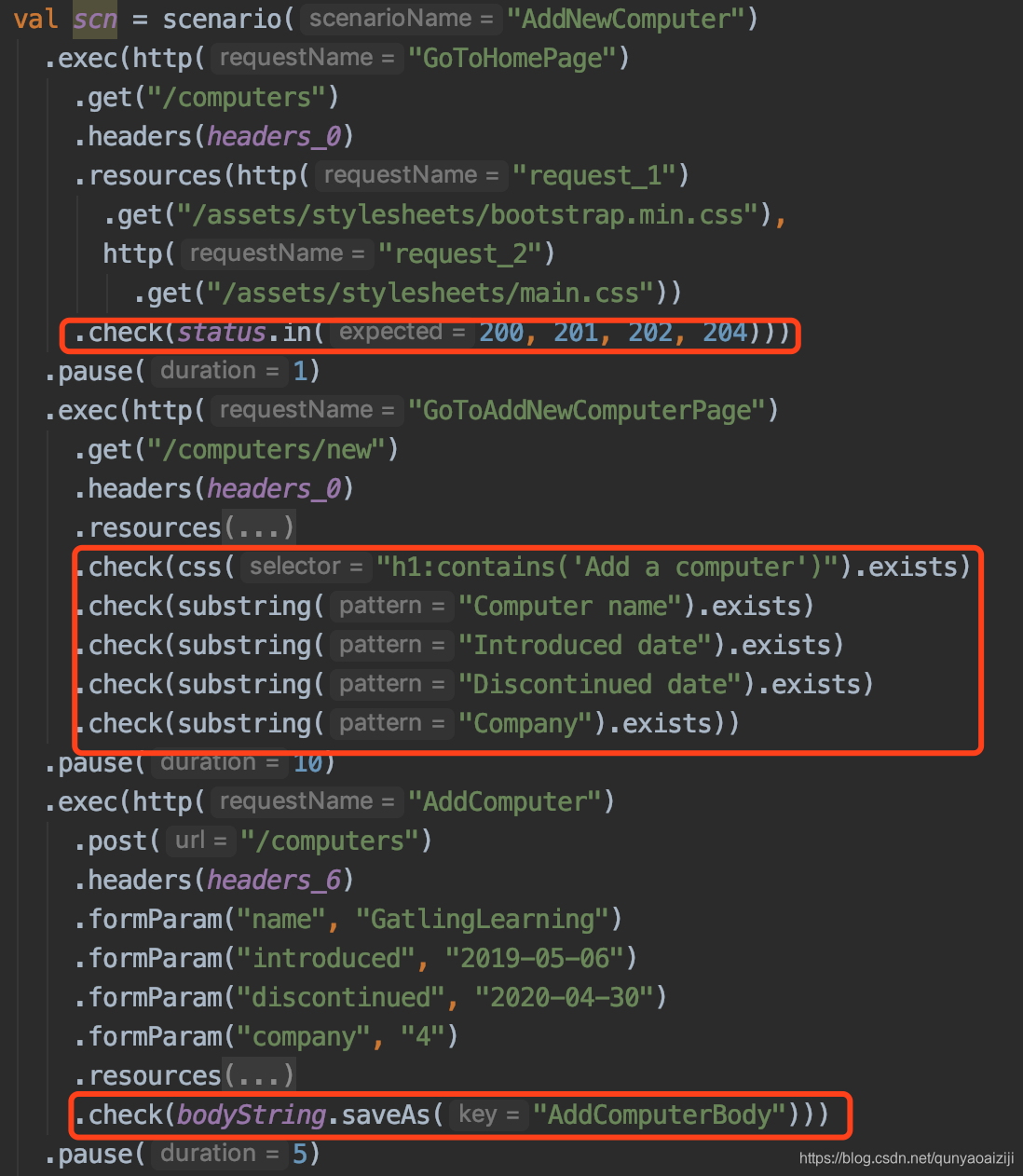
存储返回值
做过接口测试的小伙伴一定知道,很多时候特别是多接口测试的时候,下一个接口的request参数往往来自于上游接口的response,这时我们就需要将上游接口的response存起来供下游接口用,在gatling中我们可以用saveAs来实现。在我们的场景里面,由之前的运行结果可知GetComputerDetailById这个接口返回404,分析之后可知,该接口是根据电脑的ID去查询电脑的,而我们脚本里一直是使用的4171这个ID,这个ID对应的computer已经被删除了,所以返回404,而我们新添加的computer的ID已经不是这个ID了。这里就需要我们使用新添加的电脑的ID去查询其信息。
这里顺便讲一下gatling如何debug,第一种方式是在logback.xml中将日志级别调低,默认是warn,可调至debug。
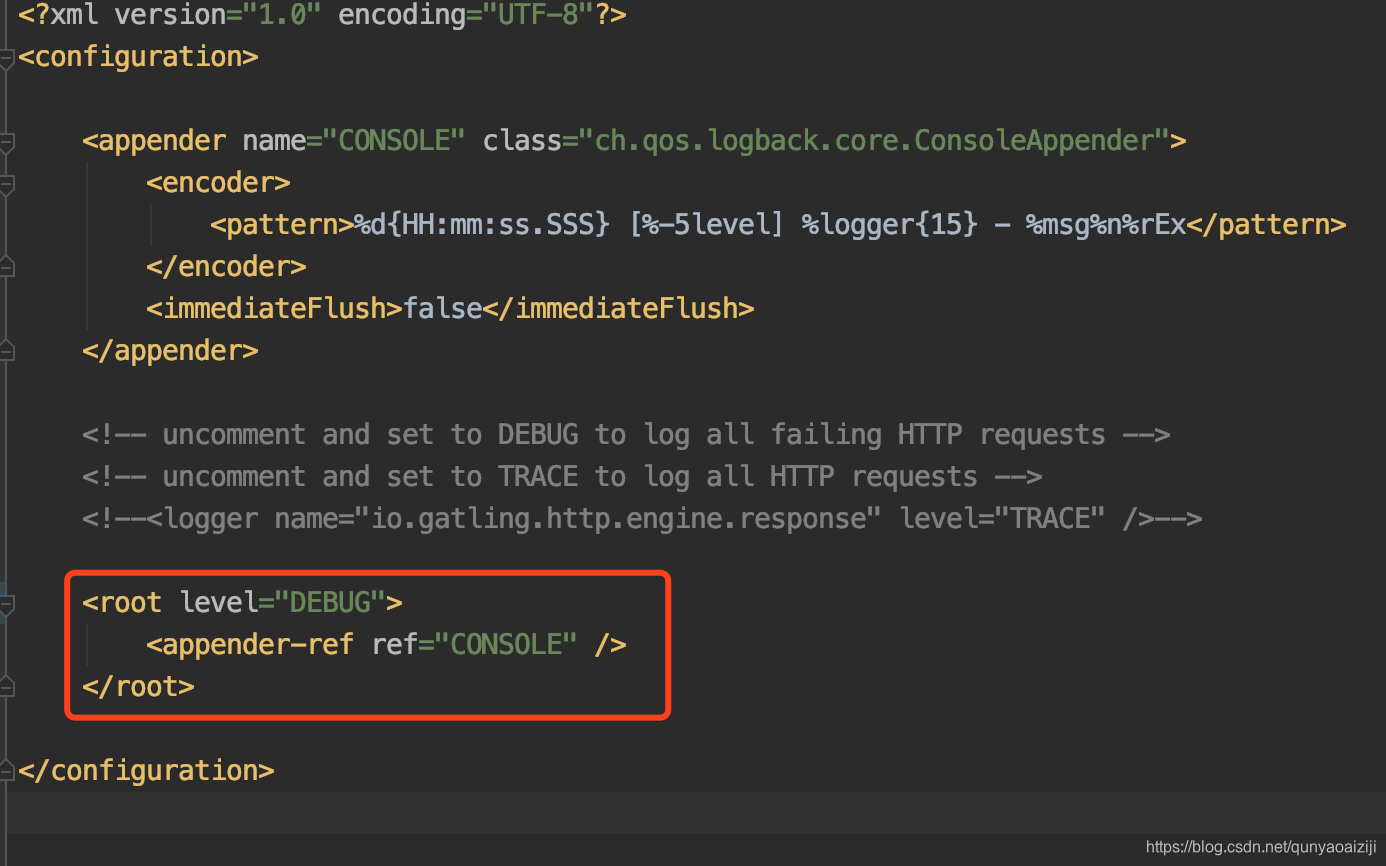
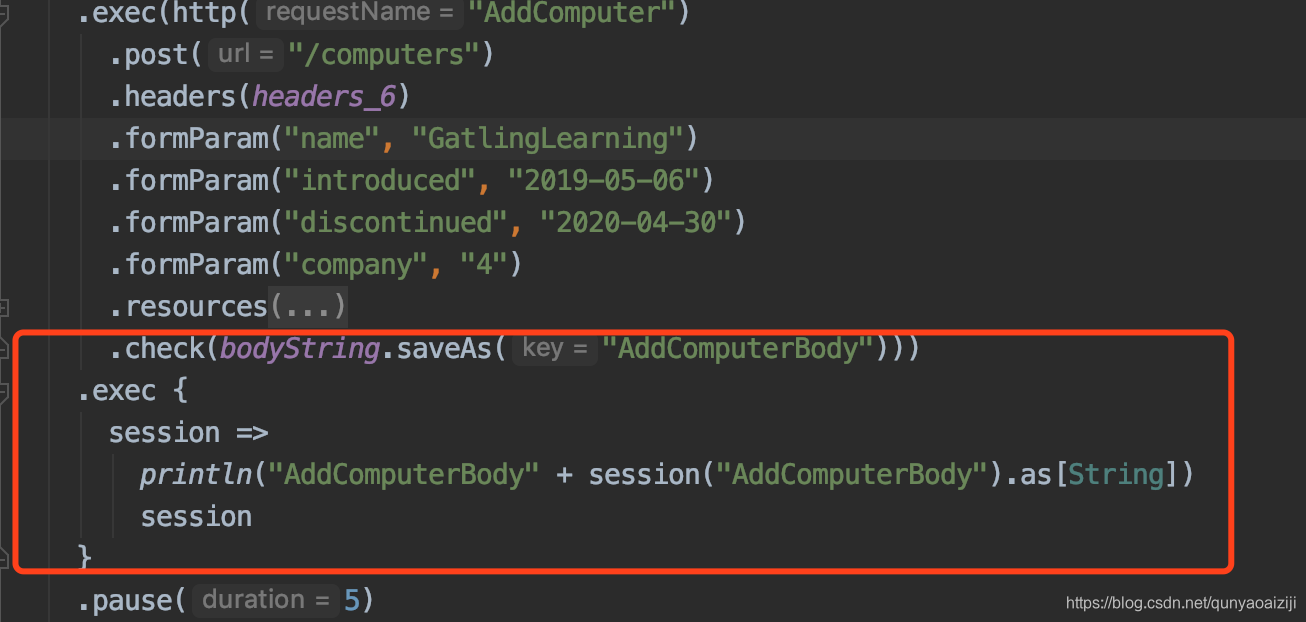
第二种方式就是打印session的方式,打印你需要的值。比如这里我们需要AddComputer的response body,那我们可以将其打印出来:
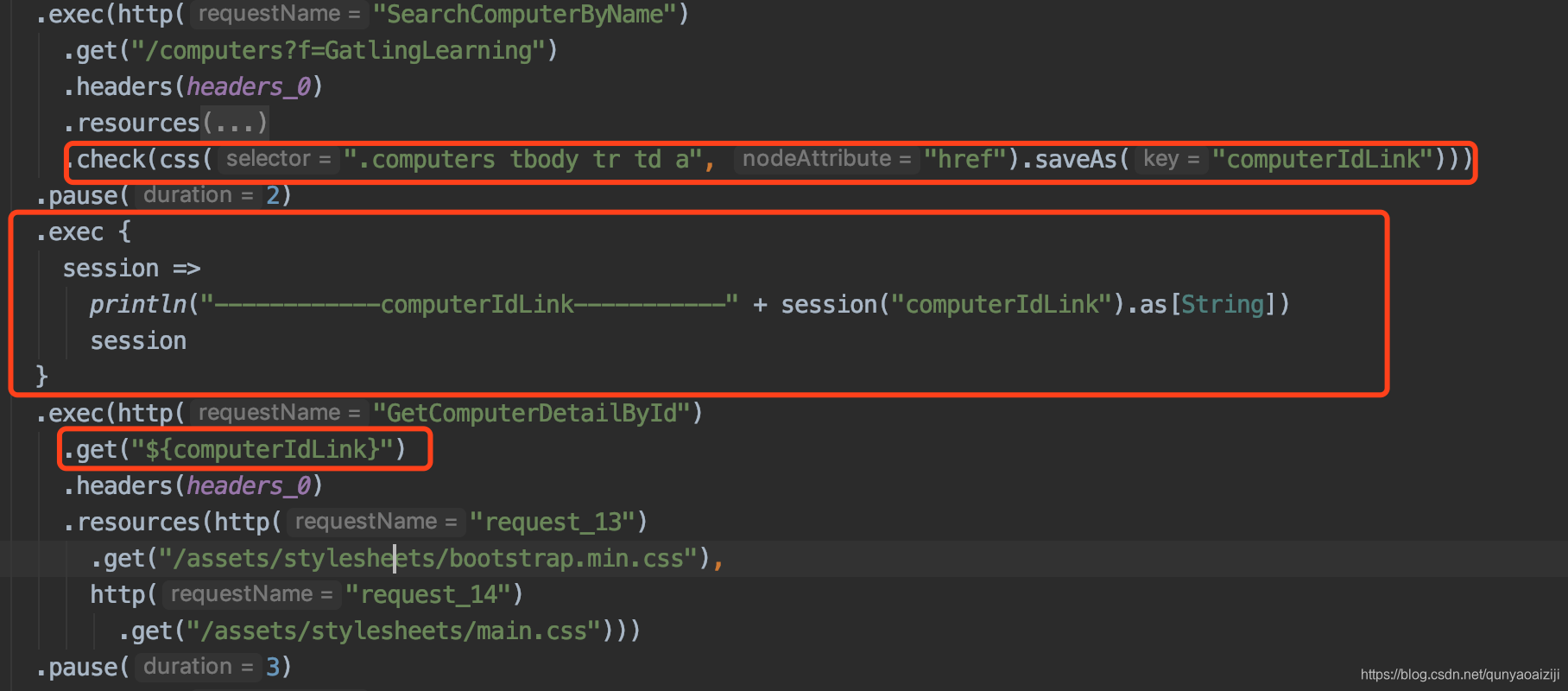
那我们这里需要的是将按名字搜索之后的id用于查看其details,所以应该获取SearchComputerByName的response中的ID。如下图所示:
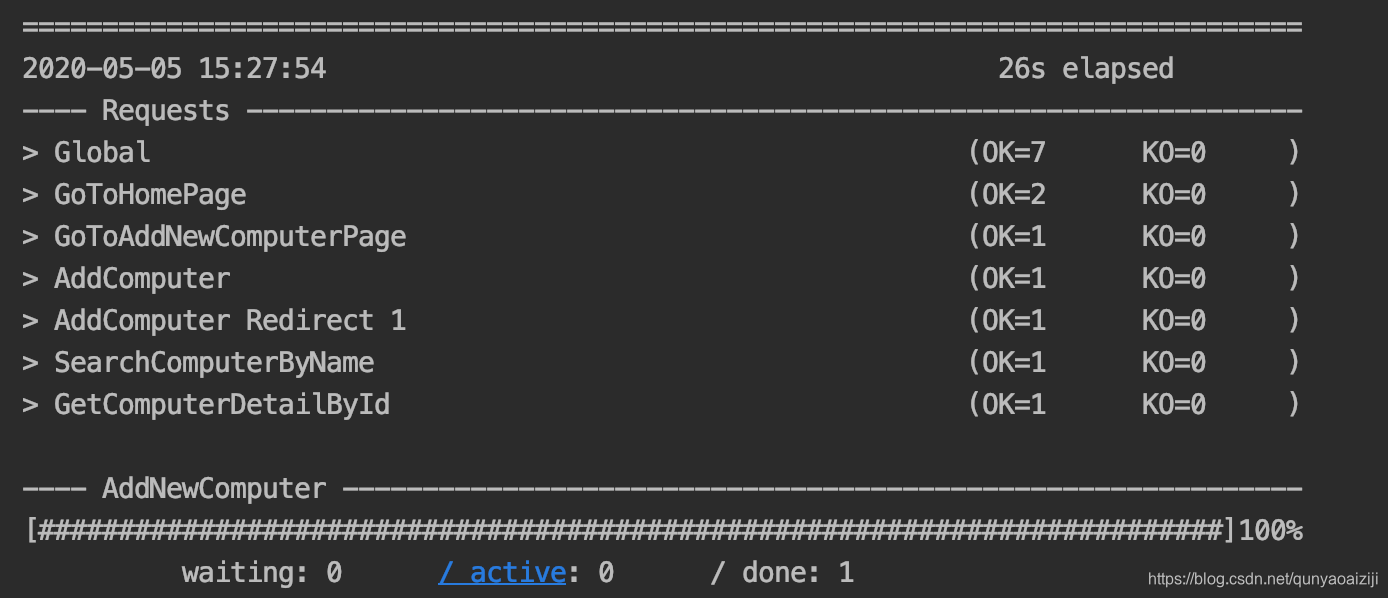
修改完成后,我们再运行该用例,已经可以运行成功了。
读取csv文件
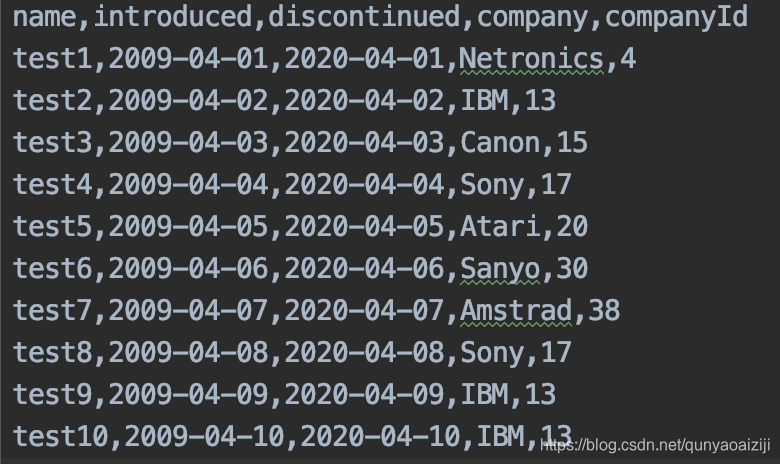
上面的测试用例我们使用的都是同一个测试数据,如果我们要模拟多个用户操作,使用的肯定是不同的测试数据,那么这个时候就需要我们准备不同的测试数据。我们可以使用csv文件管理测试数据,读取其中的数据。在这里我们准备名为computerInfo.csv的文件,内容如下:
读取csv文件模式有两种,一种是贪婪模式,一种是批处理模式。贪婪模式是指在运行测试前将所有的测试数据加载进内存,比较适合较小的文件操作。批处理模式是指加载部分或固定大小的数据进内存,使用完了再加载,比较适合读取大文件。Gatling默认的模式可在gatling.config中查看,参数是feederAdaptiveLoadModeThreshold=100,即在100M以内的文件采取贪婪模式,100M以上的数据采用批处理模式。这里我们采用默认模式,如何加载使用csv文件如下图:

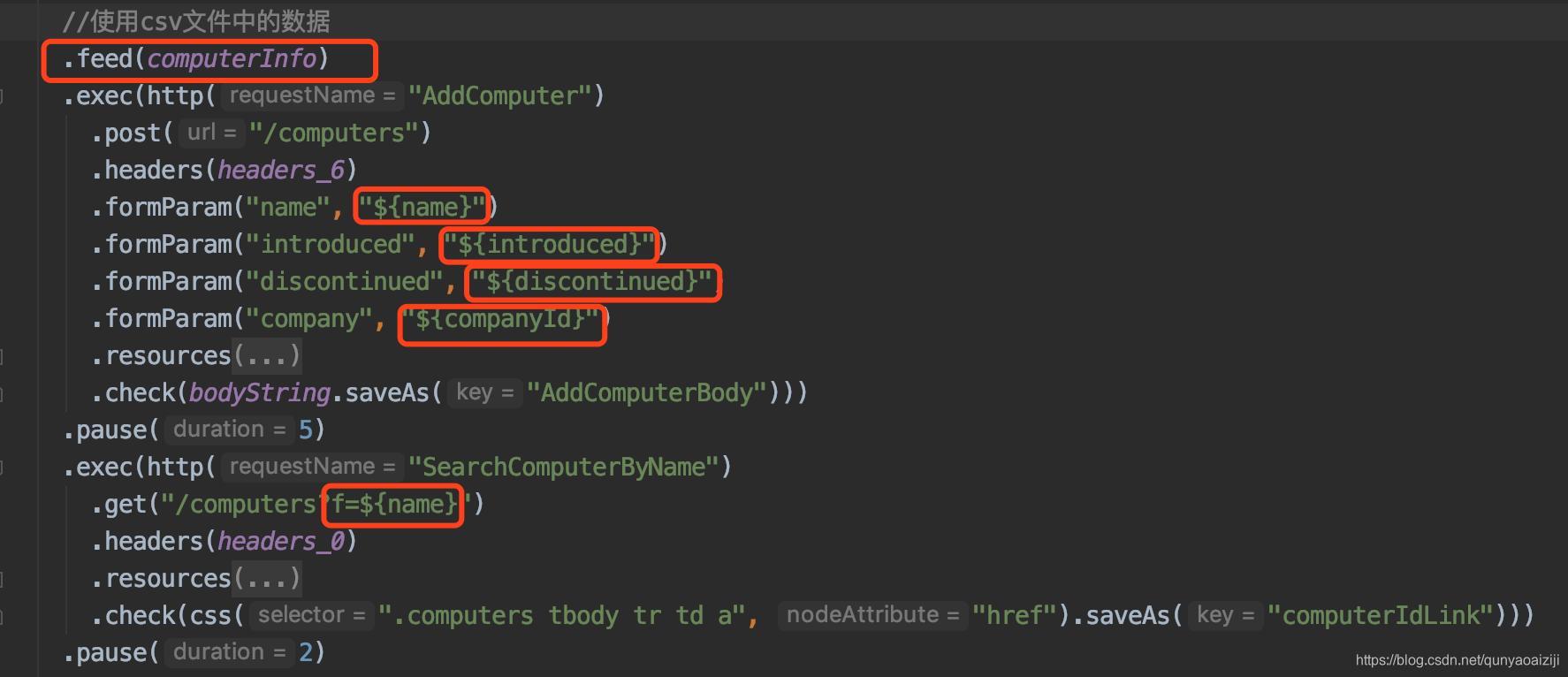
如果将用户设成2之后,重新运行用例可以看到成功添加了test1和test2。gatling读取文件有以下几种策略:
- .queue:顺序读取,也是默认策略
- .random :随机读取
- .shuffle :读取前先打乱顺序,然后再按序读取
- .circular :按序读取,读取完了之后再循环
可以在解析文件的时候的时候指定,我们这里使用默认的queue。

除了从csv文件读取数据外,gatling也支持读取压缩文件、json文件、tsv文件等,也支持数据库读取,具体可参考:https://gatling.io/docs/3.2/session/feeder
这一节的内容到此为止,下一节会讲述simulation setup的内容。