《FPGA并行编程》读书笔记(第一期)05_FFT
1. 绪论
当取样样本数量为N时,直接使用矩阵向量乘法来执行DFT需O(N^2)次乘法和加法操作,我们可以通过利用矩阵中的常数系数的结构来降低运算的复杂度。快速傅立叶变换(FFT)使用基于S矩阵对称性的分块处理方法,因Cooley-Tukey算法而广为流行,它需要O(nlogn)次操作来计算与DFT相同的函数。这可以在大规模信号执行傅立叶变换时提供显着的加速。
2. 读书笔记源说明
源代码见PP4FPGAS_Study_Notes_S1C05_HLS_FFT
3. 5个Solution带你学习FFT算法加速
3.1 工程组织结构

本节有5个Solution,来对1024点的FFT算法进行加速。因这个优化的自由度很大,最后小编仅仅做个例子来带大家学习加速的方法,而不是实现一个最优的算法。
3.2 S1_Baseline
根据FFT算法抽象出来的代码如下:
#include "math.h"
#include "fft.h"
#ifdef S1_baseline
unsigned int reverse_bits(unsigned int input) {
int i, rev = 0;
for (i = 0; i < M; i++) {
rev = (rev << 1) | (input & 1);
input = input >> 1;
}
return rev;
}
void bit_reverse(DTYPE X_R[SIZE], DTYPE X_I[SIZE]) {
unsigned int reversed;
unsigned int i;
DTYPE temp;
for (i = 0; i < SIZE; i++) {
reversed = reverse_bits(i); // Find the bit reversed index
if (i <= reversed) {
// Swap the real values
temp = X_R[i];
X_R[i] = X_R[reversed];
X_R[reversed] = temp;
// Swap the imaginary values
temp = X_I[i];
X_I[i] = X_I[reversed];
X_I[reversed] = temp;
}
}
}
void fft(DTYPE X_R[SIZE], DTYPE X_I[SIZE]) {
DTYPE temp_R; // temporary storage complex variable
DTYPE temp_I; // temporary storage complex variable
int i, j, k; // loop indexes
int i_lower; // Index of lower point in butterfly
int step, stage, DFTpts;
int numBF; // Butterfly Width
int N2 = SIZE2; // N2=N>>1
bit_reverse(X_R, X_I);
step = N2;
DTYPE a, e, c, s;
stage_loop:
for (stage = 1; stage <= M; stage++) { // Do M stages of butterflies
DFTpts = 1 << stage; // DFT = 2^stage = points in sub DFT
numBF = DFTpts / 2; // Butterfly WIDTHS in sub-DFT
k = 0;
e = -6.283185307178 / DFTpts;
a = 0.0;
// Perform butterflies for j-th stage
butterfly_loop:
for (j = 0; j < numBF; j++) {
#pragma HLS LOOP_TRIPCOUNT min=1 max=512
c = cos(a);
s = sin(a);
a = a + e;
// Compute butterflies that use same W**k
dft_loop:
for (i = j; i < SIZE; i += DFTpts) {
#pragma HLS LOOP_TRIPCOUNT min=1 max=512
i_lower = i + numBF; // index of lower point in butterfly
temp_R = X_R[i_lower] * c - X_I[i_lower] * s;
temp_I = X_I[i_lower] * c + X_R[i_lower] * s;
X_R[i_lower] = X_R[i] - temp_R;
X_I[i_lower] = X_I[i] - temp_I;
X_R[i] = X_R[i] + temp_R;
X_I[i] = X_I[i] + temp_I;
}
k += step;
}
step = step / 2;
}
}
#endif
首先要做的是进行仿真,验证代码的正确性。

算法正确后,再对算法进行C Synthesis,结果下图:

可以看出效率非常之低,接下来用我们的秘籍进行优化。
3.3 S2_Code_Restructured与S3_LUT
首先进行代码重构,将所有的循环进行展开,方便后面对每个循环进行单独优化(因每个循环边界不同,需要不同的优化方案).
以后因为代码太长仅贴出部分代码。
以后因为代码太长仅贴出部分代码。
以后因为代码太长仅贴出部分代码。
void fft_stage_1( DTYPE X_R[SIZE], DTYPE X_I[SIZE],
DTYPE Out_R[SIZE], DTYPE Out_I[SIZE]) {
int DFTpts = 1 << 1; // DFT = 2^stage = points in sub DFT
int numBF = DFTpts / 2; // Butterfly WIDTHS in sub-DFT
int step = SIZE >> 1;
DTYPE k = 0;
DTYPE e = -6.283185307178 / DFTpts;
DTYPE a = 0.0;
// Perform butterflies for j-th stage
butterfly_loop:
for (int j = 0; j < numBF; j++) {
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
DTYPE c = cos(a);
DTYPE s = sin(a);
a = a + e;
// Compute butterflies that use same W**k
dft_loop:
for (int i = j; i < SIZE; i += DFTpts) {
#pragma HLS LOOP_TRIPCOUNT min=512 max=512 avg=512
int i_lower = i + numBF; // index of lower point in butterfly
DTYPE temp_R = X_R[i_lower] * c - X_I[i_lower] * s;
DTYPE temp_I = X_I[i_lower] * c + X_R[i_lower] * s;
Out_R[i_lower] = X_R[i] - temp_R;
Out_I[i_lower] = X_I[i] - temp_I;
Out_R[i] = X_R[i] + temp_R;
Out_I[i] = X_I[i] + temp_I;
}
k += step;
}
}
void fft_stage_2( DTYPE X_R[SIZE], DTYPE X_I[SIZE],
DTYPE Out_R[SIZE], DTYPE Out_I[SIZE]) {
int DFTpts = 1 << 2; // DFT = 2^stage = points in sub DFT
int numBF = DFTpts / 2; // Butterfly WIDTHS in sub-DFT
int step = SIZE >> 2;
DTYPE k = 0;
DTYPE e = -6.283185307178 / DFTpts;
DTYPE a = 0.0;
// Perform butterflies for j-th stage
butterfly_loop:
for (int j = 0; j < numBF; j++) {
#pragma HLS LOOP_TRIPCOUNT min=2 max=2 avg=2
DTYPE c = cos(a);
DTYPE s = sin(a);
a = a + e;
// Compute butterflies that use same W**k
dft_loop:
for (int i = j; i < SIZE; i += DFTpts) {
#pragma HLS LOOP_TRIPCOUNT min=256 max=256 avg=256
int i_lower = i + numBF; // index of lower point in butterfly
DTYPE temp_R = X_R[i_lower] * c - X_I[i_lower] * s;
DTYPE temp_I = X_I[i_lower] * c + X_R[i_lower] * s;
Out_R[i_lower] = X_R[i] - temp_R;
Out_I[i_lower] = X_I[i] - temp_I;
Out_R[i] = X_R[i] + temp_R;
Out_I[i] = X_I[i] + temp_I;
}
k += step;
}
}
...
...
...
void fft(DTYPE X_R[SIZE], DTYPE X_I[SIZE], DTYPE OUT_R[SIZE], DTYPE OUT_I[SIZE]) {
DTYPE Stage1_R[SIZE], Stage1_I[SIZE];
DTYPE Stage2_R[SIZE], Stage2_I[SIZE];
DTYPE Stage3_R[SIZE], Stage3_I[SIZE];
DTYPE Stage4_R[SIZE], Stage4_I[SIZE];
DTYPE Stage5_R[SIZE], Stage5_I[SIZE];
DTYPE Stage6_R[SIZE], Stage6_I[SIZE];
DTYPE Stage7_R[SIZE], Stage7_I[SIZE];
DTYPE Stage8_R[SIZE], Stage8_I[SIZE];
DTYPE Stage9_R[SIZE], Stage9_I[SIZE];
DTYPE Stage10_R[SIZE], Stage10_I[SIZE];
bit_reverse(X_R, X_I, Stage1_R, Stage1_I);
fft_stage_1(Stage1_R, Stage1_I, Stage2_R, Stage2_I);
fft_stage_2(Stage2_R, Stage2_I, Stage3_R, Stage3_I);
fft_stage_3(Stage3_R, Stage3_I, Stage4_R, Stage4_I);
fft_stage_4(Stage4_R, Stage4_I, Stage5_R, Stage5_I);
fft_stage_5(Stage5_R, Stage5_I, Stage6_R, Stage6_I);
fft_stage_6(Stage6_R, Stage6_I, Stage7_R, Stage7_I);
fft_stage_7(Stage7_R, Stage7_I, Stage8_R, Stage8_I);
fft_stage_8(Stage8_R, Stage8_I, Stage9_R, Stage9_I);
fft_stage_9(Stage9_R, Stage9_I, Stage10_R, Stage10_I);
fft_stage_10(Stage10_R, Stage10_I, OUT_R, OUT_I);
}
C Synthesis的结果为:
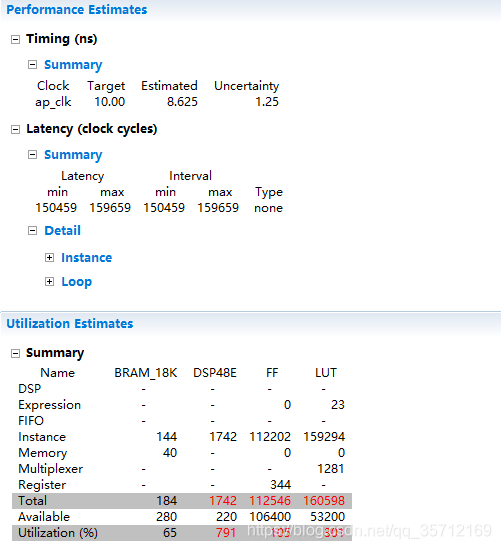
可以看出这个代码不是非常可行,因为展开了循环,所以资源占用率非常之高。首先对资源占用最高的sin、cos的计算利用查找表的方式进行实现(这里友情提醒下,进行代码重构后第一件事是必须进行C Simulation,因为代码重构极易出错)。部分代码如下:
void fft_stage_1( DTYPE X_R[SIZE], DTYPE X_I[SIZE],
DTYPE Out_R[SIZE], DTYPE Out_I[SIZE]) {
int stage = 1;
int DFTpts = 1 << stage; // DFT = 2^stage = points in sub DFT
int numBF = DFTpts / 2; // Butterfly WIDTHS in sub-DFT
int step = SIZE >> stage;
DTYPE k = 0;
DTYPE e = -6.283185307178 / DFTpts;
// Perform butterflies for j-th stage
butterfly_loop:
for (int j = 0; j < numBF; j++) {
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
DTYPE c = cos_coefficients_table[j<<(10-stage)];
DTYPE s = sin_coefficients_table[j<<(10-stage)];
// Compute butterflies that use same W**k
dft_loop:
for (int i = j; i < SIZE; i += DFTpts) {
#pragma HLS LOOP_TRIPCOUNT min=512 max=512 avg=512
int i_lower = i + numBF; // index of lower point in butterfly
DTYPE temp_R = X_R[i_lower] * c - X_I[i_lower] * s;
DTYPE temp_I = X_I[i_lower] * c + X_R[i_lower] * s;
Out_R[i_lower] = X_R[i] - temp_R;
Out_I[i_lower] = X_I[i] - temp_I;
Out_R[i] = X_R[i] + temp_R;
Out_I[i] = X_I[i] + temp_I;
}
k += step;
}
}
进行C Synthesis后的效果对比如下:

不仅延迟有少量提升,资源利用率还大幅优化。然后这还是远远不够的!!!后面会有更神奇的办法推出。
3.4 S4_DATAFLOW
DATAFLOW的官方解释见pragma HLS dataflow
下面简单说说我的理解:
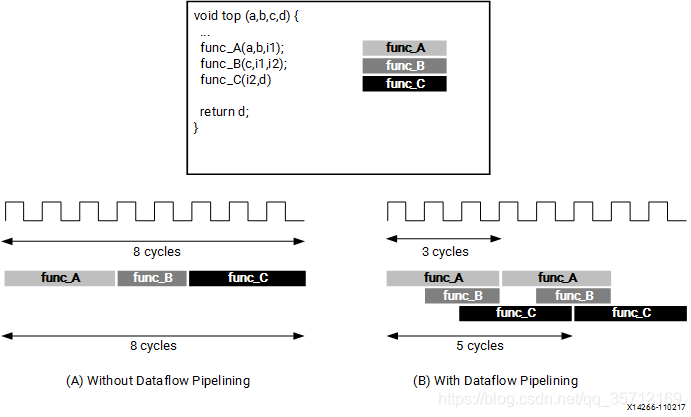
DATAFLOW优化可以在一个函数或循环的操作之前的函数或循环完成其所有操作之前就开始操作。与PIPELINE类似,可以结合PIPELINE进行理解。接下来我们来看看DATAFLOW的效果如何。首先部分源代码如下:
void fft(DTYPE X_R[SIZE], DTYPE X_I[SIZE], DTYPE OUT_R[SIZE], DTYPE OUT_I[SIZE]) {
#pragma HLS DATAFLOW
DTYPE Stage1_R[SIZE], Stage1_I[SIZE];
DTYPE Stage2_R[SIZE], Stage2_I[SIZE];
DTYPE Stage3_R[SIZE], Stage3_I[SIZE];
DTYPE Stage4_R[SIZE], Stage4_I[SIZE];
DTYPE Stage5_R[SIZE], Stage5_I[SIZE];
DTYPE Stage6_R[SIZE], Stage6_I[SIZE];
DTYPE Stage7_R[SIZE], Stage7_I[SIZE];
DTYPE Stage8_R[SIZE], Stage8_I[SIZE];
DTYPE Stage9_R[SIZE], Stage9_I[SIZE];
DTYPE Stage10_R[SIZE], Stage10_I[SIZE];
bit_reverse(X_R, X_I, Stage1_R, Stage1_I);
fft_stage_1(Stage1_R, Stage1_I, Stage2_R, Stage2_I);
fft_stage_2(Stage2_R, Stage2_I, Stage3_R, Stage3_I);
fft_stage_3(Stage3_R, Stage3_I, Stage4_R, Stage4_I);
fft_stage_4(Stage4_R, Stage4_I, Stage5_R, Stage5_I);
fft_stage_5(Stage5_R, Stage5_I, Stage6_R, Stage6_I);
fft_stage_6(Stage6_R, Stage6_I, Stage7_R, Stage7_I);
fft_stage_7(Stage7_R, Stage7_I, Stage8_R, Stage8_I);
fft_stage_8(Stage8_R, Stage8_I, Stage9_R, Stage9_I);
fft_stage_9(Stage9_R, Stage9_I, Stage10_R, Stage10_I);
fft_stage_10(Stage10_R, Stage10_I, OUT_R, OUT_I);
}
综合的结果如下:

Interval有一个数量级的飞跃,后面还可以继续优化提升。
大家在此一定要注意一个问题,我最初对这个代码使用DATAFLOW进行优化时,出现了一个致命的问题,小编当时花了一天才解决,下面简单说说这个问题的解决过程,希望可以给小伙伴们有点启发。
最初我加入DATAFLOW时出现了如下报错,每次都综合不成功,出现了如下报错。

很神奇的错误,Google了很多遍,都没有找到合适的解决方案。最后发现下图的log文件


根据这个log文件在Xilinx官方论坛找到了解决方案,Xilinx论坛说这个问题是版本的问题,解决办法是比较愚蠢的(去掉DATAFLOW就可以了),感觉这个解决方法就像fp(时间坐标为2019-8-15),没有啥意义。我当时又试了试我笔记本的另一个系统(ubuntu下的HLS),对同样的代码进行综合并没看有发现错误。现在是同一台机器、同一个HLS版本(2018.2)、同样的代码,却在不通的操作系统下出现如此的差异。这时候我就想到了一个问题,根据log文件的Stack提示联想到内存的堆栈,而且每块代码都需要一定的内存进行计算

DATAFLOW本身是不会有问题的,有问题的是内存的分配,对那么多函数运用DATAFLOW,导致Windows下的内存分配出现溢出之类的问题,而在Linux系统下,由于对内存的管理比较好,所以没有出现问题。上面仅仅是小编的猜想,具体还摸不清楚原因,大家看看就好。
3.5 S5_Effect_Improve
然后大家对每块代码都进行个性的优化,部分代码如下。
void fft_stage_1( DTYPE X_R[SIZE], DTYPE X_I[SIZE],
DTYPE Out_R[SIZE], DTYPE Out_I[SIZE]) {
int stage = 1;
int DFTpts = 1 << stage; // DFT = 2^stage = points in sub DFT
int numBF = DFTpts / 2; // Butterfly WIDTHS in sub-DFT
DTYPE e = -6.283185307178 / DFTpts;
// Perform butterflies for j-th stage
butterfly_loop:
for (int j = 0; j < numBF; j++) {
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
// Compute butterflies that use same W**k
dft_loop:
for (int i = j; i < SIZE; i += DFTpts) {
#pragma HLS PIPELINE II=6
#pragma HLS LOOP_TRIPCOUNT min=512 max=512 avg=512
DTYPE c = cos_coefficients_table[j<<(10-stage)];
DTYPE s = sin_coefficients_table[j<<(10-stage)];
int i_lower = i + numBF; // index of lower point in butterfly
DTYPE temp_R = X_R[i_lower] * c - X_I[i_lower] * s;
DTYPE temp_I = X_I[i_lower] * c + X_R[i_lower] * s;
Out_R[i_lower] = X_R[i] - temp_R;
Out_I[i_lower] = X_I[i] - temp_I;
Out_R[i] = X_R[i] + temp_R;
Out_I[i] = X_I[i] + temp_I;
}
}
}
void fft_stage_2( DTYPE X_R[SIZE], DTYPE X_I[SIZE],
DTYPE Out_R[SIZE], DTYPE Out_I[SIZE]) {
int stage = 2;
int DFTpts = 1 << stage; // DFT = 2^stage = points in sub DFT
int numBF = DFTpts / 2; // Butterfly WIDTHS in sub-DFT
DTYPE e = -6.283185307178 / DFTpts;
// Perform butterflies for j-th stage
butterfly_loop:
for (int j = 0; j < numBF; j++) {
#pragma HLS LOOP_TRIPCOUNT min=2 max=2 avg=2
// Compute butterflies that use same W**k
dft_loop:
for (int i = j; i < SIZE; i += DFTpts) {
#pragma HLS PIPELINE II=6
#pragma HLS LOOP_TRIPCOUNT min=256 max=256 avg=256
DTYPE c = cos_coefficients_table[j<<(10-stage)];
DTYPE s = sin_coefficients_table[j<<(10-stage)];
int i_lower = i + numBF; // index of lower point in butterfly
DTYPE temp_R = X_R[i_lower] * c - X_I[i_lower] * s;
DTYPE temp_I = X_I[i_lower] * c + X_R[i_lower] * s;
Out_R[i_lower] = X_R[i] - temp_R;
Out_I[i_lower] = X_I[i] - temp_I;
Out_R[i] = X_R[i] + temp_R;
Out_I[i] = X_I[i] + temp_I;
}
}
}
根据对比报告可以看出

在资源占用大幅减少的情况下,Interval也优化了将近一个数量级。上面代码仅仅是小编随便进行优化的,大家要想实用这些代码需要亲自动手优化。
4. 结论
上一章节我们进行了256点的DFT,大家可以修改进行下1024点的DFT,对比Interval,会发现相差将近3个数量级,FFT使得数字信号的傅里叶计算成为可能。
快速傅里叶变换广泛的应用于工程、科学和数学领域。这里的基本思想在1965年才得到普及,但早在1805年就已推导出来。1994年美国数学家吉尔伯特·斯特朗把FFT描述为“我们一生中最重要的数值算法”,它还被IEEE科学与工程计算期刊列入20世纪十大算法。
原创不易,切勿剽窃!

欢迎大家关注我创建的微信公众号——小白仓库
原创经验资料分享:包含但不仅限于FPGA、ARM、RISC-V、Linux、LabVIEW等软硬件开发。目的是建立一个平台记录学习过的知识,并分享出来自认为有用的与感兴趣的道友相互交流进步。