第一章:绪论
1:基础概念
数据集:100个西瓜 样本:1个西瓜 特征向量:颜色,大小,响度 属性:颜色
样本(样例):数据的特定实例,为xn,分为有标签样本和无标签样本,
有标签样本包含特征和标签,无标签包含特征,不包含标签
标签:要预测的事务,为y
特征:输入变量,为x
机器学习:机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。旨在准确的预测
机器学习的一般步骤:搜集数据,数据预处理,选择模型,训练模型,评估模型,参数微调,预测
样本属性的主要类型:连续性,二值离散,多值离散,混合类型
奥卡姆剃刀:选择简单的那个
没有免费的午餐定理(NFL定理):无论学习算法a多聪明、学习算法b多笨拙,它们的期望性能都相同。
2:分类
有监督学习
分类:二分类为题(瓜栽还是不摘)多分类(市场上有哪些瓜)
回归:预测下年西瓜啥时间是最便宜的
无监督学习
聚类:大小
区别:有监督学习有老师教,无监督学习没有老师教,有监督学习通过已有的训练样本得到模型,在利用模型将所有输入映射为相应输出。无监督学习没有任何训练样本,而是直接对数据进行建模。聚类。
第二章:模型评估
随着训练样本的增加,平均训练误差会增大,平均测试误差会减小
1:评估方法
2:评估指标
准确率
错误率
查准率(P)
查全率(R)
调和均值F1
PR曲线:
比较集中曲线的好坏:
方法一:查全率相同,查准率高的好
方法二:比较面积
ROC曲线:
ROC曲线判断好坏:
越凸越好
AUC
CLL
3:比较检验
测试集的保留方法
留出法(部分数据用来训练,部分数据用来预测,三七分)
交叉验证法:K折交叉验证
自助法:
验证集:调参
性能度量:
均方误差
错误路与精度
查准率和查全率:(样本分布不均衡,使用错误率不准确了)
第三章:线性模型
1:线性回归
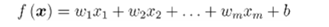
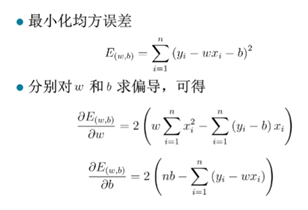
使用最小二乘法对w和b进行评估


2:广义线性回归
现实中很多问题是非线性的,将线性回归的预测值做一个非线性的函数变化去逼近真实值
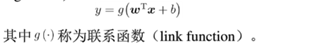
联系函数为指数函数式,成为对数线性回归
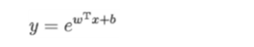
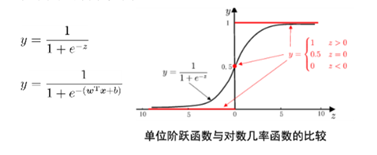
3:逻辑斯蒂回归—二分类问题

4:多分类学习

第四章:支持向量机
1:概念
确定一个分类超平面,从而将不同的数据分割开
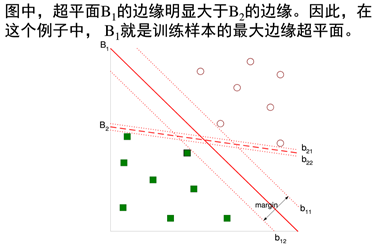

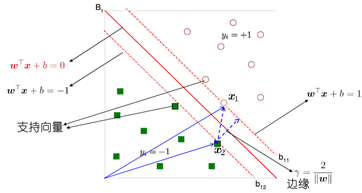

使用现成的或则拉格朗日乘子法
2:分类
线性可分支持向量机
线性支持向量机
非线性支持向量机
3:核函数
将非线性转化为线性问题
一般由经验给出
正定核——正定矩阵
多项式核函数
高斯核函数
第五章:神经网络
MP神经元模型

单层感知机
只拥有一层MP神经元

多层前馈神经网络
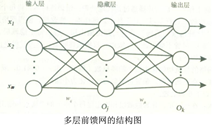
误差逆传播算法(BP)

BP面临的问题
1) 结构学习问题
2) 初始化问题
3) 步长设置问题
4) 权值与阈值的更新问题
5) 过拟合问题
深层神经网络
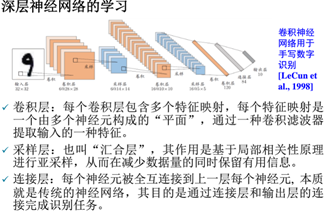
第六章:决策树学习
根据某些特征的判别对数据进行分类
最佳划分的度量问题
不纯度量
增益率
C4.5的启发式方法
例:根据天气,温度等划分决策树
计算各信息增益,最大的是OutLook,根据OutLook划分
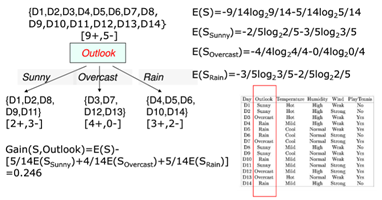
判断Sunny有2+和3-不是叶子节点,再划分,计算其他的信息增益,发现Humidity最大,
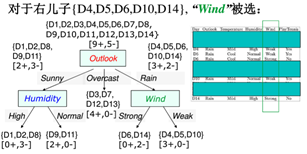
处理缺失属性问题

过拟合
预剪枝
后剪枝(实践中更直接)
第七章:贝叶斯
贝叶斯定理:
朴素贝叶斯定理:假设输入的不同特征之间是独立的。
应用:文本分类,垃圾邮件过滤,病人分类,拼音检查
极大似然估计MLE:模型已定,参数未知,
最大后验概率MAP:获得对实验数据中无法直接观察到的量的点估计。MAP就是多个作为因子的先验概率P(θ)。或者,也可以反过来,认为MLE是把先验概率P(θ)认为等于1,即认为θ是均匀分布。
因为MLE 只考虑训练数据拟合程度没有考虑先验知识,把错误点也加入模型中,导致过拟合。
基础知识

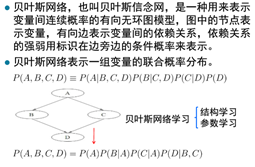
朴素贝叶斯分类器
条件独立
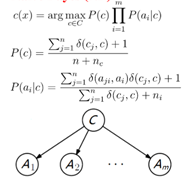
例:天气等

改进
1) 处理算法:结构扩展
2) 处理数据:
面向特征(特征选择,特征加权)
面向实例(实例选择,实例加权)
第八章:最近邻学习kNN
积极学习:有显式的训练过程,都是在训练阶段对样本进行学习处理,构建分类模型
消极学习(lazy learning):没有显式训练过程,训练阶段只是把训练样本保存起来,建模工作
延迟到工作阶段才进行处理,如最近邻学习

近邻索引问题
几乎所有计算花费都在索引近邻上,使用最多的是通过计算待测样本与每一个训练样本之间的距离,然后基于距离排序,选择距离最短的k个训练样本作为待测赝本。

维度灾害问题
如果目标函数仅依赖于很多属性中的几个时,样本间的距离会被大量不相关的属性所支配,从而导致相关属性的值很接近的样本相距很远。
解决方案:属性加权,属性选择(加权为0和1)
领域大小问题
基于经验直接给出,基于数据自动学习
后验概率问题
计算效率问题
归纳偏置问题’
第八章:集成学习
构件并结合多个学习期来完成学习任务,有时又称多分类器系统。先产生一组个体学习器,再用某种策略将他们结合起来。
个体强依赖必须串行生成序列——Boosting
个体不强依赖可并行化——bagging和随机森林
Boosting
Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
AdaBoost
AdaBoosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)分类器更加关注分错的样本点
GBDT
回归树,梯度上升决策树,核心在于累加所有树的结果,一个人是30岁,先用20岁去拟合,然后发现损失有10岁,再用6岁去拟合剩下的损失,发现差距还有4岁,继续迭代,拟合的岁数的误差就会越来越小,不断拟合残差
Bagging与随机森林(RF)
Bgging:在原始数据集中有放回的选取,均匀取样,
第九章:聚类
距离计算
明科夫斯基距离(曼哈顿距离和欧式距离)
K均值算法(kmeans)
学习向量量化
高斯混合聚类:采用概率模型来表达
基于密度的聚类
层次聚类
k-means:K是指所要聚的cluster的数量,means是指每一个cluster都有一个中心点(质心),这个质心是cluster中所有点的平均值,分别计算样本中每个点与K个质心的欧式距离,离哪个质心最近,这个点就被划到哪一类中。继续选出新的质心,如果新的质心与旧的质心的差距小于一定得阈值,则不再更新。
GMM(高斯混合模型):所有的分布可以看做是多个高斯(正态)分布综合起来的结果。这样一来,任何分布都可以分成多个高斯分布来表示。通过样本找到K个高斯分布的期望和方差,那么K个高斯模型就确定了。在聚类的过程中,不会明确的指定一个样本属于哪一类,而是计算这个样本在某个分布中的可能性。
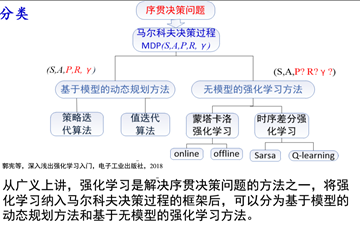
第十章:强化学习