1. 纠错码
1)理想的传输模型示例:
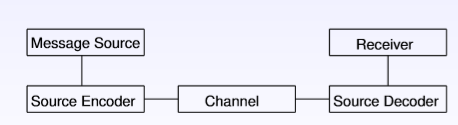
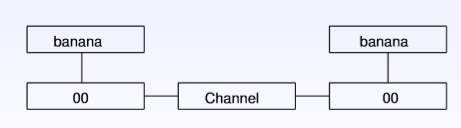
2)实际的传输模型为:


3)带纠错功能的传输模型为:
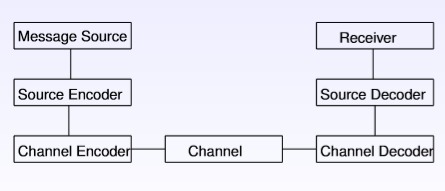
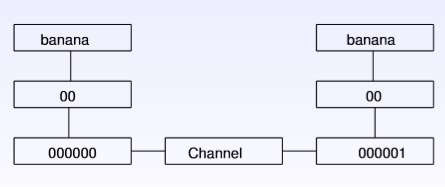
纠错码(error correcting code),在传输过程中发生错误后能在收端自行发现或纠正的码。纠错码常用于保证信息在noisy channel的可靠传输以及保证信息在媒介上的可靠存储(可能会随着时间partially corrupted或者说相应的reading device is subject to errors)。
仅用来发现错误的码一般常称为检错码。检错码与其他手段结合使用,可以纠错。
为使一种码具有检错或纠错能力,须对原码字增加多余的码元,以扩大码字之间的差别 ,即把原码字按某种规则变成有一定剩余度(见信源编码)的码字,并使每个码字的码之间有一定的关系。关系的建立称为编码。码字到达收端后,可以根据编码规则是否满足以判定有无错误。当不能满足时,按一定规则确定错误所在位置并予以纠正。纠错并恢复原码字的过程称为译码。
纠错码的典型应用是:将message切分为小的blocks,每个block单独编码,当只对某部分信息感兴趣时,可仅解码相应的部分即可。这种策略的优点是:可保证random-access retrieval of information的效率。缺点是:抗噪能力比较弱,哪怕仅有一个block completely corrupted了,相应的信息也就完全丢失了。
提高抗噪能力的一种办法是:对整个message使用纠错码进行编码(encode the whole message into a single codeword of an error-correcting code)。这种策略抗噪能力是增强了,但是当某人仅对某一部分信息感兴趣时,也需要恢复整个message。当面对的是现代的大数据集时,对应的解码复杂度也是令人难以接受的。
1.1 线性纠错码Linear code

其中的
为the dimension of the code,
为the block length of the code。Linear code需要用
个符号来传递
长的message,相应的效率
。


A linear code of length
, dimension
,and minimum distance
will be called an
code. 其中
。
最小距离
与可correct errors的关系为:

maximum likelihood decoding: 最大释然解码。
nearest neighbor decoding:最近邻解码。
由于error vector
未知,在实际解码时,若
值小,可采用暴力解码的方式将received vector
与
个可能的
对比,找到最接近的值。但是当
值很大时,暴力解码就不实用了。
1.2 nonlinear code

其中的
可表示为
。
线性与非线性code的表示方法是有差异的。用圆括号()表示的code可为linear或nonlinear,而用中括号[]表示的就是linear code。
linear code
也可表示为
。
在相同的
的情况下,若希望最终编码的数量
尽可能多,可以用nonlinear code。
常见的nonlinear code有Hadamard code
1.2.1 Hadamard code
Hadamard matrix定义如下:
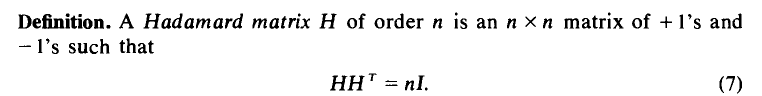

Normalized Hadamard matric如:

若a Hadamard matrix
of order
exists, then
is 1, 2 or a multiple of 4.

经典的Hadmard code是将
-bit messages编码为
-bit codewords。
由此可知,Hadmard code的query complexity为2,codeword length exponential in the message length.

的译码流程为:

为2-query
-LDC,证明如下:


上图中的译码过程,会恢复出所有的原码。当仅需要恢复一个原码而不是完整的所有原码时,---->于是有了LDC(Locally Decodable Code)。
2. LDC
Locally DECODABLE CODE是纠错码的一种,LDC既满足了抗噪性的要求,同时也能提供高效的random-access retrieval。(
allowing reliablereconstruction of an arbitrary bit of the message from looking at only a small number of randomly chosen codeword bits)
LDC牺牲了码字效率,需要更长的码字长度。

LDC不仅可用于可靠传输和可靠存储,还可用于其它领域,如:cryptography, complexity theory, data structures, derandomization, and the theory of fault tolerant computation.
Locally decodable codes can be seen as the combinatorial analogs of self-correctors [70, 21] that have been studied in complexity theory in the late 1980s. LDCs were also explicitly discussed in the PCP literature in early 1990s, most notably in [6, 88, 80]. However the fifirst formal defifinition of LDCs was given only in 2000 by Katz and Trevisan [64]. See also Sudan et al. [90]. Since then the study of LDCs has grown into a fairly broad fifield.
2.1 LDC定义
LDC的具体定义如下:

根据以上定义可知,对于
-bit长的message,编码后为
进制字母表的情况,我们希望
的值越小越好,而
值越大越好。当然,根据不同的应用场景,这些参数的取舍会不同,如在可靠传输和可靠存储应用中,会希望
值越大越好(对于二进制,通常希望该值接近
),
值越小越好,相对来说
即可(可通过多运行几次
解码流程并根据大多数结果来选举正确的结果,准确率可提升至
);而在密码学应用中,择更关注
和
的平衡。
A -query locally decodable code encodes -bit messages in such a way that one can probabilistically recover any bit of the message by querying only bits of the (possibly corrupted) codeword , where can be as small as 2.
在LDC中,需要关注的参数主要有:codeword length以及query complexity。如何在codeword length和query complexity之间做取舍平衡,是当前LDC研究领域的热点。
- The length of the code measures the amount of redundancy that is introduced into the message by the encoder.
- The query complexity counts the number of bits that need to be read from the (corrupted) codeword in order to recover a single bit of the message.
2.2 Smooth LDC定义

根据queries的次数(query complexity)和codeword length(upper bounds和lower bounds),当前的研究成果主要有:

2.3 LDC的技术分类
根据LDC的底层技术实现发展,可以分为三个阶段:
- 第一代LDC:多项式插值。capture codes that are based on the idea of polynomial interpolation。其编码实现为:将messages通过有限域内的多变量低阶多项式evaluation。典型代表为Reed-Muller(RM) LDC。当message length为
,query complexity
时,RM LDC的codeword length为
。

- 第二代LDC:多项式插值+递归。第二代LDC的构建是非直接的,分为两步:1)one obtains certain cryptographic protocols called Private Information Retrieval schemes, or PIRs, that on their own, are objects of interest. 2)one turns PIRs into LDCs. 第二代的LDC可以承受一定比例的错误。当message length为
,query complexity
时,第二代LDC的codeword length为
。

- 第三代LDC:代数组合思想。典型代表为Matching Vector(MV) LDC。MV codes可设计为最优的容错率(如,字母表
的错误率,以及二进制表
的错误率)。

2.3.1 第一代LDC——Reed-Muller LDC
Reed-Muller(RM) LDC主要由三个参数决定:
- a prime power (alphabet size) ;
- number of variables ;
- a degree 。
【A -evaluation of a function defined over a domain , is a vector of values of at all points of ;】
RM LDC的
进制编码结果由以下内容组成:
在ring
内,对
内的所有点在所有多项式(多项式的阶之和不超过
)的evaluation值组成。
RM LDC可将 长的消息编码为 长的码字。
3. LDC vs PIR(私有信息检索)

参考资料:
[1] https://baike.baidu.com/item/纠错码/2277072?fromtitle=error%20correcting%20code&fromid=11311379&fr=aladdin
[2] 上海交大ppt Introduction to Coding Theory
[3] 微软的研究报告Locally Decodable Codes
[4] 1977年书本《The Theory of Error-Correcting Codes》 by F. J. MacWilliams, N. J. A. Sloane (z-lib.org)