深度解读:小米AI实验室AutoML团队最新成果FairNAS
作者丨子安
学校丨意大利特伦托大学硕士
研究方向丨自动化神经架构搜索
如今的深度学习界,自动化神经架构搜索 (Neural Architecture Search) 正风起云涌,相信不久手工设计将成为历史。刚刚过去的 CVPR 2019 上,标题含有 architecture search 字眼的就有 10 篇,比如 Google Brain 的 MnasNet,NAS-FPN,李飞飞团队 Auto-DeepLab,Facebook 的 FbNet 等,国内也有像中科院和地平线合作的 RENAS、UISEE 的 Partial Order Pruning 等。
由于 NAS 技术的不断革新,目前最新成果已经可以直接在手机端和 IoT 端落地,NAS 对于深度学习工业界产生的影响将是革命性的,并且意义深远。
分类是绝大多数可监督视觉任务的基础,比如分割和检测都用分类的网络做骨干网。正因如此,NAS 界即从 CIFAR-10 开始,目前大家主攻 ImageNet,在各个模型量级不断推陈出新,在分割和检测任务上亦有不俗的斩获 (Auto-DeepLab, NAS-FPN)。
近日,小米 AI 实验室 AutoML 团队刚刚公布了最新研究成果 FairNAS,主打的 ImageNet 1k 分类任务在 MobileNetV2 这个量级已经击败 MIT 韩松团队的 Proxyless mobile (ICLR2019), Google Brain 的 MnasNet(CVPR 2019) 及 Facebook 的 FBNet (CVPR 2019),是目前最新 SOTA,该团队第一时间也附上了模型及验证代码。

论文链接:PaperWeekly
源码链接:fairnas/FairNAS
FairNAS 的方法是对 NAS 界 One-Shot 派的继承和发扬。One-Shot 派由 Google Brain 创立,主张权重可共享,从头到尾训练一个超网 (只完整训练一个超网,这也是 One-shot 的命名之义),每个模型是超网的一次采样子模型。这样做的好处是不需要将每个模型进行耗时的训练才知道其表征能力,因此以大幅提升 NAS 的效率著称,目前已成为 NAS 的主流。
但 One-Shot 的前提是假定权重共享是有效的,并且模型能力能够通过这种方式快速及准确的验证。要评估模型能力,就好像给一个班的同学考一场试,用明确的考分来决定谁学习不错,谁学习还薄弱一些,虽然不能完全展示每个学生的能力和优势,但总得需要放在同一个尺度上考量。
目前 NAS 评定模型能力的方式,就好比给各个模型一道相同的考题,考的好的就是好模型,不好的就是差模型。但往往有情况是差模型底子并不差,只是训练不得当,所以结果比较差。或者训练不充分,结果比较差。
这种情况就有点像马太效应,家庭条件好的一代比一代强,条件不好的反而陷入循环困境。所以在训练过程中,给予相同的机会和条件来提升其能力是很重要的。这也是小米 AI 实验室 AutoML 团队提出 FairNAS 的核心之处。这一点是被过去的研究有所忽略的。
FairNAS 认为,公平的采样方式和训练方法可以发挥各组成模块的潜能,最终超网训练完成后,采样所得模型可以快速使用超网中的权重在验证集上得到比较稳定的性能指标,这一过程好比一群孩子给予了相同条件的集体培养,多年以后他们显现出的不同就是其真正的天分和努力。这个公平的算法几乎能完全保持模型的排序,从超网采样的模型和单独训练的模型最终有近乎完全一样的排名。
具体来讲,怎么才能保证公平呢?FairNAS 提出了要满足 Strict Fairness,这个约束条件是超网的每单次迭代让每一层可选择运算模块的参数都要得到训练。
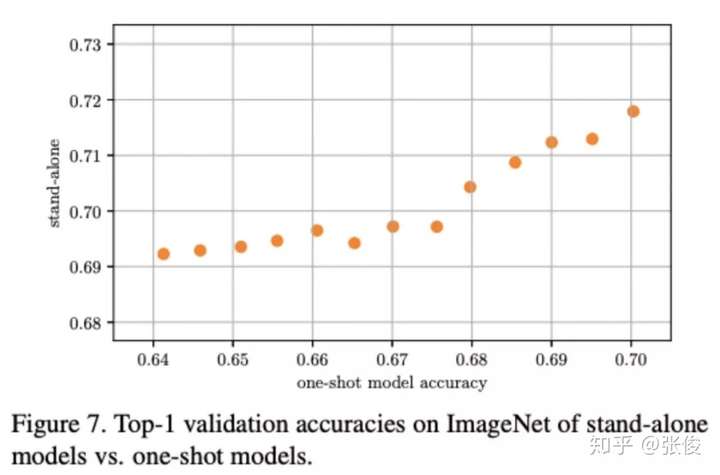
从这个定义来看,目前包括 Google 的 One-shot ,MIT 韩松的 Proxyless,旷视的 Single Path One-Shot (SPOS) 都没有满足。从结果来看,Google 的 one-shot 分布域(相当于集体培养后的)比较分散,而 stand-alone 分布域(相当于单独培养的)比较集中,这里的问题是集体培养后表现低,而如果单独培养也并不会很差。所以有可能是培养过程中有所侧重,导致了有些得到了重点培养,而有些被遗忘了。
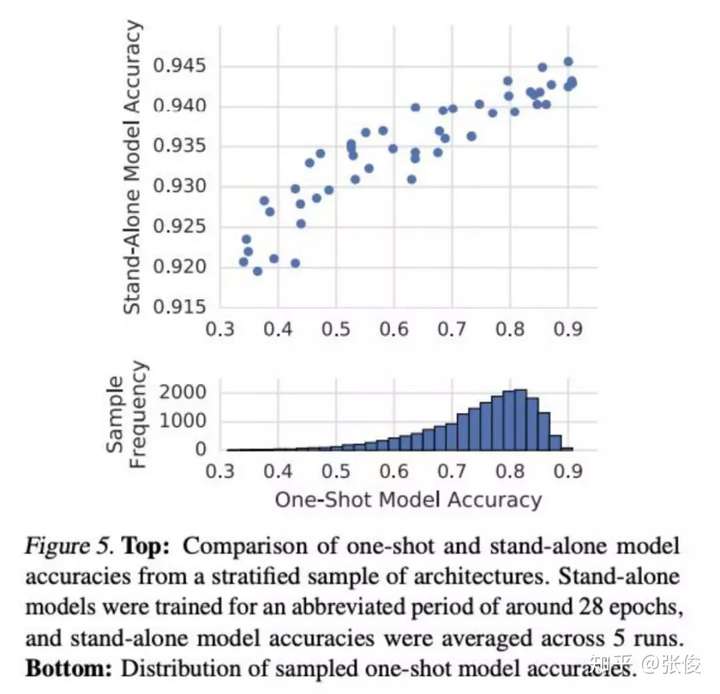 ▲ 谷歌 One-shot 与 Stand-alone 分布对比
▲ 谷歌 One-shot 与 Stand-alone 分布对比
原作 Bender 等用对称 KL 散度来解释其相关性,但也不无迟疑地发问:为何二者相差这么大呢?

他们认为训练超网会让其更聚焦有用的运算模块,而对没那么重要的进行舍弃。这一点上,FairNAS 并没有采取这个策略,而是让每个运算模块都得到充分训练,这样最终采样模型的每个运算单元均可表现其真实能力。
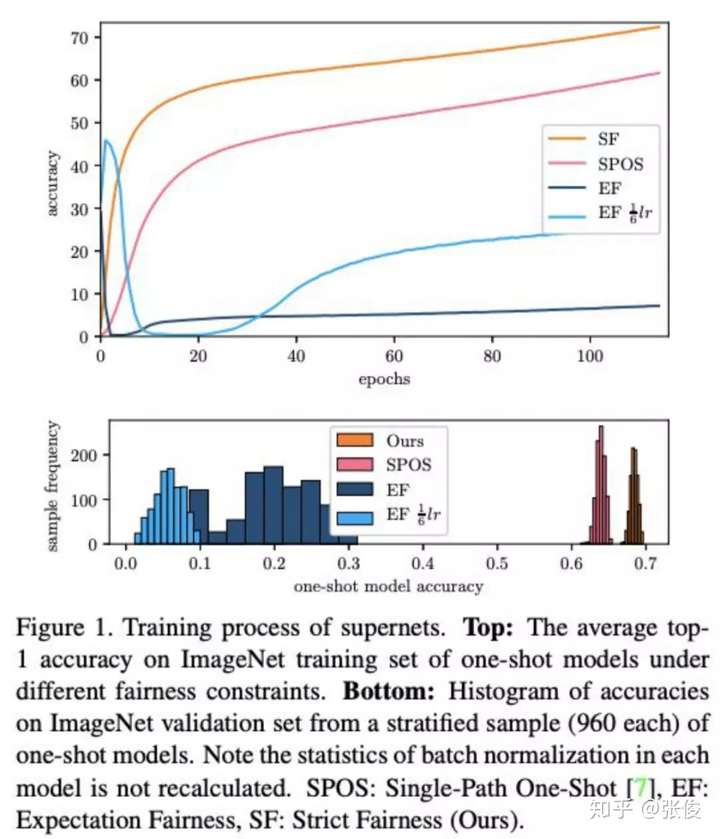 ▲ FairNAS 超网训练过程和one-shot 采样分布
▲ FairNAS 超网训练过程和one-shot 采样分布
从图中可以看出,FairNAS 的 one-shot 采样模型普遍水平均要高出旷视的 SPOS,这应该是得益于更公平的训练和采样方式。Supernet 的平均训练精度也是稳步地高出 SPOS。
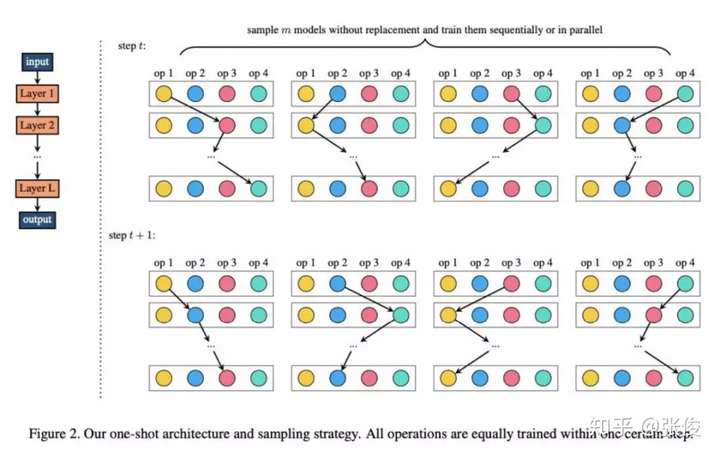
FairNAS 与 SPOS 的均匀采样不同,采取了不放回采样方式和多步训练一次参数更新的方式,这个改动带来了one-shot 分布和 supernet 训练的整体提升。
FairNAS 发现,尽管均匀采样看上去很诱人,但只是满足了论文定义的期望公平 (Expectation Fairness, EF),直觉上的公平在实际 20 次迭代以后已经丧失殆尽,论文给出了引理 1 中满足 EF 但同一层两个计算模块被公平选择的概率最终为 0 的证明。
FairNAS 的训练和采样算法如下:

此外,为了继承之前的工作,小米 AI 实验室 AutoML 团队将如此训练的 Supernet 作为其年初工作 MoreMNAS 的评估器,从而在此基础上进行结合强化和演化的多目标优化搜索过程,并给出了多组消去实验,证明要比纯 RL 或 EA 要优越。
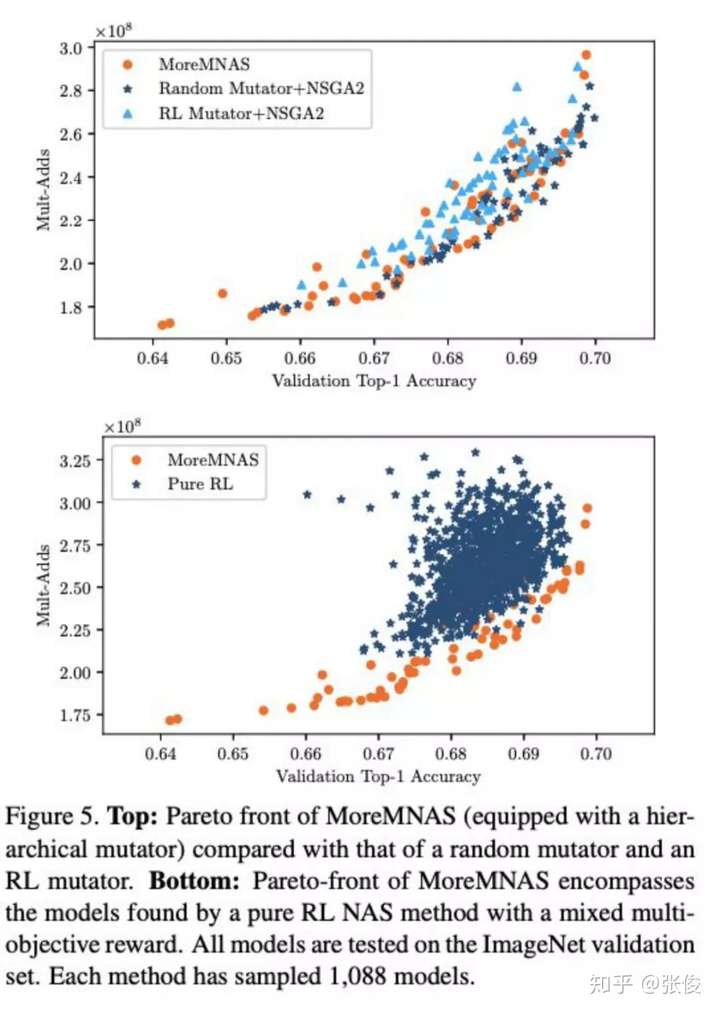
在搜索过程完成后,FairNAS 单独从头训练的 stand-alone 模型和 one-shot 采样得到的模型排序相对稳定,用 Kendall Tau 这个指标算得是 0.9487。这个指标在 Google 的 One-shot 和旷视 SPOS 中并未有呈现。
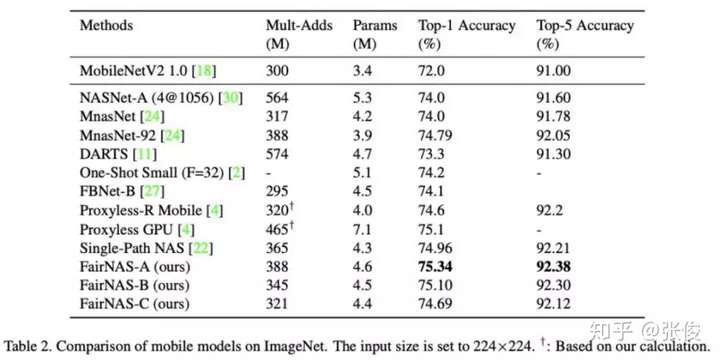
FairNAS 最后给出了与当前 NAS SOTA 方法模型的对比,在 MobilenetV2 这个量级已经达到当前最好水平。
可喜的是,AutoML 团队也给出了预训练和搭建模型,以分类任务为基础的视觉任务均可以受益。未来希望小米 AI 实验室的 AutoML 团队可以给我们带来更多的惊喜。
参考文献
[1] FairNAS论文: FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search, https://arxiv.org/pdf/1907.01845.pdf
[2] FairNAS开源模型地址: https://github.com/fairnas/FairNAS
[3] Chu et al., MoreMNAS: Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search, https://arxiv.org/abs/1901.01074
[4] CVPR 2019 接收论文列表: http://cvpr2019.thecvf.com/program/main_conference
[5] George Adam, Jonathan Lorraine: Understanding Neural Architecture Search Techniques, https://arxiv.org/pdf/1904.00438.pdf
[6] Han Cai, Ligeng Zhu, Song Han, PROXYLESSNAS: DIRECT NEURAL ARCHITECTURE SEARCH ON TARGET TASK AND HARDWARE, https://arxiv.org/pdf/1812.00332v1.pdf
[7] Mingxing Tan et al, MnasNet: Platform-Aware Neural Architecture Search for Mobile, https://arxiv.org/pdf/1807.11626v1.pdf
[8] Bender et al., Understanding and Simplifying One-Shot Architecture Search
[9] Bichen Wu et al., FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
[10] Guo et al., Single Path One-Shot Neural Architecture Search with Uniform Sampling
-
雨宫夏一10 个月前

-
祥子10 个月前
