语音识别在深度学习领域应用研究较少,原因不太清楚,一般就是用长短时记忆网络进行LSTM进行语音识别的实现,需要很大的训练集,而且识别效果不太理想。下面介绍的是通过使用API调用控制台来实现语音识别。
(1)登录百度语音开放平台,进行登录注册后点击创建应用

(2)创建应用并对应用进行命名,点击创建
(3)读取应用列表中的API Key和 secret key进行复制
(4)进行API调用代码的编写来进行调用
部分代码如下,
class DemoError(Exception):
pass
""" TOKEN start """
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode( 'utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
#print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
#print(result_str)
result = json.loads(result_str)
#print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
#print(SCOPE)
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
# print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
通过URL进行控制后台的调用
(5)程序语音识别结果如下:
 其工作原理通过URL调用百度的语音识别后台,进行录音的传送,再将识别的结果进行传回终端,比自己训练模型准确率高很多。
其工作原理通过URL调用百度的语音识别后台,进行录音的传送,再将识别的结果进行传回终端,比自己训练模型准确率高很多。
注意事项;
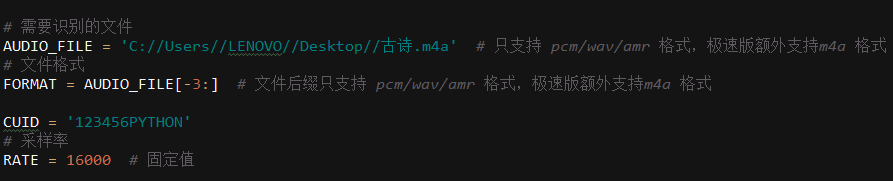 需要设置规定的格式和代码参数
需要设置规定的格式和代码参数
对于录音只能进行规定格式的识别,pcm,wav,amr三种格式进行识别,在百度语音极速版支持M4A格式。
因此需要使用音频编辑器,进行格式的转换,我使用的是迅捷音频转换器,但是也有大小的限制。具体的可以看一下官方技术文档。
完整代码和使用的软件开源在本人GitHub社区:
https://github.com/qianyuqianxun-DeepLearning/audio.git
Reference code(参考代码)
https://github.com/Baidu-AIP/speech-demo