1.JDK和JRE有什么区别?
JDK:java编译和运行的环境(.编译成class文件并运行class文件),确定的说JDK包含jre.
JRE:提供class文件的运行环境
2.byte a = 127; byte b =1; a=a+b; a+=b; 可以成功运行吗?
答案:不可以的,
解释:a=a+b是错误的,我们知道java中整数默认是int,小数默认是double,因此 a=a+b;会出现不能转换为int的错误,所以我们需要进行强制转换a=(byte)(a+b). 在java中+=、*= 、 -=都具有强制类型转换的作用。
3.&和&&的区别和联系?
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。
&&还具有短路的功能,即如果第一个表达式为false,则不再计算第二个表达式。
你可能在写代码的遇到这样的问题
举例:后台传来一个user对象,你进行这样的编码如果user是null

很明显这回报空指针异常

为什么呢?这不是判断空了吗?
因为你用的是&,他是前后两个都去执行,很明显第一个表达式是false,但是第二个表达式还是会执行,null是不能去掉getName的。补充下 null也不能调用equals方法.
4.用最有效率的方法算出2乘以8等于多少?
使用位运算来实现效率最高。位运算符是对操作数以二进制比特位为单位进行操作和运算,操作数和结果都是整型数。对于位运算符“<<”, 是将一个数左移n位,就相当于乘以了2的n次方,那么,一个数乘以8只要将其左移3位即可,位运算cpu直接支持的,效率最高。所以,2乘以8等于几的最效率的方法是2 << 3
5.==和equals的区别?
两个变量用==是变量值的比较,两个实例用==是实例内存地址的比较
在Object类中equals方法,实际上是内存地址的比较
但是例如String类都会对equals方法进行重写

可以看出String类的equals放法是对内存地址和值的比较
6.String是线程安全的吗,为什么?
String是线程安全的,因为String是不可变类用final修饰。
7.String类为什么用final修饰?
https://www.cnblogs.com/lixin-link/p/11085029.html
8.String,StringBuffer与StringBuilder的区别?
String类型是不可变的,这就导致了每次对String的操作都会生成新的对象,效率低下,大量浪费内存空间,
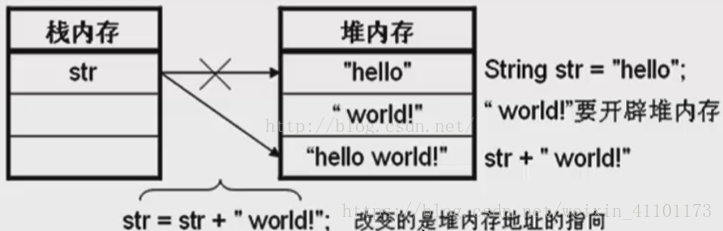
图来自https://blog.csdn.net/weixin_41101173/article/details/79677982
短短的两个字符串就需要开辟三次内存空间,这是对内存的极大浪费,所以就需要使用Java提供的StringBuffer类和StringBuild类来对此种变化字符串进行处理。
和String类不同的是,StringBuffer和StringBuilder类的对象能够被多次修改,并且不产生新的未使用对象。
三者的区别:
String类:不可变字符串
StringBuffer 可变字符串,效率低,线程安全(里面方法加了synchronized锁)
StringBuilder:可变字符序列,效率高,线程不安全。
9.java中的容器

10.ArrayList的底层实现原理是什么?
ArrayList的底层是由数组实现的,并且是线程不安全的,对于元素的查找效率非常高,时间复杂度为O(1)。
我们看下源码:
’
(1)ArrayList有三个构造方法
如果用第一个构造方法生成对象,list的初始容量是10

如果用第二个构造方法生成对象,底层用的是Arrays工具类的copyof方法进行的数组赋值。
如果用第三个放法生成对象,它会创建一个你指定初始容量的数组(满足判断条件)

(2)ArrayList的add方法
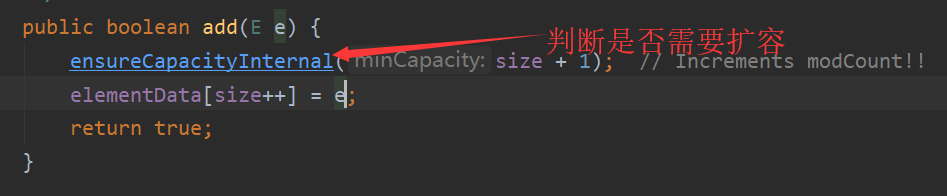
查看ensureCapacityInternal里面
 calculateCapacity方法 是用空参构造方法生成容器的默认值10和添加后数组长度的进行比较,如果不是用空参构造方法生成的则直接放回添加后的数组长度。
calculateCapacity方法 是用空参构造方法生成容器的默认值10和添加后数组长度的进行比较,如果不是用空参构造方法生成的则直接放回添加后的数组长度。
 ensureExplicitCapacity方法里面包含数组扩容方法 此方法是用calculateCapacity返回的值和当前数组度进行比较,如果不满足添加就进行扩容
ensureExplicitCapacity方法里面包含数组扩容方法 此方法是用calculateCapacity返回的值和当前数组度进行比较,如果不满足添加就进行扩容

看看数组是如何扩容的,ArrayList的扩容是扩大到容量的1.5倍的他用的是位运算

它的hugeCapacity方法是用来判断是否需要扩容到最大为Integer.MAX_VALUE
另外说一下为啥ArrayList不适合增加(非尾部)
我们可以看到add的重载方法,当我们传递添加索引和元素时,他会进行数组的向后移动,例如我们在一个数组为9的数组中,在索引为2的位置添加元素,那么后面的元素都需要移动位置,这很浪费时间。
11.LinkedList底层是如何实现的?
LinkedList底层是一个双向链表,https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/LinkedList.md
12,ArrayList和LinkedList有什么区别?
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
底层数据结构: Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
插入和删除是否受元素位置的影响: ① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e) 方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element) )时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② LinkedList 采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。
是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index) 方法)。
内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)】
13.HashMap的底层实现原理?
数组+链表,数组是hashmap的主体,而链表是为了解决hash冲突而存在的。
14.HashMap索引怎么确定的?
主要是有两个方法,第一个是hash,hash方法是获取key的hashCode并且和hashCode右移16进行异或运算,使hashCode的高16位和低16位都参加到了运算中来,实际上是扰动策略,减少哈希碰撞。

第二个方法是putVal,这个方法注意(n - 1) & hash 通过这个表达式就可以处理。数组的长度是2的n次方,这样的好处是(n-1)的二进制表达式变为...000...000111...111,最后几位都是1,这样和hash进行与操作时只会保留hash值最后面几位二进制位,大小在0-(n-1),这刚好就是数组的索引。(所以数组的默认长度是16)

15.HashMap默认平衡因子是多少?干什么用的?
默认平衡因子是 0.75,提高空间利用率和 减少查询成本的折中,主要是泊松分布,0.75的话碰撞最小。
16.HashMap什么时候会扩容?
hashmap默认初始容量是16,当数组容量大于16*0.75=12 时会进行扩容。
有人会问,剩下的4个空间没用就扩容,不浪费空间吗?
确实会浪费空间,但是扩容会减小hash碰撞,这就是典型的空间转时间。
17.HashMap为什么是线程不安全的?
(1)在put的时候,因为该方法不是同步的,假如有两个线程A,B它们的put的key的hash值相同,不论是从(JDK1.8)头插入还是从(JDK1.7)尾插入,假如A获取了插入位置为a,但是还未插入,此时B也计算出待插入位置为a,则不论AB插入的先后顺序肯定有一个会丢失。
(2)在扩容的时候,jdk1.8之前是采用头插法,当两个线程同时检测到hashmap需要扩容,在进行同时扩容的时候有可能会造成链表的循环,主要原因就是,采用头插法,新链表与旧链表的顺序是反的,在1.8后采用尾插法就不会出现这种问题,同时1.8的链表长度如果大于8就会转变成红黑树。
18.HashMap什么时候会转成红黑树?
一个是链表的长度达到8个,一个是数组的长度达到64个
若桶中链表元素个数小于等于6时,树结构还原成链表
19.HashMap是如何扩容的?
会把数组扩大到原来的两倍,需要对之前的元素的索引进行重新的计算,算出来的索引只有两种可能,一个是原来的索引,另一个是原来索引+扩大的值。
20.ConcurrentHashmap线程为什么是安全的?