文章目录
一、time与datetime模块
1、time模块
(1)三种格式时间生成
注意:生成时间都是生成的当前时间
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
#--------------------------我们先以当前时间为准,让大家快速认识三种形式的时间
print(time.time()) # 时间戳:1487130156.419527
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:'2017-02-15 11:40:53'
print(time.localtime()) #本地时区的struct_time
print(time.gmtime()) #UTC时区的struct_time
注意:光理论是不够的,在此送大家一套2020最新Python全栈实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦!
三种时间格式的转换
其中计算机认识的时间只能是’时间戳’格式,而程序员可处理的或者说人类能看懂的时间有: ‘格式化的时间字符串’,‘结构化的时间’ ,于是有了下图的转换关系:
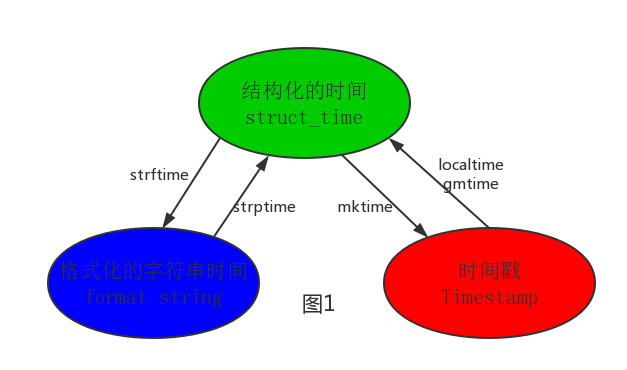 结构化时间和时间戳之间的转换:
结构化时间和时间戳之间的转换:
# 时间戳-->结构化时间
>>> time.localtime(time.time()) # 执行结果:time.struct_time(tm_year=2020, tm_mon=5, tm_mday=15, tm_hour=10, tm_min=20, tm_sec=15, tm_wday=4, tm_yday=136, tm_isdst=0)
>>> time.gmtime(time.time())
# 结构化时间-->时间
>>> time.mktime(time.localtime()) # 执行结果:1589510093.0
结构化时间和格式化字符串时间的转换:
>>> time.strftime("%Y-%m-%d %X", time.localtime()) # 执行结果:'2020-05-15 10:48:47'
>>> time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X') # 执行结果:time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, tm_wday=3, tm_yday=125, tm_isdst=-1)
2、datetime模块
用途:用于时间的加减
import datetime
# 明确datetime.datetime.now()返回的究竟是个什么东西?
>>> datetime.datetime.now() # 我们暂时称之为datetime格式时间,这种格式并不是那三种格式之一,不要被print误导!
datetime.datetime(2020, 5, 15, 11, 7, 14, 505326)
>>> print(datetime.datetime.now()) # 这是print做了优化。不要被误导。
2020-05-15 11:08:11.641439
#只取datetime格式时间的年月日
>>> datetime.date.fromtimestamp(time.time())
datetime.date(2020, 5, 15)
>>> print(datetime.date.fromtimestamp(time.time())) # 执行结果依然被print优化了
2020-05-15
#时间加减
print(datetime.datetime.now() )
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
# 时间修改
>>> c_time = datetime.datetime.now()
>>> c_time.replace(minute=3,hour=2) #分钟改为3分,小时改为2点
datetime.datetime(2020, 5, 15, 2, 3, 32, 602746)
二、random模块
1、基本用法
>>> import random
# 随机生成小数
>>> random.random() # (0,1)----float 大于0且小于1之间的小数
>>> random.uniform(1,3) # 大于1小于3的小数,如1.927109612082716
#随机生成整数
>>> random.randint(1,3) # [1,3] 大于等于1且小于等于3之间的整数
>>> random.randrange(0,100,2) # [0,100) 步长为2,0,2,4...,在这个里面产生随机数,即100以内的随机偶数
# 其他用法
>>> random.choice([1,'23',[4,5]]) # 1或者23或者[4,5]
>>> random.sample([1,'23',[4,5]],2) # 列表元素任意2个组合
>>> item=[1,3,5,7,9]
>>> random.shuffle(item) #打乱item的顺序,相当于"洗牌"
2、生成随机验证码
import random
def make_code(n):
res = ''
for i in range(n):
num = str(random.randint(1,9)) # 生成随机1-9,并强转成字符串格式
char = chr(random.randint(65,90)) # 生成随机a-z字母
get_str = random.choice([num,char]) # 从生成的数字和字母选择一个进行字符串拼接
res += get_str
return res
verti_code = make_code(5)
print(verti_code)
3、打印进度条(random模拟文件下载网速波动)
(1)打印进度条预备知识:格式化字符串
#进度条长度控制为50个%s
>>> print('[%+50s]' %'#') # '+'代表右对齐,可简化省略'+'
[ #]
>>> print('[%50s]' %'#') # 其中还是在传%s,中间的50代表[]中间的字符串长度,且没有传值的用空格代替,且默认为右对齐
[ #]
>>> print('[%-50s]' %'#') # '-'代表左对齐,给%s传一个值'#'
[# ]
# 把进度条长度写活
>>> '[%%-%ds]' %(50) # 第二个%号代表取消第一个%的特殊意义,所以最后只有一个%,%%相当于转义%,因此这里的%s不会被传值,因此被传值的是%d
'[%-50s]'
>>> ('[%%-%ds]' %(50)) %('##') # 相当于'[%-50s]' %('##')
'[## ]'
(2)打印进度条实现
注意:所有的动态的实现都是静态的快速替换
import time
import random
# 定义打印进度条函数
def progress(percent,width=50):
if percent > 1:
percent = 1
show_str = ('[%%-%ds]' %(width)) %(int(percent*width)*'#') # 进度条字符串
# 打印进度条,且后面加上文件下载百分比
print('\r%s %.1f%%' %(show_str,percent*100),end='') # end = '':不换行打印;\r:从行首开始打印;%.1f:传进来的浮点数取一位小数
# 下载文件
recv_size = 0 # 代表下载接收到的数据量
total_size = 150000 # 代表文件总大小,单位为字节
while recv_size < total_size:
time.sleep(random.random()) # random模拟网速波动,也可以用其他uniform方法指定区间波动加快速度
recv_size += 1024 # 0.2秒下载1kb
percent = recv_size/total_size # 获取当前下载文件的比例(小数)
progress(percent,70)
部分代码疑点剖析:
if percent > 1:
percent = 1
# 因为用recv_size += 1024模拟下载文件大小,这样子,只要下载的文件大小不是1024倍数,最后就会出现超过百分百的情况,因此这里做个判断percent大于1,如果大于1,那么就percent = 1,直接下完。
超出百分百:
 有人会问,有
有人会问,有%-50s控制字符的长度(即#的个数),为什么还会出现超过50个字符长度?
答:%-50s,并不是强制约束了传入进来的字符串长度为50(或者说'#'号个数),而是说传进来的'######'这个字符串,左对齐,然后除这个长度以外的我都用'空格'占位,传进来的超过这个长度,只是不再有空格占位罢了!
三、json&pickle模块
1、什么是序列化和反序列化?
# 内存中的数据类型 --> 序列化 --> 特定的格式(json或pickle格式)
# 特定的格式(json或pickle格式)--> 反序列化 --> 内存中的数据类型
2、为何要用序列化?
序列化的结果–>特定的格式的内容有两种用途
- 可用于存储 -->存入硬盘中去
- 传输给其他平台使用 --> 跨平台数据交互
我们都应该都明白一个公司的一个软件,一定是使用了较长时间的,很有可能其中使用了多种编程语言,编程语言有各自负责的一个模块,各编程语言之间会有数据交互,怎么解决?
python java
列表 --> 特定的格式 --> 数组
强调:
- 针对存储用途,应该是一种专有格式–>
pickle格式只能python使用 - 针对跨平台数据交互用途,对
格式的要求应该是一种通用的、能够被所有语言识别的格式
疑问解答:json格式可以用于存储吗?
答:不能,json格式只是把所有语言共有的一些数据类型提取出来做了通用格式,python的集合就无法转成json格式。因此需要用python专用的pickle格式。
3、json模块实现序列化、反序列化
(1)序列化
>>> import json
>>> res = json.dumps([1,'吴晋丞',True])
>>> res
'[1, "\\u5434\\u664b\\u4e1e", true]'
>>> type(res)
<class 'str'>
# 注意:
1. json格式最后得到的都是一个字符串,而且必须用''(单引号)引起来,且里面内容的字符串类型只能用""(双引号)表示字符串,例如:'["\\u5434\\u664b\\u4e1e"]'
2. json格式里面对中文做了处理,但这个"\\u5434\\u664b\\u4e1e"并不是任何一种编码格式,只是中文的json格式,要想显示中文,必须进行反序列化
3. python中布尔值True、False,json格式中都变成小写
(2)反序列化
>>> str is bytes
True
>>> load = json.loads(res) # res是字符串类型,这里传入还可以是bytes类型
>>> load
[1, '吴晋丞', True]
>>> type(load)
<class 'list'>
(3)序列化、反序列化与文件处理结合
# 源代码
import json
with open('db.txt','wb') as f:
res = json.dumps([1,'吴晋丞',True])
f.write(res.encode('utf-8')) # 不能以字符串形式write进文件,除非用t模式
with open('db.txt','rb') as f:
json_res = f.read()
print(json.loads(json_res))
print(json_res,type(json_res))
print('-------------------------------------------------------')
print(json.loads(json_res.decode('utf-8')))
print(json_res.decode('utf-8'),type(json_res.decode('utf-8')))
# 执行结果
[1, '吴晋丞', True]
b'[1, "\\u5434\\u664b\\u4e1e", true]' <class 'bytes'>
-------------------------------------------------------
[1, '吴晋丞', True]
[1, "\u5434\u664b\u4e1e", true] <class 'str'>
实验总结:
- b模式,写入文件必须是字节,因此必须要encode
- b模式从文件直接读出的是字节,根据实验可以看出来字节类型也可以作为loads函数的参数,也可以进行反序列化。
在python解释器2.7与3.6之后都可以json.loads(bytes类型),但唯独3.5不可以 - 字节类型解码后就得到字符串了
- 编码与解码,序列化和反序列化,这两个的过程,其实形式都差不多。
# 多行数据的文件的反序列化
import json
with open('db.txt','wb') as f:
res = json.dumps([1,'吴晋丞',True]) + '\n' # 不加\n不会换行,下面的for循环会出错
res1 = json.dumps([2, 'haha', False])
f.write(res.encode('utf-8'))
f.write(res1.encode('utf-8'))
with open('db.txt','rb') as f:
for i in f:
json_res = json.loads(i)
print(json_res)
# 执行完程序db.txt的内容(文件是多行数据):
[1, "\u5434\u664b\u4e1e", true]
[2, "haha", false]
# 执行结果:
[1, '吴晋丞', True]
[2, 'haha', False]
(4)json模块的dump和load函数实现代码简化
(3)中的序列化、反序列化和文件处理的源代码可以简化的。如下:
# b模式因为要先生成json格式,再编码,因此无法使用dump函数
import json
with open('db.txt','wb') as f:
res = json.dumps([1,'吴晋丞',True])
f.write(res.encode('utf-8'))
with open('db.txt','rb') as f:
json_res = json.load(f) # 直接将整个文件反序列化,因此文件只能有一个数据;如果有多个数据,且一行为一个数据,则还是需要用loads,(3)中有多行数据文件的源代码。
print(json_res)
# t模式,因为dumps函数生成的就是字符串可以用t模式直接写入文件,因此不需要编码,因此可以使用dump函数
import json
with open('db.txt','w') as f:
json.dump([1,'吴晋丞',True],f)
with open('db.txt','r') as f:
print(json.load(f)) # 直接将整个文件反序列化,因此文件只能有一个数据
4、猴子补丁
猴子补丁,是针对模块,进行打补丁的一种思想方法。如果模块中有些方法你觉得写的并不好,你要用自己写的方法,替换此模块中对应的方法,但不改变模块源代码。就要用到猴子补丁。
# 原monkey模块中的方法
def other_func():
print("from other_func")
def hello():
print('hello')
def world():
print('world')
# 你自己认为更好的方法
# 自己写的monkey_plus模块里的方法
def hello():
print('hello everyone !')
def world():
print('This world is beautiful !')
#以后写python项目会有很多python程序文件,不可能一个个打补丁,因此,只需要在程序入口打个补丁,后面所有其他程序文件,用的依旧是补丁版的monkey。
# 下面是运行程序文件。需要调用monkey模块,且还要给monkey模块打补丁,注意打补丁一般在程序入口处打补丁
import monkey
import monkey_plus
def monkey_patch_monkey():
monkey.hello = monkey_plus.hello
monkey.world = monkey_plus.world
monkey_patch_monkey()
# 其实这种场景也比较多, 比如我们引用团队通用库里的一个模块, 又想丰富模块的功能, 除了继承之外也可以考虑用Monkey Patch(猴子补丁).
# 采用猴子补丁之后,如果发现优化后的模块使用效果不符合预期,那也可以快速撤掉补丁(不调用打补丁的函数即可)。个人感觉Monkey Patch带了便利的同时也有搞乱源代码的风险!
5、pickle模块实现序列化、反序列化
pickle模块中的方法的使用和json模块大致一样,有一个不同之处:dumps函数的返回值的数据类型不一样,请看下面:
# 序列化与反序列化:
import pickle
res = pickle.dumps({1,'吴晋丞'}) # 集合
print(pickle.loads(res),type(res)) # 运行结果:{1, '吴晋丞'} <class 'bytes'>
# json模块的dumps的返回值是一个字符串,而pickle模块的dumps的返回值是一个bytes类型。
# 文件处理与序列化与反序列化(b模式):
import pickle
with open('db.txt','wb') as f:
pickle.dump([1],f) # 相当于f.write(pickle.dumps({1,'吴晋丞'}))
with open('db.txt','rb') as f:
print(pickle.load(f)) # 相当于pickle.loads(f.read())
# 不能使用t模式,只能使用b模式,因为dumps返回值是bytes类型,t模式无法接收bytes类型数据
6、python2与python3的pickle兼容性问题
# coding:utf-8
import pickle
with open('a.pkl',mode='wb') as f:
# 一:在python3中执行的序列化操作如何兼容python2
# python2不支持protocol>2,默认python3中protocol=4
# 所以在python2中dump操作应该指定protocol=2
pickle.dump('你好啊',f,protocol=2)
with open('a.pkl', mode='rb') as f:
# 二:python3中反序列化才能正常使用
res=pickle.load(f)
print(res)
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
四、configparser模块
用途:configparser模块专门用来获取配置文件中的配置信息的。
configparser模块支持的配置文件格式如下:
# 注释1
; 注释2
[section1]
k1 = v1
k2:v2 # :号相当于=号
user=egon
age=18
is_admin=true
salary=31
[section2]
k1 = v1
1、获取配置文件信息(重点)
import configparser
config=configparser.ConfigParser()
config.read('a.cfg')
#查看所有的标题
res=config.sections() #['section1', 'section2']
print(res)
#查看标题section1下所有key=value的key
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list) #[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')]
#查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon
#查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) #18
#查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True
#查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.0
2、修改配置文件信息
import configparser
config=configparser.ConfigParser()
config.read('a.cfg',encoding='utf-8')
#删除整个标题section2
config.remove_section('section2')
#删除标题section1下的某个k1和k2
config.remove_option('section1','k1')
config.remove_option('section1','k2')
#判断是否存在某个标题
print(config.has_section('section1'))
#判断标题section1下是否有user
print(config.has_option('section1',''))
#添加一个标题
config.add_section('egon')
#在标题egon下添加name=egon,age=18的配置
config.set('egon','name','egon')
config.set('egon','age',18) #报错,必须是字符串
#最后将修改的内容写入文件,完成最终的修改
config.write(open('a.cfg','w'))
五、hashlib模块
1、hash介绍
客户端,用户会输入账号、密码,实现登录,账号密码的传输不可能采用明文传输吧,被别人抓包分析,账号密码直接就暴露了,因此需要加密,把账号密码一起hash得到一个hash值,传给服务端,对比hash值是否一样即可。
1. 什么叫hash?
hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值
2. hash值的特点是:
* 只要传入的内容一样,得到的hash值必然一样 =====> 要用明文传输密码文件完整性校验
* 不能由hash值反解成内容 =======> 把密码做成hash值,不应该在网络传输明文密码
* 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
但也可以通过撞库破解hash得到密码,抓包得到一个账号与密码的hash值,然后预先有个数据库,里面存着常用的密码,然后把数据库里的一个个密码与账号hash,把得到的hash值和抓包的hash值对比,直到得到一样的,就破解成功了。如果你账号都不晓得,还破解个屁!!!
既然这种简单hash可以比较容易破解,那么就只能采用密码加盐进行hash。这样一般来说都非常不容易破解。
2、hash应用
(1)hash基本应用
hash算法就像一座工厂,工厂接收你送来的原材料(可以用m.update()为工厂运送原材料),经过加工返回的产品就是hash值
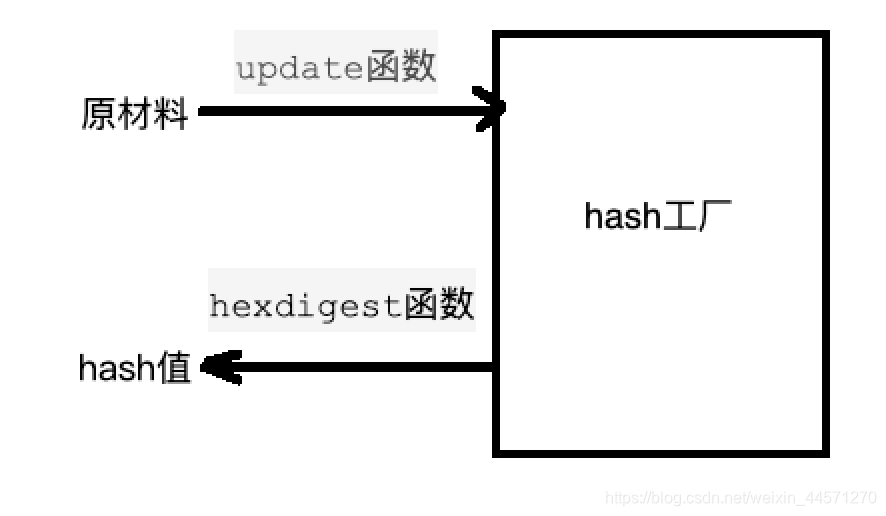
# hashlib模块的用法
import hashlib
m=hashlib.md5() # m=hashlib.sha256(),指定需要使用的hash算法
m.update('hello'.encode('utf8'))
m.update('world'.encode('utf8'))
print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af
# 可以多次输送原材料,最后一起hash。相当于m.update('helloworld'.encode('utf8'))
(2)模拟撞库
虽然现实是账号密码一起hash,这里为了验证的简单,我就只是密码进行hash,然后撞库。
import hashlib
passwds=[ # 某人账号常用密码
'alex3714',
'alex1313',
'alex94139413',
'alex123456',
'123456alex',
'a123lex',
]
def make_passwd_dic(passwds):
dic={}
for passwd in passwds:
m=hashlib.md5()
m.update(passwd.encode('utf-8'))
dic[passwd]=m.hexdigest()
return dic
def break_code(cryptograph,passwd_dic):
for k,v in passwd_dic.items():
if v == cryptograph:
print('密码是===>\033[46m%s\033[0m' %k)
cryptograph='aee949757a2e698417463d47acac93df' # 抓包获取的hash值
break_code(cryptograph,make_passwd_dic(passwds))
(3)校验文件完整性
针对小文件(整个文件hash):
import hashlib
with open('db.txt','rb') as f:
m = hashlib.md5()
m.update(f.read())
print(m.hexdigest())
针对比较大的文件(整个文件hash):
# 文件比较大,不能全部读入内存,不然可能会死机,或者卡!
import hashlib
with open('db.txt','rb') as f:
while True:
res = f.read(2000)
if len(res) == 0: # 先要判断是否为空,再决定是否将内容进行hash
break
m = hashlib.md5()
m.update(res) # 文件读出来本来就是bytes类型,因此不再需要encode
verti_code = m.hexdigest()
print(verti_code)
针对非常大的文件(文件部分hash):
# 我们不能再像中型文件那样while循环整个文件hash校验了,太慢了
# 下面是文件大小,用下面这个文件模拟非常大的文件:
total_res = 0
with open('haha.jpeg','rb') as f:
while True:
res = f.read(2048)
if len(res) == 0:
break
total_res += len(res)
print(total_res) # 运行结果:267751 byte
# 校验文件完整性
import hashlib
total_res = 0
with open('haha.jpeg','rb') as f:
m = hashlib.md5()
# 文件前部分
f.seek(100)
res = f.read(20000)
m.update(res)
# 文件中间部分
f.seek(70000)
res1 = f.read(20000)
m.update(res1)
# 文件结尾部分
f.seek(200000)
res2 = f.read(20000)
m.update(res2)
print(m.hexdigest())
# 注意:
1. 利用f.seek分别在文件中取部分内容,进行hash,可以多取几部分,取小点。也可以利用while循环等距取样。
2. 服务端基于这种前中后取文件内容进行hash的规则,得到一个校验码。客户端拿到文件,也要采用同样的规则进行hash.
3. 虽然这样也会出现文件不一致的情况,但概率较小。
3、密码加盐
密码加盐就是用户端在用户的密码上,在任意位置加上任意数量的数字或字母或中文等,再进行hash,得到值传给服务端,服务端用同样的加盐规则对你的密码进行加盐再hash,判断你的密码是否正确!
这样会极大提高撞库的难度,而且我们假设抓到包的人撞库成功,得到一串加盐的密码,但是他知道那个地方,哪些内容是盐吗?很难猜中!他还要对一长串加盐密码进行排列组合去试密码。
六、suprocess模块
用途:执行命令,获取其命令的标准输出或错误输出。
import subprocess
obj = subprocess.Popen('ls /;ls /root',shell = True,
stdout=subprocess.PIPE, # 产生一个管道,把管道的内存地址给stdout,标准输出只认stdout,于是就把标准输出扔进这个管道里去了
stderr=subprocess.PIPE # 再产生一个管道,把管道的内存地址给stderr,错误输出只认stderr,于是就把错误输出扔进这个管道里去了
)
print(obj)
print(obj.stderr.read()) # 从错误输出管道里读取内容,read可以指定读取内容的大小
print('---------------------------------')
print(obj.stdout.read().decode('utf-8')) # subprocess使用当前系统默认编码进行encode把内容扔进管道,得到结果为bytes类型,在windows下需要用gbk解码
# 执行结果:
<subprocess.Popen object at 0x108038390>
b'ls: /root: No such file or directory\n'
---------------------------------
X11
X11R6
bin
lib
libexec
local
sbin
share
standalone
七、logging模块
1、日志级别与配置
import logging
# 一:日志配置
logging.basicConfig(
# 1、日志输出位置:1、终端 2、文件
# filename='access.log', # 不指定,默认打印到终端
# 2、日志格式
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# 3、时间格式
datefmt='%Y-%m-%d %H:%M:%S %p',
# 4、日志级别
# critical => 50
# error => 40
# warning => 30
# info => 20
# debug => 10
level=30,
)
# 二:输出日志
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
'''
# 注意下面的root是默认的日志名字
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
'''
2、日志配置字典
logger:产生日志的对象
Filter:过滤日志的对象
Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端
Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
(1)日志字典的定义
"""
settings.py
"""
import os
# 1、定义三种日志输出格式,日志中可能用到的格式化串如下
# %(name)s Logger的名字
# %(levelno)s 数字形式的日志级别
# %(levelname)s 文本形式的日志级别
# %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
# %(filename)s 调用日志输出函数的模块的文件名
# %(module)s 调用日志输出函数的模块名
# %(funcName)s 调用日志输出函数的函数名
# %(lineno)d 调用日志输出函数的语句所在的代码行
# %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
# %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
# %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
# %(thread)d 线程ID。可能没有
# %(threadName)s 线程名。可能没有
# %(process)d 进程ID。可能没有
# %(message)s用户输出的消息
# 2、强调:其中的%(name)s为getlogger时指定的名字
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]''[%(levelname)s][%(message)s]'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
# 3、日志配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
'test': {
'format': test_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'formatter': 'standard',
# 可以定制日志文件路径
# BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
# LOG_PATH = os.path.join(BASE_DIR,'a1.log')
'filename': 'a1.log', # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
'other': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'test',
'filename': 'a2.log',
'encoding': 'utf-8',
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': { # 这里'',没有名字,除下面指定日志名字'专门的采集',使用下面那个loggers,其他没有的日志名,都使用这个loggers,日志名为你传进来的日志名!
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制),loggers这里定义的是那种级别往上需要产生日志,handlers是定义那种级别往上的日志我需要输出到文件或终端。
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'专门的采集': {
'handlers': ['other',],
'level': 'DEBUG',
'propagate': False,
},
},
}
(2)日志字典的使用
"""
run.py
"""
import settings
# !!!强调!!!
# 1、logging是一个包,需要使用其下的config、getLogger,可以如下导入
# from logging import config
# from logging import getLogger
# 2、也可以使用如下导入
import logging.config # 这样连同logging.getLogger都一起导入了,然后使用前缀logging.config.
# 3、加载配置
logging.config.dictConfig(settings.LOGGING_DIC)
# 4、输出日志
logger1=logging.getLogger('用户交易')
logger1.info('egon儿子alex转账3亿冥币')
# logger2=logging.getLogger('专门的采集') # 名字传入的必须是'专门的采集',与LOGGING_DIC中的配置唯一对应
# logger2.debug('专门采集的日志')
八、re模块
1、什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
2、常用匹配模式(元字符)

3、正则匹配演练
import re
1. \w与\W
print(re.findall('\w','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
print(re.findall('\W','hello egon 123')) #[' ', ' ']
2. \s与\S
print(re.findall('\s','hello egon 123')) #[' ', ' ', ' ', ' ']
print(re.findall('\S','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
3. \n \t都是空,都可以被\s匹配
print(re.findall('\s','hello \n egon \t 123')) #[' ', '\n', ' ', ' ', '\t', ' ']
4. \n与\t
print(re.findall(r'\n','hello egon \n123')) #['\n']
print(re.findall(r'\t','hello egon\t123')) #['\n']
5. \d与\D
print(re.findall('\d','hello egon 123')) #['1', '2', '3']
print(re.findall('\D','hello egon 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' ']
6. ^与$
print(re.findall('^h','hello egon 123')) #['h']
print(re.findall('3$','hello egon 123')) #['3']
------------------------------------------------------------------------
------------------------------------------------------------------------
# 重复匹配:| . | * | ? | .* | .*? | + | {n,m} |
1. .(小数点)
print(re.findall('a.b','a1b')) # ['a1b']
print(re.findall('a.b','a1b a*b a b aaab')) # ['a1b', 'a*b', 'a b', 'aab']
print(re.findall('a.b','a\nb')) # []
print(re.findall('a.b','a\nb',re.S)) # ['a\nb']
print(re.findall('a.b','a\nb',re.DOTALL)) # ['a\nb']同上一条意思一样
# 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
# 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
2. *
print(re.findall('ab*','bbbbbbb')) # []
print(re.findall('ab*','a')) # ['a']
print(re.findall('ab*','abbbb')) # ['abbbb']
3. ?
print(re.findall('ab?','a')) # ['a']
print(re.findall('ab?','abbb')) # ['ab']
# 匹配所有包含小数在内的数字
print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) # ['123', '1.13', '12', '1', '3']
4. .*默认为贪婪匹配
print(re.findall('a.*b','a1b22222222b')) # ['a1b22222222b']
5. .*?为非贪婪匹配:推荐使用
print(re.findall('a.*?b','a1b22222222b')) # ['a1b']
6. +
print(re.findall('ab+','a')) #[]
print(re.findall('ab+','abbb')) #['abbb']
7. {n,m}
print(re.findall('ab{2}','abbb')) # ['abb']
print(re.findall('ab{2,4}','abbbbb')) # ['abbbb']
print(re.findall('ab{1,}','abbb')) # 'ab{1,}' ===> 'ab+'
print(re.findall('ab{0,}','abbb')) # 'ab{0,}' ===> 'ab*'
8. []
print(re.findall('a[1*-]b','a1b a*b a-b')) # []内的都为普通字符了,匹配1或*或-,都可以
print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) # []内的^代表的意思是取反,不匹配1、*、-
print(re.findall('a[0-9]b','a1b a*b a-b a=b')) # 匹配0到9的数字中的任何一个都可以
print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) # 匹配a到z中的字母中的任何一个
print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) # 匹配一个a到z中的任何一个字母,再匹配一个A到Z中的任何一个字母
9. \
# print(re.findall('a\\c','a\c')) # 对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常
print(re.findall(r'a\\c','a\c')) # r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义
print(re.findall('a\\\\c','a\c')) # 同上面的意思一样,和上面的结果一样都是['a\\c']
10. ()
print(re.findall('ab+','ababab123')) # ['ab', 'ab', 'ab']
print(re.findall('(ab)+123','ababab123')) # ['ab'],匹配到末尾的ab123中的ab
print(re.findall('(?:ab)+123','ababab123')) # findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容
print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">点击</a>'))# ['http://www.baidu.com']
print(re.findall('href="(?:.*?)"','<a href="http://www.baidu.com">点击</a>'))# ['href="http://www.baidu.com"']
11. |
print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))
----------------------------------了解线-----------------------------------
九、os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
# 文件路径处理
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
十、sys模块
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.platform 返回操作系统平台名称
十一、shutil模块
十二、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r'sheve.txt')
# f['stu1_info']={'name':'egon','age':18,'hobby':['piao','smoking','drinking']}
# f['stu2_info']={'name':'gangdan','age':53}
# f['school_info']={'website':'http://www.pypy.org','city':'beijing'}
print(f['stu1_info']['hobby'])
f.close()
十三、xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
注意:最后送大家一套2020最新企业Pyhon项目实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦!