一、添加依赖
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka --> <!-- 这里使用的spring版本是4.3.23.RELEASE, 所以引用的spring-kafka版本是1.3.10的,如果太高,会 Caused by: java.lang.ClassNotFoundException: org.springframework.core.log.LogAccessor--> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.3.10.RELEASE</version> </dependency> <!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.28</version> </dependency>
二、创建KafkaConfiguration配置类
都是一些配置参数,值得注意的是,KafkaTemplate的类型为<Integer,String>,我们可以找kafkaTemplate的send方法,有多个重载方法,其中有个方法如下,key和data参数都为泛型,这其实就是对应着KafkaTemplate<Integer,String>。那具体有什么用呢,还记得我们的Topic中可以包含多个Partition(分区)吗,那我们如果不想手动指定发送到哪个分区,我们则可以利用key去实现。这里我们的key是Integer类型,template会根据 key 路由到对应的partition中,如果key存在对应的partitionID则发送到该partition中,否则由算法选择发送到哪个partition。
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.IntegerDeserializer; import org.apache.kafka.common.serialization.IntegerSerializer; import org.apache.kafka.common.serialization.StringDeserializer; import org.apache.kafka.common.serialization.StringSerializer; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import org.springframework.kafka.core.DefaultKafkaProducerFactory; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.core.ProducerFactory; import java.util.HashMap; import java.util.Map; @Configuration @EnableKafka public class KafkaConfiguration { //ConcurrentKafkaListenerContainerFactory为创建Kafka监听器的工程类,这里只配置了消费者 @Bean public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); return factory; } //根据consumerProps填写的参数创建消费者工厂 @Bean public ConsumerFactory<Integer, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerProps()); } //根据senderProps填写的参数创建生产者工厂 @Bean public ProducerFactory<Integer, String> producerFactory() { return new DefaultKafkaProducerFactory<>(senderProps()); } //kafkaTemplate实现了Kafka发送接收等功能 @Bean public KafkaTemplate<Integer, String> kafkaTemplate() { KafkaTemplate template = new KafkaTemplate<Integer, String>(producerFactory()); return template; } //消费者配置参数 private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); //连接地址 props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //GroupID props.put(ConsumerConfig.GROUP_ID_CONFIG, "bootKafka"); //是否自动提交 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); //自动提交的频率 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100"); //Session超时设置 props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); //键的反序列化方式 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); //值的反序列化方式 props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } //生产者配置 private Map<String, Object> senderProps (){ Map<String, Object> props = new HashMap<>(); //连接地址 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //重试,0为不启用重试机制 props.put(ProducerConfig.RETRIES_CONFIG, 1); //控制批处理大小,单位为字节 props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); //批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量 props.put(ProducerConfig.LINGER_MS_CONFIG, 1); //生产者可以使用的总内存字节来缓冲等待发送到服务器的记录 props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024000); //键的序列化方式 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); //值的序列化方式 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } }
三、创建DemoListener消费者
这里的消费者其实就是一个监听类,指定监听名为topic.quick.demo的Topic,consumerID为demo。
import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component; @Component public class DemoListener { private static final Logger log = LoggerFactory.getLogger(DemoListener.class); //声明consumerID为demo,监听topicName为test20200519的Topic @KafkaListener(id = "demo", topics = "test20200519") public void listen(String msgData) { log.info("demo receive : "+msgData); } }
可以在cmd命令行窗口中创建主题,启动生产者,观察控制台。
四、操作Topic以及Kafka Tool 2的使用
1. Kafka Tool 2
Kafka Tool 2是一款Kafka的可视化客户端工具,可以非常方便的查看Topic的队列信息以及消费者信息以及kafka节点信息。下载地址
(1) 创建连接
(2) 配置连接
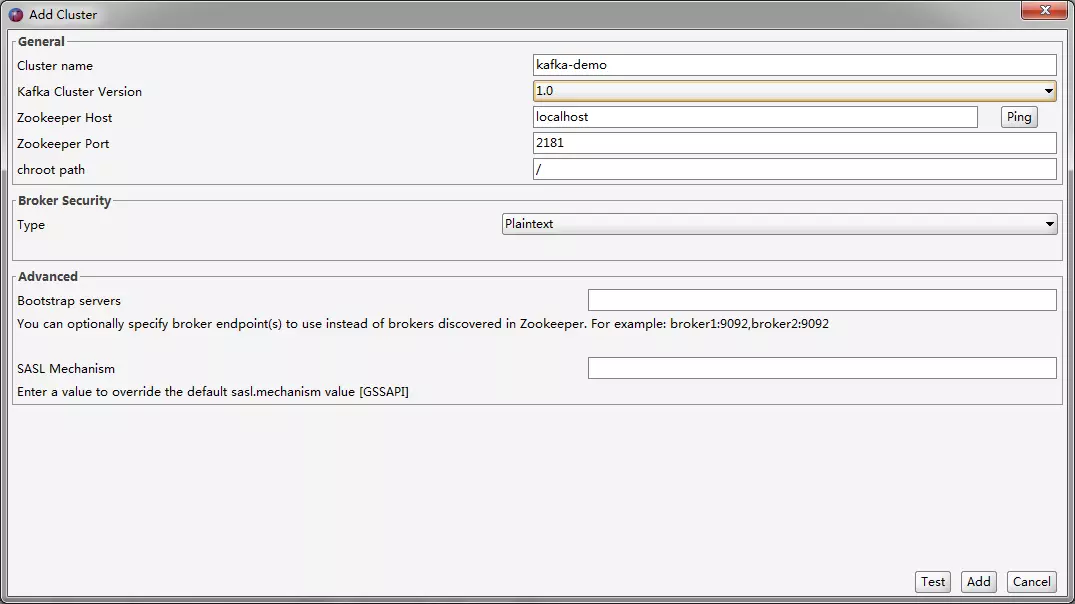
这个软件监控的是Zookeeper而不是Kafka,Kafka的集群搭建也是依赖Zookeeper来实现的,所以默认情况下我们都是直接通过Zookeeper去完成大部分操作。
(3) 界面
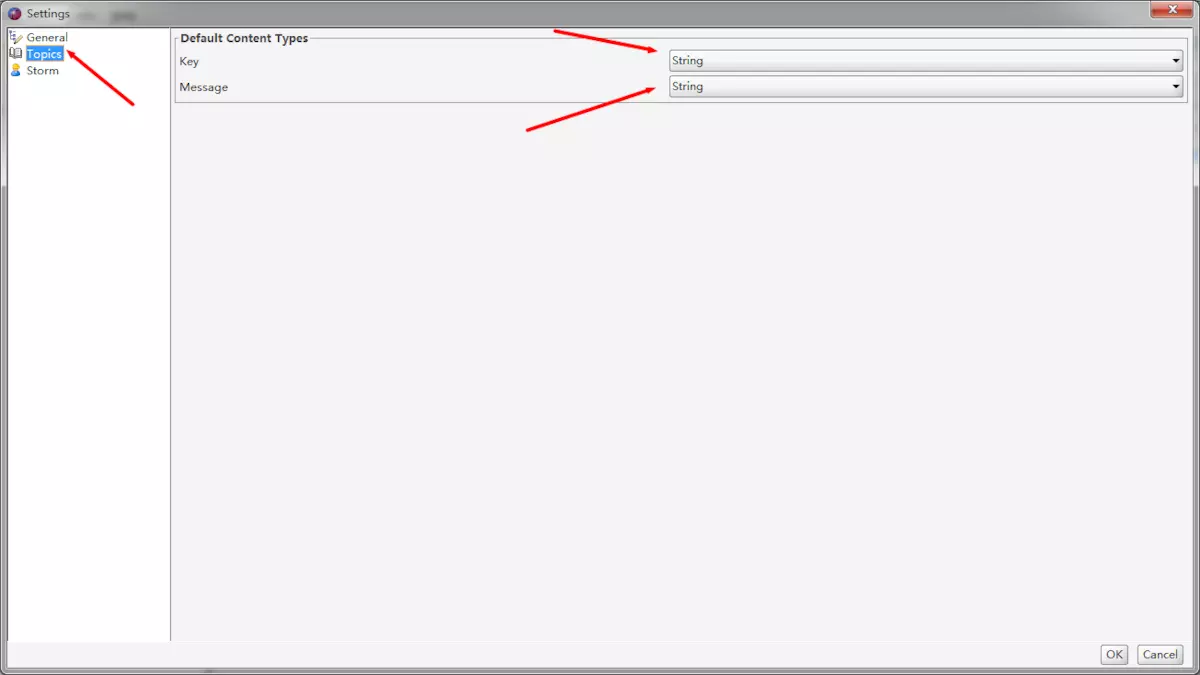
(4) 修改为明文显示
这个软件默认显示数据的类型为Byte,说白了我们是不能直接看到消息的明文数据的。
2. 操作Topic
(1) 手动创建Topic
KafkaTemplate在发送的时候就已经帮我们完成了创建Topic的操作,所以我们不需要主动创建Topic,而是交由KafkaTemplate去完成。但这样也出现了问题,这种情况创建出来的Topic的Partition(分区)数永远只有1个,也不会有副本(不知道的回炉重造,Kafka部署集群时使用的),这就导致了我们在后期不能顺利扩展。所以这种情况我们需要使用代码手动去创建Topic。