前言
在学习本章节前,务必做好以下准备工作:
1、安装并启动了Zookeeper[官网],如需帮助,点击进入;
注:zk和kafka的安装与介绍,本文不做重点介绍,具体参考上方链接。
¥¥¥¥¥¥下面我们一起来学习一下Spring Boot整个Kafka的入门级教程¥¥¥¥¥¥
一、准备工作
1.1、新建 Spring Boot 2.x Web 工程
1.1.1、工程创建步骤演示
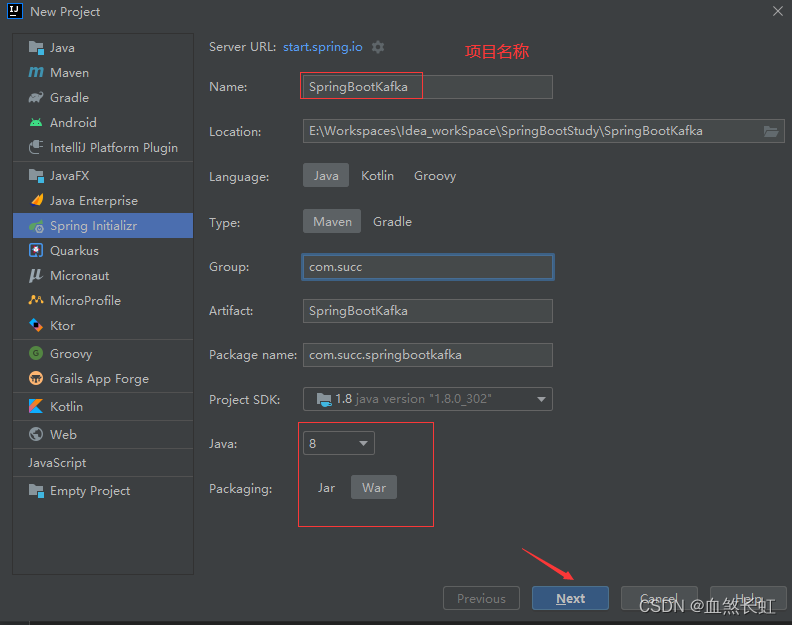 注意勾选下面几个选项!
注意勾选下面几个选项!

1.1.2、工程目录展示
注:项目创建成功后,先创建package和java文件,为下面的代码编写工作做铺垫。

1.2、pom.xml添加spring-kafka相关依赖
注:里面添加的依赖主要有三方面,分别是系统已自动配置好的、kafka核心依赖+测试依赖、其他相关辅助性的依赖(比如:lombok)。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.succ</groupId>
<artifactId>SpringBootKafaka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringBootKafaka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 阿里巴巴 fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
1.3、在application.yml 文件中,添加 kafka 相关配置
spring:
kafka:
# 指定 kafka 地址,我这里部署在的虚拟机,开发环境是Windows,kafkahost是虚拟机的地址, 若外网地址,注意修改为外网的IP( 集群部署需用逗号分隔)
bootstrap-servers: kafkahost:9092
consumer:
# 指定 group_id
group-id: group_id
auto-offset-reset: earliest
# 指定消息key和消息体的序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# 指定消息key和消息体的序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringSerializer
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
注意:kafkahost别名需要单独配置,如需帮助点击进入;当然,这里也可以直接写虚机的IP地址(因为开发环境是Windows,kafka部署在虚拟机上,所以这里不能写localhost(等价于127.0.0.1),否则访问的就是windows的localhost,根本访问不到虚拟机的kafka)。
auto.offset.reset 有3个值可以设置:
earliest:当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset时,从头开始消费;
latest:当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据;
none: topic各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的 offset,则抛出异常;
默认建议用 earliest, 设置该参数后 kafka出错后重启,找到未消费的offset可以继续消费。而 latest 这个设置容易丢失消息,假如 kafka 出现问题,还有数据往topic中写,这个时候重启kafka,这个设置会从最新的offset开始消费, 中间出问题的那些就不管了。
注:更详细的配置信息,见底部的拓展
二、代码编写
2.1、Order(订单)实体Bean的编码
package model;
import lombok.*;
import java.time.LocalDateTime;
/**
* @create 2022-10-08 1:25
* @describe 订单类javaBean实体
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class Order {
/**
* 订单id
*/
private long orderId;
/**
* 订单号
*/
private String orderNum;
/**
* 订单创建时间
*/
private LocalDateTime createTime;
}
2.2、KafkaProvider(消息提供者)的编写
package com.succ.springbootkafaka.provider;
import com.alibaba.fastjson.JSONObject;
import com.succ.springbootkafaka1.model.Order;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.time.LocalDateTime;
/**
* @create 2022-10-14 21:39
* @describe 话题的创建类,使用它向kafka中创建一个关于Order的订单主题
*/
@Component
@Slf4j
public class KafkaProvider {
/**
* 消息 TOPIC
*/
private static final String TOPIC = "shopping";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(long orderId, String orderNum, LocalDateTime createTime) {
// 构建一个订单类
Order order = Order.builder()
.orderId(orderId)
.orderNum(orderNum)
.createTime(createTime)
.build();
// 发送消息,订单类的 json 作为消息体
ListenableFuture<SendResult<String, String>> future =
kafkaTemplate.send(TOPIC, JSONObject.toJSONString(order));
// 监听回调
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.info("## Send message fail ...");
}
@Override
public void onSuccess(SendResult<String, String> result) {
log.info("## Send message success ...");
}
});
}
}
2.3、KafkaConsumer(消费者)代码编写
package consumer;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* @create 2022-10-08 1:25
* @describe 通过指定的话题和分组来消费对应的话题
*/
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "shopping", groupId = "group_id") //这个groupId是在yml中配置的
public void consumer(String message) {
log.info("## consumer message: {}", message);
}
}
三、单元测试
3.1、准备工作
3.1.1、查看Zookeeper的启动状态
用cd命令,进入到zk的安装目录
通过 bin 目录下的 zookeeper-server-start.sh 启动脚本,来启动 zk 单节点实例:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
由于本虚拟机zk的各项基本配置都已到位,可以直接启动(zk的安装如需帮助,点击进入)
#zkServer.sh status 查看服务状态
#zkServer.sh start 启动zk
#zkServer.sh stop 停掉zk
#zkServer.sh restart 重启zk

如上图所示,zk的启动模式为standalone单例模式(非集群),已启动。
3.1.2、启动kafka
使用cd命令,进入kafka安装目录下的bin目录
进入解压目录,通过 bin 目录下的 kafka-server-start.sh 脚本,后台启动 Kafka :
pwd
./kafka-server-start.sh ../config/server.properties

正常启动,如下图所示:

温馨提示:Kafka启动报错不识别主机名的解决办法,点击进入。
java.net.UnknownHostException|unknown error at java.net.Inet6AddressImpl.lookupAllHost
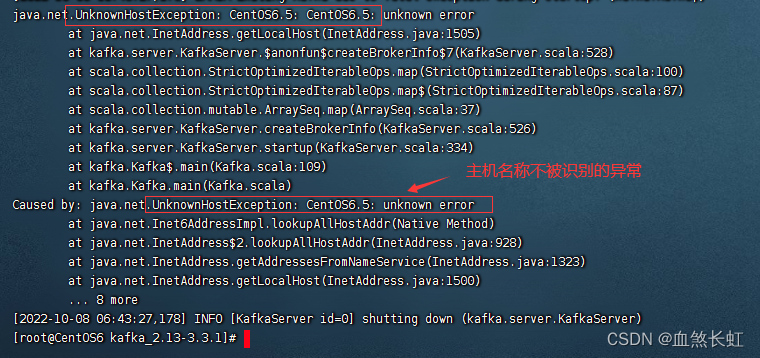
3.1.3、三种方式,查看kafka的启动状态
jps -ml #方式一,通过jps命令查看(尾部的-ml为非必须参数)
netstat -nalpt | grep 9092 #方式二,通过查看端口号查看 lsof -i:9092 #方式三3.2、单元测试代码编写
package com.succ.springbootkafaka;
import com.succ.springbootkafaka.provider.KafkaProvider;
import org.junit.jupiter.api.Test;//注意,这个junit用自带的就可以
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class SpringBootKafakaApplicationTests {
@Autowired
private KafkaProvider kafkaProvider;
@Test
public void sendMessage() throws InterruptedException {
//如果这里打印为null,要么是zk或kafka没正常启动,此时进入linux分别查看他们状态接口,另外也需要排查一下你的yum文件配置的kafka的地址,最后排查自己的注解是否引入错误的package
System.out.println("是否为空??+"+kafkaProvider);
// 发送 1000 个消息
for (int i = 0; i < 1000; i++) {
long orderId = i+1;
String orderNum = UUID.randomUUID().toString();
kafkaProvider.sendMessage(orderId, orderNum, LocalDateTime.now());
}
TimeUnit.MINUTES.sleep(1);
}
}
3.3、测试
3.3.1、发送 1000 个消息,看消息是否能够被正常发布与消费
控制台日志如下:

3.3.2、查看Kafka 的 topic 列表,看 “shopping” 这个topic 是否正常被创建
执行 bin 目录下查看 topic 列表的 kafka-topics.sh 脚本:
注:如果你的kafka版本,高于2.2+=,使用如下命令查看
bin/kafka-topics.sh --list --bootstrap-server kafkahost:9092

如上图所示,可以看到刚刚创建的主题shopping
注:如果你的kafka版本,低于2.2-,使用如下命令查看
bin/kafka-topics.sh --list --zookeeper kafkahost:2181上面的kafkahost,是在 vim /etc/host中配置的,另外IP通过ifconfig命令获取

至此,测试成功!
四、为什么要先启动zk,然后启动kafka
因为kafka的运行依赖zk的启动。
具体,可以进入kafka的解压目录的/conf/目录下
cd /usr/src/kafka_2.13-3.3.1/config/ && ls
vi server.properties


五、收尾工作
1、关闭Zookeeper
zkServer.sh status
zkServer.sh stop
zkServer.sh status 
2、关闭kafka
cd /usr/src/kafka_2.13-3.3.1/ && ls
jps
bin/kafka-server-stop.sh
jps 
注意事项:如果你是首次安装并使用kafka,那么该关闭命令是不能生效的,需要进入kafka的配置文件对配置做一些更改,具体如下:
vim bin/kafka-server-stop.sh 找到下图中的这段代码,修改一下

#PIDS=$(ps ax | grep ' kafka\.Kafka ' | grep java | grep -v grep | awk '{print $1}')
PIDS=$(jps -lm | grep -i 'kafka.Kafka' | awk '{print $1}')
修改后的命令作用:使用jps -lm命令列出所有的java进程,然后通过管道,利用grep -i 'kafka.Kafka’命令将kafka进程筛出来,最后再接一管道命令,利用awk将进程号取出来。

总结
本文对通过一个小案例,初步介绍了 Spring Boot对kafka的整合,完成了从Spring Boot中调用生产者(向kafka中创建主题)、消费者(消费信息)完成对kafka的调用。
当然kafka的使用,远不止于此,后期也会在不同的篇幅中,更多、更加深入的介绍。
尾言
走前人走过的路,为后来者踩坑。
在整合的过程中,难免遇到磕磕碰碰,还好有我与你同行,里面遇到的一些坑,基本都有标注。
如果觉得文章还不错,欢迎点赞收藏!
拓展
关于yum文件更详细的配置
spring:
kafka:
bootstrap-servers: 172.101.203.33:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false