Scrapy 框架
Scrapy 简介
- Scray 是用python写的为乐爬取网站数据,提取结构性数据的应用框架
Scrapy框架原理图
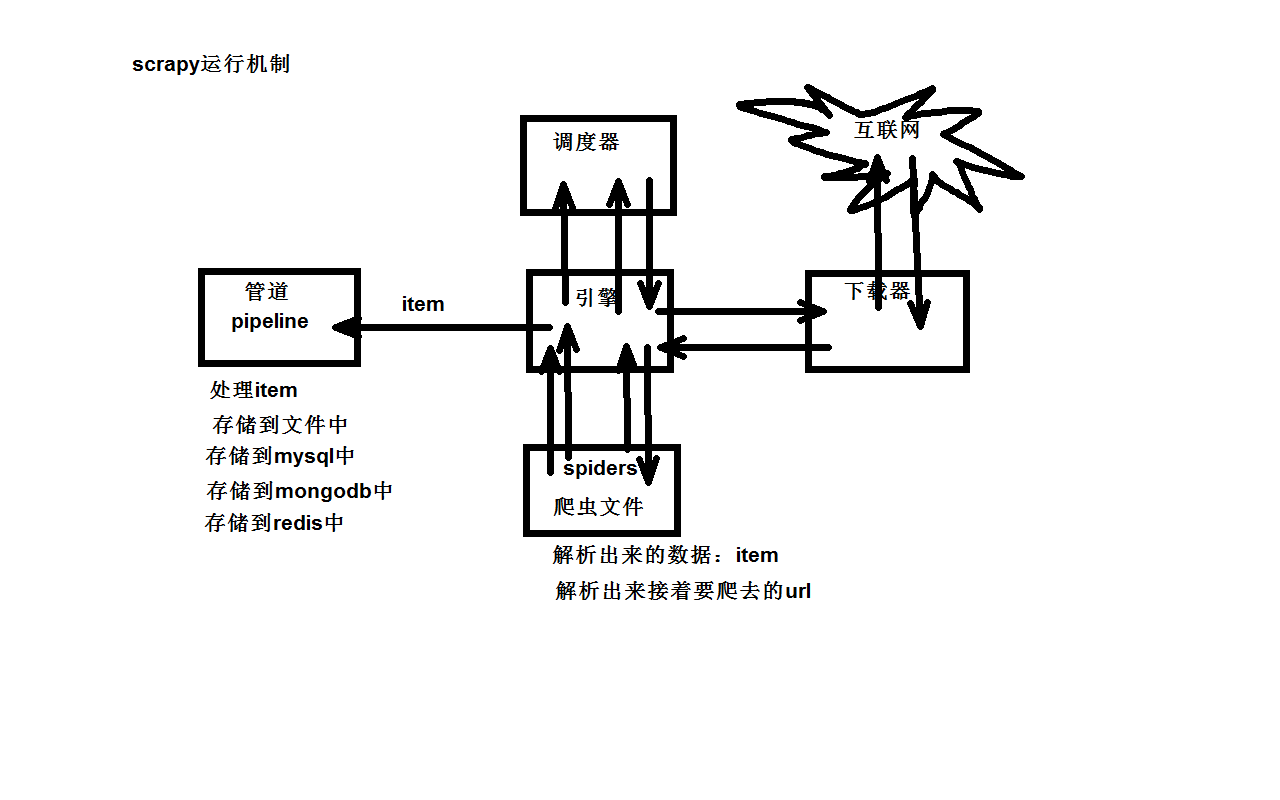
白话讲解Scrapy 运作流程
代码写好,程序开始运行...
- 引擎
:Hi!Spider`, 你要处理哪一个网站? Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
制作Scrapy爬虫步骤
1.新建项目
scrapy startproject mySpider
- 此时会出现一个目录结构(以下对各文件进行解释)
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录```
2.制作爬虫
scrapy genspider ItCast www.itcast.cn
- 此时会创建一个 爬虫文件夹,打开ItCast.py 爬虫文件会看到以下代码:
class ItcastSpider(scrapy.Spider):
name = "itcast" #爬虫的名字
allowed_domains = ["itcast.cn"] # 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = (
'http://www.itcast.cn/',
) # 爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成
def parse(self, response): # 解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数
pass
3. 明确目标(mySpider/items.py)
- 想要爬取那些信息,在Item里定义结构化数据字段,保存爬取到的数据
4.保存数据(pipelines.py)
- 在管道文件中设置保存数据的方法,可以保存到本地或者数据库
一个简单例子
(1) items.py
- 想要爬取的信息
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
(2) itcastspider.py
- 写爬虫程序
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
from mySpider.items import ItcastItem
# 创建一个爬虫类
class ItcastSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowd_domains = ["http://www.itcast.cn/"]
# 爬虫其实的url
start_urls = [
"http://www.itcast.cn/channel/teacher.shtml#aandroid",
]
def parse(self, response):
#with open("teacher.html", "w") as f:
# f.write(response.body)
# 通过scrapy自带的xpath匹配出所有老师的根节点列表集合
teacher_list = response.xpath('//div[@class="li_txt"]')
# 遍历根节点集合
for each in teacher_list:
# Item对象用来保存数据的
item = ItcastItem()
# name, extract() 将匹配出来的结果转换为Unicode字符串
# 不加extract() 结果为xpath匹配对象
name = each.xpath('./h3/text()').extract()
# title
title = each.xpath('./h4/text()').extract()
# info
info = each.xpath('./p/text()').extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
yield item
(3) setting.py 修改
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 4 #防止爬取过快丢失数据
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
ITEM_PIPELINES = {
'tencent.pipelines.TencentPipeline': 300,
}
(4) pipelines.py
- 数据保存到本地
# -*- coding: utf-8 -*-
import json
class ItcastPipeline(object):
# __init__方法是可选的,做为类的初始化方法
def __init__(self):
# 创建了一个文件
self.filename = open("teacher.json", "w")
# process_item方法是必须写的,用来处理item数据
def process_item(self, item, spider):
jsontext = json.dumps(dict(item), ensure_ascii = False) + "\n"
self.filename.write(jsontext.encode("utf-8"))
return item
# close_spider方法是可选的,结束时调用这个方法
def close_spider(self, spider):
self.filename.close()