文章链接:https://arxiv.org/pdf/1906.08237.pdf
代码链接:英文--https://github.com/zihangdai/xlnet 中文--https://github.com/ymcui/Chinese-XLNet
一、什么是XLNet?
XLNet是一个类似于BERT的模型,不算是一个全新的模型。它是CMU和Google Brain团队在2019年6月发布的模型,其在20个任务上超过BERT,并且在18个任务上取得了SOTA的效果,包括机器问答、自然语言推断、情感分析和文档排序。作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。这篇新论文中,作者从自回归(autoregressive)和自编码(autoencoding)两大范式分析了当前的预训练语言模型,并发现它们虽然各自都有优势,但也都有难以解决的困难。为此,研究者提出XLNet,并希望结合大阵营的优秀属性。
二、自回归(autoregressive)和自编码(autoencoding)
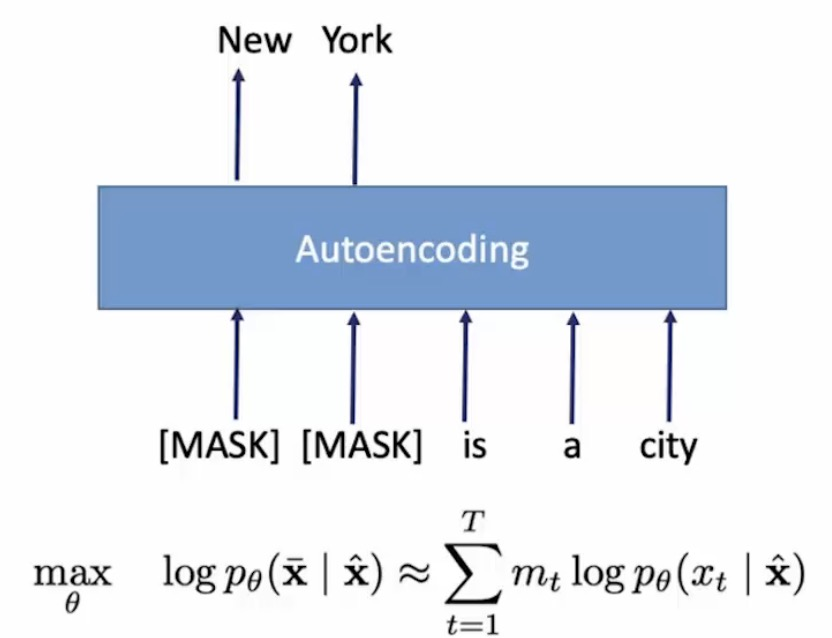
自回归的模型(AutoRegressive LM),是一种使用上下文词来预测下一个词的模型。但是在这里,上下文单词被限制在两个方向,前向或后向。如下图,如果从左到右的话,输入New来预测York,然后用New York来预测 is,预测 is 的时候只能根据其前面的词来进行预测,而不能根据 a , city 这两个词来进行预测。
AutoRegressive LM的代表有:
- 传统的语言模型,根据上文预测下一个词。
- ELMo扩展了语言模型,增加了双向词的预测,上文预测下一个词和下文预测上一个词,但是本质上还是AutoRegressive LM的原理。
- GPT是把AutoRegressive LM发挥到极致的做法,在AutoRegressive LM的基础上,提升预料的质量,加大训练的资源,最终训练出相当不错的效果。
AutoRegressive LM的优点和缺点:
缺点:是只能利用上文或者下文的信息,不能同时利用上文和下文的信息。当然,看似ELMO这种用BiLSTM双向都可以做(这其实算是伪双向模型),然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不会太好。
优点:是符合下游NLP任务语言环境,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程,考虑被预测词之间的依赖关系。相比Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题(训练的时候有Mask,应用的时候没有),导致生成类的NLP任务到目前为止都做不太好

自编码语言模型(AutoEncoder LM),它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文。自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
AutoEncoder LM的优点和缺点:
优点:是能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文。
缺点:是在训练的输入端引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题;没有考虑被预测单词之间的相关性。
三、The XLNet model
XLNet的作者通过把之前的优秀的模型分为AR和AE两类,并且清楚了各自的优势和缺点。在XLNet中,想要结合两边的优势,来提升XLNet的整体的模型的效果。那我们通过上文知道了,AR的优势是预训练和Fine-tuning的数据形式一致,而AE的优势是在预测词的时候,能够很好的融入上下文。
1、排列语言建模(Permutation Language Modeling)
其实作者主要想解决的一个问题就是:我们如何使autoregressive可以双向,也就是同时考虑上下文。下面这张图就是答案,简单来讲就是考虑输入的句子的不同排序,例如:“New York is a city”这句话有五个单词,那么它的排列组合就有5!种。你可能会想如果句子很长呢?比如30个词组成的句子,那我们难道要考虑30!种输入吗,这样计算复杂度就会太大了,在实际训练中使用采样的方法选取其中一部分序列。(注:输入是不会变的,比如上面那句话的输入只会是“New York is a city”,那是如何在训练过程中考虑不同的序列呢?作者的方法就是使用所谓的Attention Mask)


给定长度为T的序列xx,总共有T!种排列方法,也就对应T!种链式分解方法。比如假设x=x1x2x3,那么总共用3!=6种分解方法:
注意p(x2|x1x3)指的是第一个词是x1并且第三个词是x3的条件下第二个词是x2的概率,也就是说原来词的顺序是保持的。如果理解为第一个词是x1并且第二个词是x3的条件下第三个词是x2,那么就不对了。
如果我们的语言模型遍历T!种分解方法,并且这个模型的参数是共享的,那么这个模型应该就能(必须)学习到各种上下文。普通的从左到右或者从右往左的语言模型只能学习一种方向的依赖关系,比如先”猜”一个词,然后根据第一个词”猜”第二个词,根据前两个词”猜”第三个词,……。而排列语言模型会学习各种顺序的猜测方法,比如上面的最后一个式子对应的顺序3→1→2,它是先”猜”第三个词,然后根据第三个词猜测第一个词,最后根据第一个和第三个词猜测第二个词。
因此我们可以遍历T!种路径,然后学习语言模型的参数,但是这个计算量非常大(10!=3628800,10个词的句子就有这么多种组合)。因此实际我们只能随机的采样T!里的部分排列。
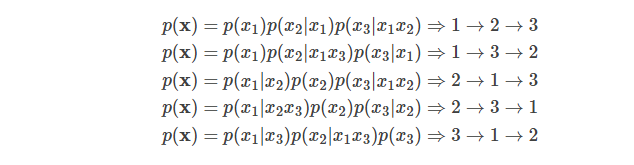
2、双流自注意力机制(Tow-stream Attention)和Attention Mask
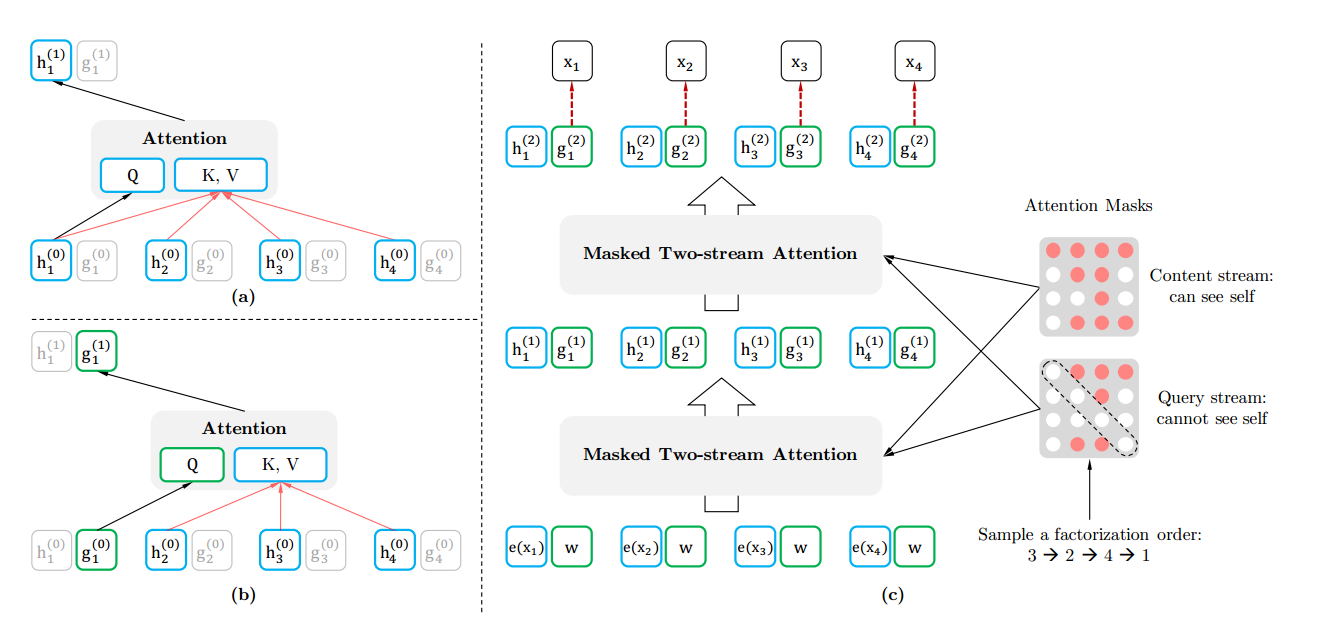
XLNet把Bert的[Mask]的过程搬到Attention Mask来完成。这样从输入端看去预训练和Fine-tuning是一致的。Attention Mask的原理是,假设输入的词是x1−>x2−>x3−>x4x1−>x2−>x3−>x4,我们在Attention Mask中改成随机排列组合的另外一个顺序x3−>x2−>x4−>x1x3−>x2−>x4−>x1了,然后预测x3x3的时候上文为空,预测x2x2的时候上文是x3x3,预测x4x4的时候上文是x3,x2x3,x2,预测x1x1的时候上文是x3,x2,x4x3,x2,x4,这样就达到了预测一个词使用到了上下文的内容。
在Attention Mask中实现的原理路下图:其实真是的词的顺序没有变,只是通过mask的操作达到了类似随机排序的效果。
Tow-stream Attention 是什么意思呢?首先我们可以想为什么要用Tow-stream Attention?那当然是为了解决什么问题,比如句子序列是“New York is a city”, 我们现在预测“York”,那我们需要单词”New“的内容信息和位置信息,和”York“本身的位置信息;预测“is”,那我们需要单词”New“和"York"的内容信息和位置信息,和”is“本身的位置信息。也就是对于每个词我们有时候只要位置信息,有时候位置信息和内容信息都要。作者为了解决这个问题就提出了Tow-stream Attention,为每个单词都定义两个输出 h(包含内容和位置信息)和 g(只包含位置信息),然后用两个不同的Attention Mask,如下图所示,一个考虑词本身一个不考虑词本身。
四、XLNet与BERT对比
XLNet和BERT都是预测一个句子的部分词,但是背后的原因是不同的。BERT使用的是Mask语言模型,因此只能预测部分词(总不能把所有词都Mask了然后预测?)。而XLNet预测部分词是出于性能考虑,而BERT是随机的选择一些词来预测。
除此之外,它们最大的区别其实就是BERT是约等号,也就是条件独立的假设——那些被MASK的词在给定非MASK的词的条件下是独立的。但是我们前面分析过,这个假设并不(总是)成立。下面我们通过一个例子来说明(其实前面已经说过了,理解的读者跳过本节即可)。
假设输入是[New, York, is, a, city],并且假设恰巧XLNet和BERT都选择使用[is, a, city]来预测New和York。同时我们假设XLNet的排列顺序为[is, a, city, New, York]。那么它们优化的目标函数分别为:
从上面可以发现,XLNet可以在预测York的使用利用New的信息,因此它能学到”New York”经常出现在一起而且它们出现在一起的语义和单独出现是完全不同的。
五、总结
XLNet 的成功来自于三点:
分布式语义假设的有效性,即我们确实可以从语料的统计规律中习得常识及语言的结构。
对语境更加精细的建模:从"单向"语境到"双向"语境,从"短程"依赖到"长程"依赖,XLNet 是目前对语境建模最精细的模型。
在模型容量足够大时,数据量的对数和性能提升在一定范围内接近正比,XLNet 使用的预训练数据量可能是公开模型里面最大的。