B+树索引
(这里只写了对于数据库做题有帮助的部分B+树内容)
B+树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。在数据库中,B+树叶子结点的上层都是索引,为了方便查找,不涉及记录的地址,每个叶子结点存放相应的记录,也就是元组。并且元组按键值有序排放,即按照有B+树索引的属性值有序排放。
B+树上的查找类似于二叉排序树的查找,跟二分法是一致的。
通过一下例子,说明一下在B+树索引下的查找。
【例】
SELECT * FROM Student WHERE Sage > 20;
假定Sage上有B+树索引。
①使用B+树索引找到Sage = 20的索引项
②通过这个索引项在B+树的顺序集上找到Sage > 20的所有元组指针
③通过这些指针读取到Student表中的所有年龄大于20的学生记录
读写总块数:对B+树扫描时,对该检索路径上每个结点的读写块数+最终读取的Student表中满足条件元组的块数
很明显,与直接读取再做选择相比,大大降低了读写的块数。


第2题中涉及的主要是估算磁盘读写的块数,在课本288页,有一些代价估算的公式,有些可以理解,有些比较难理解,就直接拿来用了。
代价估算(按照课本整合)
1.全表扫描 cost = 基本表大小块数B
2.B+树索引扫描
(1)选择条件中为“码 = 值”
码唯一标识元组,B+树层数为L cost = L+1;
(2)选择条件涉及非码属性
结果不唯一 cost = L+S(满足条件元组数)
3.嵌套循环连接
我不太理解书上的公式。涉及这个算法,还是参照281页的示例,比较好理解。注意连接结果一般需要写进中间文件,要加上对中间文件的读写。
4.排序合并连接
有序:cost = 两个表个扫描一遍块数 + 中间文件(连接结果)读写块数
无序:在有序的条件上在加上排序代价。
包含B个块的文件排序代价 = (2B)+(2B*log
B)
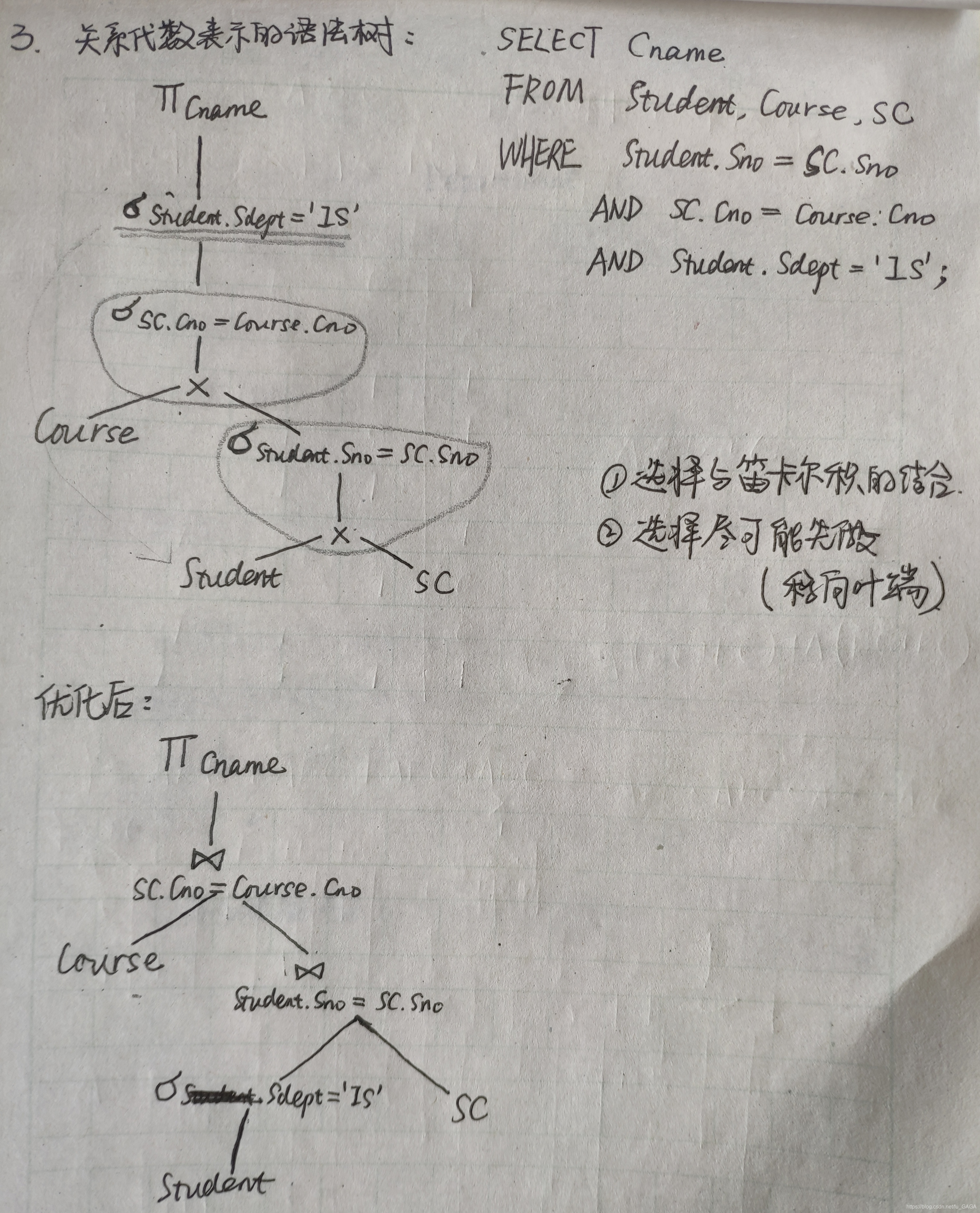


查询优化
1.代数优化(作业3,5题)
借助优化工具:查询树
①语法树——②初始关系代数语法树——③根据规则优化查询树
总结常用规则(题中主要涉及的规则):
①将选择和下面的笛卡尔积合并为连接
②将涉及单个表的选择或投影下移到叶子端直接与相应的表相连
2.物理优化(作业4题)
选择高效合理的操作算法或存取路径。涉及到代价估算(作业2题)
相应的操作算法:
选择操作:①全表扫描 ②索引扫描
连接操作:①嵌套循环 ②排序合并 ③索引连接
【心得】在估算磁盘读写块数时,有些乱,在优化查询树的时候,很多规则,不知道从哪下手。感觉这章内容有些松散,有些乱。作业题与前面的例题相似,参照着例题做,没有很难,时间也没有很长。
