电话面
面的太惨了,好多都不会。。现在大致记录一下问题。(这家公司不问你xxx有啥区别,就是直接让你说一说xxx,感觉难度更高。)
1.B树和B+树的区别。
1)关于m阶B树,满足以下基本条件:
每个节点最多有m-1个关键字。
根节点最少可以只有1个关键字。非根节点至少有
个关键字。
每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小
于它,而右子树中的所有关键字都大于它。
所有叶子节点都位于同一层,即根节点到每个叶子节点的长度都相同。
每个节点都存有索引和数据,也就是对应的key和value。
即根节点的关键字数量范围: 1 <= k <= m-1,非根节点的关键字数量范围:
<= k <= m-1。
2)关于B+树,大体上和B树是相似的。下面是不同之处。
①B+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。这样一来,所有的叶子节点包含了全部元素的信息,及指向含这些元素记录的指针。(索引和数据)
②所有的叶子节点本身依关键字的大小自小而大顺序连接。
③有k个子树的中间节点包含有k个元素,而B树是k-1个元素。
因为有这些限制,使得B树有一些全新的性质。因为①,同样大小的磁盘页可以容纳更多的节点元素,这意味着,相同数据量的情况下,用B+树的话,IO查询次数更少。另外,因为B树的查询性能不稳定,(有时需要查询到叶子节点,有时又只需要查询到根节点即可。)因为②,B+树在做范围查询的时候,只需要沿着叶子节点的链表查询就可以。而B树需要做中序遍历,很麻烦。
3)关于B*树。
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针。(就是对于中间的那部分,每一行的元素顺序连接起来)
如图所示,图片源自网络:
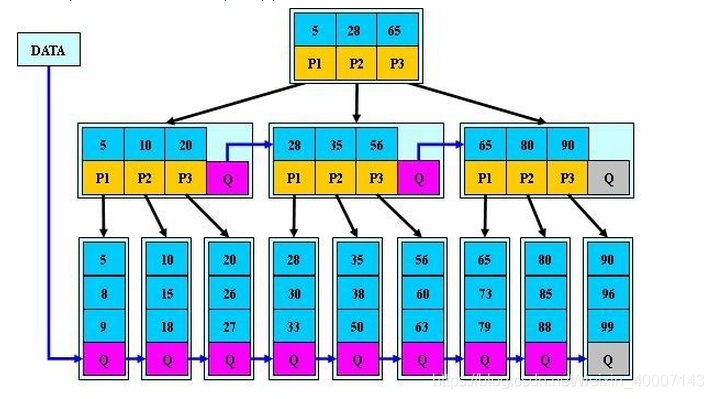
同时,B*树要求每个节点至少有2/3m个关键字,比B+树的空间利用率高。
2.lambda表达式。
/*
学习lambda表达式。
2020.3.28 20:36
2020.3.31 21:56
2020.4.1 8:39
*/
/*
lambda表达式的格式如下:
[capture list] (params list) -> return type {function body}
[]里面的是东西是捕获的变量,这部分的具体介绍参见第二部分。
实际使用时,按需,可以省略部分内容,至少必须有捕获列表和函数体。
*/
//1
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
//bool cmp(int a, int b)
//{
// return a < b;
//}
////从小到大排序。
//
//int main()
//{
// vector<int> myvec{ 3, 2, 5, 7, 3, 2 };
// vector<int> lbvec(myvec);
//
// sort(myvec.begin(), myvec.end(), cmp); // 旧式做法
// cout << "predicate function:" << endl;
// //使用谓词函数的方法。
// for (int it : myvec)
// cout << it << ' ';
// cout << endl;
//
// sort(lbvec.begin(), lbvec.end(), [](int a, int b) -> bool { return a < b; }); // Lambda表达式
// cout << "lambda expression:" << endl;
// for (int it : lbvec)
// cout << it << ' ';
//}
//2
//关于前面的捕获变量的内容,再来做一些补充。
//捕获又分多种方式。分为值捕获、引用捕获、隐式捕获。
int main()
{
//1.值捕获。
//前提是这个变量是可以拷贝的。这里的拷贝发生在lambda表达式创建时。而不是调用时的拷贝。
//int a = 123;
//auto f = [a] { cout << a << endl; };//这里的lambda表达式就省略了很多。
//a = 321;
//f(); // 输出:123
//2.引用捕获。
//有时我们无法拷贝这个对象,可以使用引用捕获。但是必须保证lambda表达式执行时,这个对象是存在的。
//int a = 123;
//auto f = [&a] { cout << a << endl; };
//a = 321;
//f(); // 输出:321 也就是说这里的,发生在调用的时候。
//3.1.隐式捕获。
//int a = 123;
//auto f = [=] { cout << a << endl; }; // 值捕获
////隐式的,这种隐式的是默认的值捕获。
//a = 321;
//f(); // 输出:123
////3.2.隐式捕获。
//int a = 123;
//auto f = [&] { cout << a << endl; }; // 引用捕获
//a = 321;
//f(); // 输出:321
////静态变量。不需要捕获,直接就可以使用。
//static int a = 123;
//auto f = [] { cout << a << endl; };//这里的lambda表达式就省略了很多。
//f(); // 输出:123
return 0;
}
3.左值、右值、右值引用。
①.在C++11扩展了右值的的概念,将右值分为了纯右值(pure rvalue)与将亡值(expiring Value)。纯右值的概念等同于我们之前所理解的右值,指的是临时变量或字面量值;而将亡值是C++11新引入的概念,它依托于右值。
②.左值(left value,lvalue)和将亡值(expiring value,xvalue)合称泛左值(generalized lvalue,glvalue)。
③.
④.左值引用,右值引用。
参考的博客
参考的知乎回答
左值引用要求右边的值必须能够取地址,如果无法取地址,可以用常引用。但使用常引用后,我们只能通过引用来读取数据,无法去修改数据,因为其被const修饰成常量引用了。
为了解决这个问题,引入了右值引用。
#include<iostream>
using namespace std;
//class Stack
//{
//public:
// // 构造
// Stack(int size = 1000)
// :msize(size), mtop(0)
// {
// cout << "Stack(int)" << endl;
// mpstack = new int[size];
// }
//
// // 析构
// ~Stack()
// {
// cout << "~Stack()" << endl;
// delete[]mpstack;
// mpstack = nullptr;
// }
//
// // 拷贝构造
// Stack(const Stack& src)
// :msize(src.msize), mtop(src.mtop)
// {
// cout << "Stack(const Stack&)" << endl;
// mpstack = new int[src.msize];
// for (int i = 0; i < mtop; ++i) {
// mpstack[i] = src.mpstack[i];
// }
// }
//
// // 赋值重载
// Stack& operator=(const Stack& src)
// {
// cout << "operator=" << endl;
// if (this == &src)
// return *this;
// delete[]mpstack;
// msize = src.msize;
// mtop = src.mtop;
// mpstack = new int[src.msize];
// for (int i = 0; i < mtop; ++i) {
// mpstack[i] = src.mpstack[i];
// }
// return *this;
// }
//
// int getSize()
// {
// return msize;
// }
//private:
// int* mpstack;
// int mtop;
// int msize;
//};
//
//Stack GetStack(Stack& stack)
//{
// Stack tmp(stack.getSize());
// return tmp;
//}
/*
Stack(int) 构造s
Stack(int) 构造tmp
Stack(const Stack&) 将tmp赋值给GetStack函数返回值temp1
~Stack() tmp析构
operator= 临时对象赋值给s
~Stack() temp1析构
~Stack() s析构
*/
class Stack
{
public:
// 构造
Stack(int size = 1000)
:msize(size), mtop(0)
{
cout << "Stack(int)" << endl;
mpstack = new int[size];
}
// 析构
~Stack()
{
cout << "~Stack()" << endl;
delete[]mpstack;
mpstack = nullptr;
}
// 带右值引用参数的拷贝构造函数
Stack(Stack&& src)
:msize(src.msize), mtop(src.mtop)
{
cout << "Stack(Stack&&)" << endl;
/*此处没有重新开辟内存拷贝数据,把src的资源直接给当前对象,再把src置空*/
mpstack = src.mpstack;
src.mpstack = nullptr;
}
// 带右值引用参数的赋值运算符重载函数
Stack& operator=(Stack&& src)
{
cout << "operator=(Stack&&)" << endl;
if (this == &src)
return *this;
delete[]mpstack;
msize = src.msize;
mtop = src.mtop;
/*此处没有重新开辟内存拷贝数据,把src的资源直接给当前对象,再把src置空*/
mpstack = src.mpstack;
src.mpstack = nullptr;
return *this;
}
int getSize()
{
return msize;
}
private:
int* mpstack;
int mtop;
int msize;
};
Stack GetStack(Stack& stack)
{
Stack tmp(stack.getSize());
return tmp;
}
int main()
{
Stack s;
s = GetStack(s);
return 0;
}
/*
Stack(int)
Stack(int)
Stack(Stack&&)
~Stack()
operator=(Stack&&)
~Stack()
~Stack()
*/
//带右值引用参数的拷贝构造和赋值重载函数,又叫移动构造函数和移动赋值函数
⑤.最后使用模板实现完美转发就可以避免需要各写一遍左值引用和右值引用。
//上面的例子可以这么写,之后&&不再表示右值引用。而表示万能引用。这种用法称为完美转发。
template<class T>
Stack(T&& src)
:msize(src.msize), mtop(src.mtop)
{
cout << "Stack(Stack&&)" << endl;
/*此处没有重新开辟内存拷贝数据,把src的资源直接给当前对象,再把src置空*/
mpstack = src.mpstack;
src.mpstack = nullptr;
}
4.new和malloc不一样的地方。
(这部分参考的这篇博客。)
①. 申请的内存所在位置不同:new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。(自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。)那么自由存储区是否能够是堆(问题等价于new是否能在堆上动态分配内存),这取决于operator new 的实现细节。自由存储区不仅可以是堆,还可以是静态存储区,这都看operator new在哪里为对象分配内存。
②.返回类型安全性:new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回
* ,需要通过强制类型转换将
* 指针转换成我们需要的类型。
③.内存分配失败时的返回值:new内存分配失败时,会抛出bac_alloc异常,它不会返回NULL;malloc分配内存失败时返回NULL。
int *a = (int *)malloc ( sizeof (int ));
if(NULL == a)
{
...
}
else
{
...
}
try
{
int *a = new int();
}
catch (bad_alloc)
{
...
}
④.是否需要指定内存大小:使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的尺寸。
⑤.是否调用构造函数/析构函数:new/delete会调用对象的构造函数/析构函数以完成对象的构造/析构。而malloc则不会。
⑥.是否可以被重载:opeartor new /operator delete可以被重载。而malloc/free并不允许重载。
⑦.能够直观地重新分配内存:使用malloc分配的内存后,如果在使用过程中发现内存不足,可以使用realloc函数进行内存重新分配实现内存的扩充。realloc先判断当前的指针所指内存是否有足够的连续空间,如果有,原地扩大可分配的内存地址,并且返回原来的地址指针;如果空间不够,先按照新指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来的内存区域。
new没有这样直观的类似方法来扩充内存。
5.struct和class的区别。
在C++中,struct得到了很大的发展,再也不是C中的那个struct了。
在C中,struct仅仅是一种包含不同数据类型的数据结构。
在C++中,struct能包含成员函数,struct能继承,struct能实现多态。
①.最本质的区别是默认的访问权限不同。struct定义的数据默认是public的,class定义的数据默认是private.
②. 1.)class和struct如果定义了构造函数的话,都不能用大括号进行初始化
2.)如果没有定义构造函数,struct可以用大括号初始化。
3.)如果没有定义构造函数,且所有成员变量全是public的话,class可以用大括号初始化。
/*
验证struct和class的区别。
2020.4.2 18:46
*/
#include<iostream>
using namespace std;
//struct A //定义一个struct
//{
// char c1;
// int n2;
// double db3;
// A() {}
//};
//A a = { 'p', 7, 3.1415926 }; //定义时直接赋值,未定义构造函数时,是可以的。定义了构造函数之后,就不可以了。
class B
{
public:
char c1;
int n2;
double db3;
};
B b = { 'p', 7, 3.1415926 }; //定义时直接赋值。未定义构造函数,且为public的。可以。
int main() {
return 0;
}
6.const成员函数和非const成员函数。
1)const对象调用const成员函数,而不能调用非const成员函数。
2)有const修饰的成员函数,只能读取数据成员,而不能写数据成员。
3)非const对象可以调用const成员函数,也可以调用非const成员函数。默认调用的是非const成员函数。
4)const成员函数可以访问非const对象内的所有数据成员,也可以访问const对象内的所有数据成员。
5)非const成员函数只可以访问非const对象的任意的数据成员。
7.C++类的初始化列表。
哪些时候必须使用带有初始化列表的构造函数?
/*
探讨含有初始化列表的构造函数。
*/
#include <iostream>
using namespace std;
//class A
//{
// int a;
// float b;
//public:
// A() : a(0), b(9.9) {} //构造函数初始化列表
//};
//有些时候必须使用初始化列表:(1)没有默认构造函数的成员类对象;(2)const成员或引用类型的成员。
//(1)
//class A
//{
//public:
// A(int x)
// {
// i = x;
// }
//private:
// int i;
//};
//class B
//{
//public:
// B(int y,int z):a(z)
// {
// j = y;
// }
//private:
// A a; //因为A没有一个默认的构造函数。所以在这里,B的构造函数必须要使用初始化列表,不然没法初始化a.
// int j;
//};
//int main()
//{
// B b(5,10);
// return 0;
//}
//(2)因为const的变量和引用变量只能初始化,不能赋值。
class A
{
public:
A(int x, int y) : c(x), j(y) // 构造函数初始化列表。这样的话,就算是对c和j初始化。不算是赋值。。。
{
i = -1;
}
private:
int i;
const int c;
int& j;
};
int main()
{
int m = 0;
A a(5, m);
return 0;
}
8.自己想到的几个还不会的问题,this指针。动态绑定。
1)this指针:指的是当前的对象。
2)动态绑定:也就是多态性。
(代码来自菜鸟教程)
有两个条件:
①基类的相应函数必须设置为虚函数。
②必须通过基类类型的引用或指针进行函数调用。
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0)
{
width = a;
height = b;
}
virtual int area() //①
{
cout << "Parent class area :" << endl;
return 0;
}
};
class Rectangle : public Shape {
public:
Rectangle(int a = 0, int b = 0) :Shape(a, b) { }
int area()
{
cout << "Rectangle class area :" << endl;
return (width * height);
}
};
class Triangle : public Shape {
public:
Triangle(int a = 0, int b = 0) :Shape(a, b) { }
int area()
{
cout << "Triangle class area :" << endl;
return (width * height / 2);
}
};
// 程序的主函数
int main()
{
Shape* shape;
Rectangle rec(10, 7);
Triangle tri(10, 5);
// 存储矩形的地址
shape = &rec; //②
// 调用矩形的求面积函数 area
shape->area();
// 存储三角形的地址
shape = &tri;
// 调用三角形的求面积函数 area
shape->area();
shape->Shape::area(); //要想访问基类的函数,可以这样强制定向。
return 0;
}
凉了。

