自己这几天在看Redis的Sentinel高可用解决方案,Sentinel选主使用的是著名的Raft一致性算法,本文对Raft的选主作了介绍,具体的算法内容,请参考 Raft 论文
Raft的整体结构
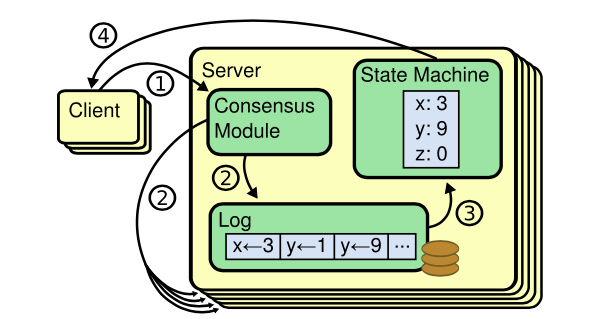
Raft 通过选举一个高贵的领导人,然后给予他全部的管理复制日志的责任来实现一致性。
而每个 server 都可能会在 3 个身份之间切换:
- 领导者
- 候选者
- 跟随者
而影响他们身份变化的则是 选举。
当所有服务器初始化的时候,都是 跟随者,这个时候需要一个 领导者,所有人都变成 候选者,直到有人成功当选 领导者。
角色轮换如下图:

而领导者也有宕机的时候,宕机后引发新的 选举,所以,整个集群在选举和正常运行之间切换,具体如下图:

从上图可以看出,选举和正常运行之间切换,但请注意, 上图中的 term 3 有一个地方,后面没有跟着 正常运行 阶段,为什么呢?
答:当一次选举失败(比如正巧每个人都投了自己),就执行一次 加时赛,每个 Server 会在一个随机的时间里重新投票,这样就能保证不冲突了。所以,当 term 3 选举失败,等了几十毫秒,执行 term 4 选举,并成功选举出领导人。
接着,领导者周期性的向所有跟随者发送心跳包来维持自己的权威。如果一个跟随者在一段时间里没有接收到任何消息,也就是选举超时,那么他就会认为系统中没有可用的领导者,并且发起选举以选出新的领导者。
要开始一次选举过程,跟随者先要增加自己的当前任期号并且转换到候选人状态。然后请求其他服务器为自己投票。那么会产生 3 种结果:
a. 自己成功当选
b. 其他的服务器成为领导者
c. 僵住,没有任何一个人成为领导者
注意:

- 每一个 server 最多在一个任期内投出一张选票(有任期号约束),先到先得。
- 要求最多只能有一个人赢得选票。
- 一旦成功,立即成为领导人,然后广播所有服务器停止投票阻止新得领导产生。
僵住怎么办? Raft 通过使用随机选举超时时间(例如 150 - 300 毫秒)的方法将服务器打散投票。每个候选人在僵住的时候会随机从一个时间开始重新选举。
以上,就是 Raft 算法对选主的介绍,非常简短,具体的还是要看一边论文才能搞清楚,直接看代码基本看不懂。
实现代码
我在网上看到的都是golang语言的实现,作为一个Java程序员想找到一份Java的实现真难啊,蚂蚁金服开源了他们的JRaft实现,可是毕竟实现的非常完美,代码就有点难看懂了。
启动类就是做一下对自身节点的ip port的包装,
public class RaftNodeBootStrap {
public static void main(String[] args) throws Throwable {
main0();
}
public static void main0() throws Throwable {
String[] peerAddr = {"localhost:8775","localhost:8776","localhost:8777", "localhost:8778", "localhost:8779"};
NodeConfig config = new NodeConfig();
// 自身节点
config.setSelfPort(Integer.valueOf(System.getProperty("serverPort")));
// 其他节点地址
config.setPeerAddrs(Arrays.asList(peerAddr));
Node node = DefaultNode.getInstance();
node.setConfig(config);
node.init();
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
try {
node.destroy();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}));
}
重点在node.setConfig() 和init()两个方法
@Override
public void setConfig(NodeConfig config) {
this.config = config;
stateMachine = DefaultStateMachine.getInstance();
logModule = DefaultLogModule.getInstance();
peerSet = PeerSet.getInstance();
for (String s : config.getPeerAddrs()) {
Peer peer = new Peer(s);
peerSet.addPeer(peer);
if (s.equals("localhost:" + config.getSelfPort())) {
peerSet.setSelf(peer);
}
}
RPC_SERVER = new DefaultRpcServer(config.selfPort, this);
}
init对自己的同伴节点做初始化,最后一行,开启了一个RPCServer,RPCServer的功能看过Raft论文的应该都清楚,接收投票RPCVoteRequest, 和附加日志 RPCLogAppendRequest (心跳也是日志附加Request,只是日志内容为null)
public void init() throws Throwable {
if (started) {
return;
}
synchronized (this) {
if (started) {
return;
}
RPC_SERVER.start();
consensus = new DefaultConsensus(this);
delegate = new ClusterMembershipChangesImpl(this);
RaftThreadPool.scheduleWithFixedDelay(heartBeatTask, 500);
RaftThreadPool.scheduleAtFixedRate(electionTask, 6000, 500);
RaftThreadPool.execute(replicationFailQueueConsumer);
LogEntry logEntry = logModule.getLast();
if (logEntry != null) {
currentTerm = logEntry.getTerm();
}
started = true;
LOGGER.info("start success, selfId : {} ", peerSet.getSelf());
}
}
init() 方法表示, 每个节点在启动的时候启动RPC_SERVER,初始化,一致性模块consensus, 初始化集群成员变更模块 delegate, 使用schedulePool调度 心跳任务,和选举任务。replicationFailQueueConsumer可以先不用管。
consensus和delegate都是使用KV数据库实现的(这里使用的RocksDB), 大家只要明白是做数据持久化的就OK了。
class HeartBeatTask implements Runnable {
@Override
public void run() {
if (status != LEADER) {
return;
}
long current = System.currentTimeMillis();
if (current - preHeartBeatTime < heartBeatTick) {
return;
}
LOGGER.info("=========== NextIndex =============");
for (Peer peer : peerSet.getPeersWithOutSelf()) {
LOGGER.info("Peer {} nextIndex={}", peer.getAddr(), nextIndexs.get(peer));
}
preHeartBeatTime = System.currentTimeMillis();
// 心跳只关心 term 和 leaderID
for (Peer peer : peerSet.getPeersWithOutSelf()) {
AentryParam param = AentryParam.newBuilder()
.entries(null)// 心跳,空日志.
.leaderId(peerSet.getSelf().getAddr())
.serverId(peer.getAddr())
.term(currentTerm)
.build();
Request<AentryParam> request = new Request<>(
Request.A_ENTRIES,
param,
peer.getAddr());
RaftThreadPool.execute(() -> {
try {
Response response = getRpcClient().send(request);
AentryResult aentryResult = (AentryResult) response.getResult();
long term = aentryResult.getTerm();
if (term > currentTerm) {
LOGGER.error("self will become follower, he's term : {}, my term : {}", term, currentTerm);
currentTerm = term;
votedFor = "";
status = NodeStatus.FOLLOWER;
}
} catch (Exception e) {
LOGGER.error("HeartBeatTask RPC Fail, request URL : {} ", request.getUrl());
}
}, false);
}
}
}
心跳任务的代码,也很简单,只有在是Leader的状态的时候,才会像自己的同伴节点发送心跳。
重点是选举任务的实现。
/**
* 1. 在转变成候选人后就立即开始选举过程
* 自增当前的任期号(currentTerm)
* 给自己投票
* 重置选举超时计时器
* 发送请求投票的 RPC 给其他所有服务器
* 2. 如果接收到大多数服务器的选票,那么就变成领导人
* 3. 如果接收到来自新的领导人的附加日志 RPC,转变成跟随者
* 4. 如果选举过程超时,再次发起一轮选举
*/
class ElectionTask implements Runnable {
@Override
public void run() {
if (status == LEADER) {
return;
}
long current = System.currentTimeMillis();
// 基于 RAFT 的随机时间,解决冲突.
electionTime = electionTime + ThreadLocalRandom.current().nextInt(50);
if (current - preElectionTime < electionTime) {
return;
}
status = NodeStatus.CANDIDATE;
LOGGER.error("node {} will become CANDIDATE and start election leader, current term : [{}], LastEntry : [{}]",
peerSet.getSelf(), currentTerm, logModule.getLast());
preElectionTime = System.currentTimeMillis() + ThreadLocalRandom.current().nextInt(200) + 150;
currentTerm = currentTerm + 1;
// 推荐自己.
votedFor = peerSet.getSelf().getAddr();
List<Peer> peers = peerSet.getPeersWithOutSelf();
ArrayList<Future> futureArrayList = new ArrayList<>();
LOGGER.info("peerList size : {}, peer list content : {}", peers.size(), peers);
// 向所有的同伴 发送请求
for (Peer peer : peers) {
futureArrayList.add(RaftThreadPool.submit(new Callable() {
@Override
public Object call() throws Exception {
long lastTerm = 0L;
LogEntry last = logModule.getLast();
if (last != null) {
lastTerm = last.getTerm();
}
RvoteParam param = RvoteParam.newBuilder().
term(currentTerm).
candidateId(peerSet.getSelf().getAddr()).
lastLogIndex(LongConvert.convert(logModule.getLastIndex())).
lastLogTerm(lastTerm).
build();
Request request = Request.newBuilder()
.cmd(Request.R_VOTE)
.obj(param)
.url(peer.getAddr())
.build();
try {
@SuppressWarnings("unchecked")
Response<RvoteResult> response = getRpcClient().send(request);
return response;
} catch (RaftRemotingException e) {
LOGGER.error("ElectionTask RPC Fail , URL : " + request.getUrl());
return null;
}
}
}));
}
AtomicInteger success2 = new AtomicInteger(0);
CountDownLatch latch = new CountDownLatch(futureArrayList.size());
LOGGER.info("futureArrayList.size() : {}", futureArrayList.size());
// 等待结果.
for (Future future : futureArrayList) {
RaftThreadPool.submit(new Callable() {
@Override
public Object call() throws Exception {
try {
@SuppressWarnings("unchecked")
Response<RvoteResult> response = (Response<RvoteResult>) future.get(3000, MILLISECONDS);
if (response == null) {
return -1;
}
boolean isVoteGranted = response.getResult().isVoteGranted();
if (isVoteGranted) {
success2.incrementAndGet();
} else {
// 更新自己的任期.
long resTerm = response.getResult().getTerm();
if (resTerm >= currentTerm) {
currentTerm = resTerm;
}
}
return 0;
} catch (Exception e) {
LOGGER.error("future.get exception , e : ", e);
return -1;
} finally {
latch.countDown();
}
}
});
}
try {
// 稍等片刻
latch.await(3500, MILLISECONDS);
} catch (InterruptedException e) {
LOGGER.warn("InterruptedException By Master election Task");
}
int success = success2.get();
LOGGER.info("node {} maybe become leader , success count = {} , status : {}", peerSet.getSelf(), success, NodeStatus.Enum.value(status));
// 如果投票期间,有其他服务器发送 appendEntry , 就可能变成 follower ,这时,应该停止.
if (status == NodeStatus.FOLLOWER) {
return;
}
// 加上自身.
if (success >= peers.size() / 2) {
LOGGER.warn("node {} become leader ", peerSet.getSelf());
status = LEADER;
peerSet.setLeader(peerSet.getSelf());
votedFor = "";
becomeLeaderToDoThing();
} else {
// else 重新选举
votedFor = "";
}
}
}
因为一个节点在一个term中只能投一票,如果在随机事件内,收集到了过半的投票,就可以把自己置为Leader,并开始发送心跳日志,从而阻止其他节点的投票行为。
这一点是在RPCServer的handlerRequest()中实现的,也就是前文中 RPC_SERVER.start(); 这行代码。
@Override
public Response handlerRequest(Request request) {
if (request.getCmd() == Request.R_VOTE) {
return new Response(node.handlerRequestVote((RvoteParam) request.getObj()));
} else if (request.getCmd() == Request.A_ENTRIES) {
return new Response(node.handlerAppendEntries((AentryParam) request.getObj()));
} else if (request.getCmd() == Request.CLIENT_REQ) {
return new Response(node.handlerClientRequest((ClientKVReq) request.getObj()));
} else if (request.getCmd() == Request.CHANGE_CONFIG_REMOVE) {
return new Response(((ClusterMembershipChanges) node).removePeer((Peer) request.getObj()));
} else if (request.getCmd() == Request.CHANGE_CONFIG_ADD) {
return new Response(((ClusterMembershipChanges) node).addPeer((Peer) request.getObj()));
}
return null;
}
@Override
public RvoteResult handlerRequestVote(RvoteParam param) {
LOGGER.warn("handlerRequestVote will be invoke, param info : {}", param);
return consensus.requestVote(param);
}
这里就开始使用到我们定义的一致性模块的实现。
@Override
public RvoteResult requestVote(RvoteParam param) {
try {
RvoteResult.Builder builder = RvoteResult.newBuilder();
if (!voteLock.tryLock()) {
return builder.term(node.getCurrentTerm()).voteGranted(false).build();
}
// 对方任期没有自己新
if (param.getTerm() < node.getCurrentTerm()) {
return builder.term(node.getCurrentTerm()).voteGranted(false).build();
}
// (当前节点并没有投票 或者 已经投票过了且是对方节点) && 对方日志和自己一样新
LOGGER.info("node {} current vote for [{}], param candidateId : {}", node.peerSet.getSelf(), node.getVotedFor(), param.getCandidateId());
LOGGER.info("node {} current term {}, peer term : {}", node.peerSet.getSelf(), node.getCurrentTerm(), param.getTerm());
if ((StringUtil.isNullOrEmpty(node.getVotedFor()) || node.getVotedFor().equals(param.getCandidateId()))) {
if (node.getLogModule().getLast() != null) {
// 先比较term,term大的优先级大
if (node.getLogModule().getLast().getTerm() > param.getLastLogTerm()) {
return RvoteResult.fail();
}
// term >= 自己,再比较lastLogIndex
if (node.getLogModule().getLastIndex() > param.getLastLogIndex()) {
return RvoteResult.fail();
}
}
// 切换状态
node.status = NodeStatus.FOLLOWER;
// 更新
node.peerSet.setLeader(new Peer(param.getCandidateId()));
node.setCurrentTerm(param.getTerm());
node.setVotedFor(param.serverId);
// 返回成功
return builder.term(node.currentTerm).voteGranted(true).build();
}
return builder.term(node.currentTerm).voteGranted(false).build();
} finally {
voteLock.unlock();
}
}
对于接收到的 , 请求投票 RPC
* 如果term < currentTerm返回 false (5.2 节)
* 如果 votedFor 为空或者就是 candidateId,并且候选人的日志至少和自己一样新,那么就投票给他(5.2 节,5.4节)
这也是Raft算法保证安全性的地方,在非拜占庭条件下(包括网络延迟,分区和数据包丢失,重复和乱序)也是正确的。
至此,选主环节就实现了,当然文中出现的都是关键代码,具体参数中的Entity类和interface大家可以去我的github中看到完整的代码。
全部代码都上传到Github, 欢迎Star
参考文章
莫那 鲁道的博客
Raft中文翻译
Raft讲解
