CRUD并不足够
在之前学习中,使用了通用仓库接口GenericRepository,并通过GenericBaseRepository,GenericJpaRepository来具体实现,实现上对于CRUD而言,这类的实现大同小异,此外,我们还需要根据UNIQUE KEY或者KEY去进行查询,而不仅仅使用primary key,还有根据多个条件去进行查询或者检索,对返回的结果进行分页等等。GenericRepository提供的基础CRUD是不足够的。
这些接口的实现是比较繁琐的,我们以分页为例。如果我们需要获取能够分多少页,就需要获取总数,代码如下:
@PersistenceContext private EntityManager entityManager;
@Override
public Long count(Predicate ... restrictions) {
CriteriaBuilder builder = this.entityManager.getCriteriaBuilder();
CriteriaQuery<Long> countCriteria = builder.createQuery(Long.class);
Root<TestPage> root = countCriteria.from(TestPage.class);
TypedQuery<Long> countQuery = this.entityManager.createQuery(
countCriteria.select(builder.count(root))
.where(restrictions));
return countQuery.getSingleResult();
}
@Override
public List<TestPage> page(int page, int numPerPage, Predicate ... restrictions) {
CriteriaBuilder builder = this.entityManager.getCriteriaBuilder();
CriteriaQuery<TestPage> criteria = builder.createQuery(TestPage.class);
Root<TestPage> root = criteria.from(TestPage.class);
TypedQuery<TestPage> pagedQuery = this.entityManager.createQuery(
criteria.select(root)
.orderBy(builder.asc(root.get("userName")))
.where(restrictions));
//【注意】setFristResult:position of the first result, numbered from 0,这个自动分配的id号从1开始不一样
return pagedQuery.setFirstResult((page -1) *numPerPage).setMaxResults(numPerPage).getResultList();
}
我们可以将这两个方法写成通用的代码加入到GenericJpaRepository中,但在获取分页的信息时,可能指定某种或者某些排序,也可以需要进行过滤,也就是在例子中的where(restrictions),这使得调用方陷入到JPA的代码中,如果根据具体场景具体化,可能需要为很多Entity的仓库添加代码,无法做到通用。
Spring Data的作用
仓库的代码不包含任何的业务逻辑(在Service),也不包含UI(在Controller),是可以通用的样板代码。Spring Data它是独立于Spring framework的一个项目。程序员只需定义接口,Spring Data在runtime时可以动态生成所需的仓库代码。
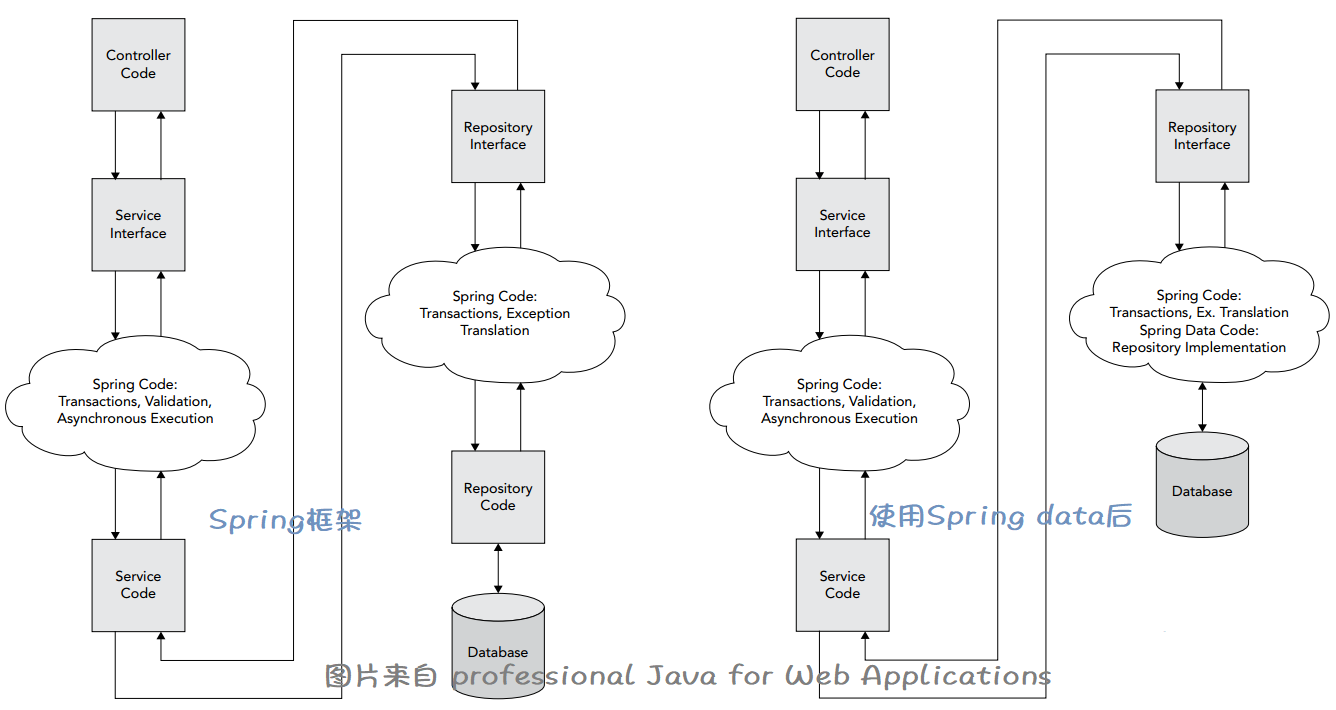
Spring Data支持JPA,JdbcTemplate,NoSQL等,包含所有这些是Spring Data Commons,我们也可以只选择实现JAP的部分,即Spring Data JPA。
简单小例子
Pom的引入
<!-- 在我们的小实验中,spring-data-jpa不能使用2的版本,注入出现异常 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.11.10.RELEASE<version>
</dependency>
如果我们希望使用spring data jpa 2的版本(例如2.0.5.RELEASE),就需要升级spring framework至5.x,而spring framework 5.x要求javax.servlet是4.0的。
在上下文配置Spring data
只需加上@EnableJpaRepositories
@EnableJpaRepositories("cn.wei.flowingflying.chapter22.site.repositories")
/* 如果我们在entityManagerFactory和transactionManager中没有使用默认的方法名,需要明确指出
* @EnableJpaRepositories( basePackages = "cn.wei.flowingflying.chapter22.site.repositories"
* entityManagerFactoryRef = "entityManagerFactoryBean", //缺省为entityManagerFactory
* transactionManagerRef = "jpaTransactionManager" ) //缺省为transactionManager
*/
@ComponentScan(
basePackages = "cn.wei.flowingflying.chapter22.site",
excludeFilters = @ComponentScan.Filter({Controller.class, ControllerAdvice.class})
)
public class RootContextConfiguration implements AsyncConfigurer, SchedulingConfigurer{
... ...
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() throws PropertyVetoException{
Map<String, Object> properties = new Hashtable<>();
properties.put("javax.persistence.schema-generation.database.action","none");
properties.put("hibernate.show_sql", "true");
properties.put("hibernate.dialect", "org.hibernate.dialect.MySQL5InnoDBDialect");
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(new HibernateJpaVendorAdapter());
factory.setDataSource(this.springJpaDataSource());
factory.setPackagesToScan("cn.wei.flowingflying.chapter22.site.entity");
factory.setSharedCacheMode(SharedCacheMode.ENABLE_SELECTIVE);
factory.setValidationMode(ValidationMode.NONE);
factory.setJpaPropertyMap(properties);
return factory;
}
@Bean
public PlatformTransactionManager transactionManager() throws PropertyVetoException{
return new JpaTransactionManager(this.entityManagerFactory().getObject());
}
}
仓库接口
既然Spring data可以为我们自动生成代码,那么如何写仓库的接口就成为关键。org.springframework.data.repository.Repository<T, ID extends Serializable>是Spring Data中最基础的接口,没有任何方法,其他的接口都是继承它。T就是Entity的类,ID就是主键的类型。
/* CrudRepository是Spring Data提供的接口增删改查的仓库接口,我们只需继承即可,它将提供下面的接口
* ➤ count()返回long,就是total number
* ➤ delete(T), delete(ID), delete(Iterable<? extends T>), deleteAll()
* ➤ exists(ID)查询ID是否存在,返回boolean
* ➤ findAll(),findAll(Iterable<ID>),均返回Iterable<T>
* ➤ findOne(ID)
* ➤ save(S),其中S是T的继承,可能执行insert,也可能执行update操作,返回S(如果是insert,我们可以从中获取自动分配的ID)
* ➤ save(Iterable<S>),返回Iterable<S>,同样S是T的继承
*/
public interface AuthorRepository extends CrudRepository<Author,Long>{
}
如果我们需要排序或者分页,就要继承org.springframework.data.repository.PagingAndSortingRepository<T, ID extendsSerializable>,提供了:
@Service
public class DefaultBookManager implements BookManager {
@Inject AuthorRepository authorRepository;
@Override
@Transactional
public List<Author> getAuthors() {
// return this.toList(authorRepository.getAll()); //以前的代码
return this.toList(authorRepository.findAll());
}
@Override
@Transactional
public void saveAuthor(Author author) {
/* 以前的代码
if(author.getId() < 1)
this.authorRepository.add(author);
else
this.authorRepository.update(author); */
this.authorRepository.save(author);
}
/* 【问题】为何仓库返回的是一个Iterable<E>,我们要转换为Collection,如List?
* 在原生的JDBC镇南关,繁华的是ResultSet,是Iterable,这使得我们可以执行语句,同时继续从数据库中读取信息。
* 在事务方法中,我们已经commit了事务,关闭了ResultSet,转换为list这类collection,确保所有的数据在事务结束前已经被读取。
*/
private <E> List<E> toList(Iterable<E> i){
List<E> list = new ArrayList<>();
i.forEach(list::add);
return list;
}
... ...
}
- findAll(Sort)
- findAll(Pageable)
使用仓库接口
@Service
public class DefaultBookManager implements BookManager {
@Inject AuthorRepository authorRepository;
@Override
@Transactional
public List<Author> getAuthors() {
// return this.toList(authorRepository.getAll()); //以前的代码
return this.toList(authorRepository.findAll());
}
@Override
@Transactional
public void saveAuthor(Author author) {
/* 以前的代码
if(author.getId() < 1)
this.authorRepository.add(author);
else
this.authorRepository.update(author); */
this.authorRepository.save(author);
}
/* 【问题】为何仓库返回的是一个Iterable<E>,我们要转换为Collection,如List?
* 在原生的JDBC镇南关,繁华的是ResultSet,是Iterable,这使得我们可以执行语句,同时继续从数据库中读取信息。
* 在事务方法中,我们已经commit了事务,关闭了ResultSet,转换为list这类collection,确保所有的数据在事务结束前已经被读取。
*/
private <E> List<E> toList(Iterable<E> i){
List<E> list = new ArrayList<>();
i.forEach(list::add);
return list;
}
... ...
}
相关链接: 我的Professional Java for Web Applications相关文章