爬虫实战:抓取某个qq群的所有群成员昵称、头像,然后把所有人的头像拼到一个图片里,所有人的昵称,生成一个词云图片
分析步骤:
1.分析qq群的请求
2.使用requests模块发送请求,下载qq头像
3.获取每个人的qq号,昵称
4.使用wordcloud模块生成昵称词云
5.使用pillow模块拼接头像
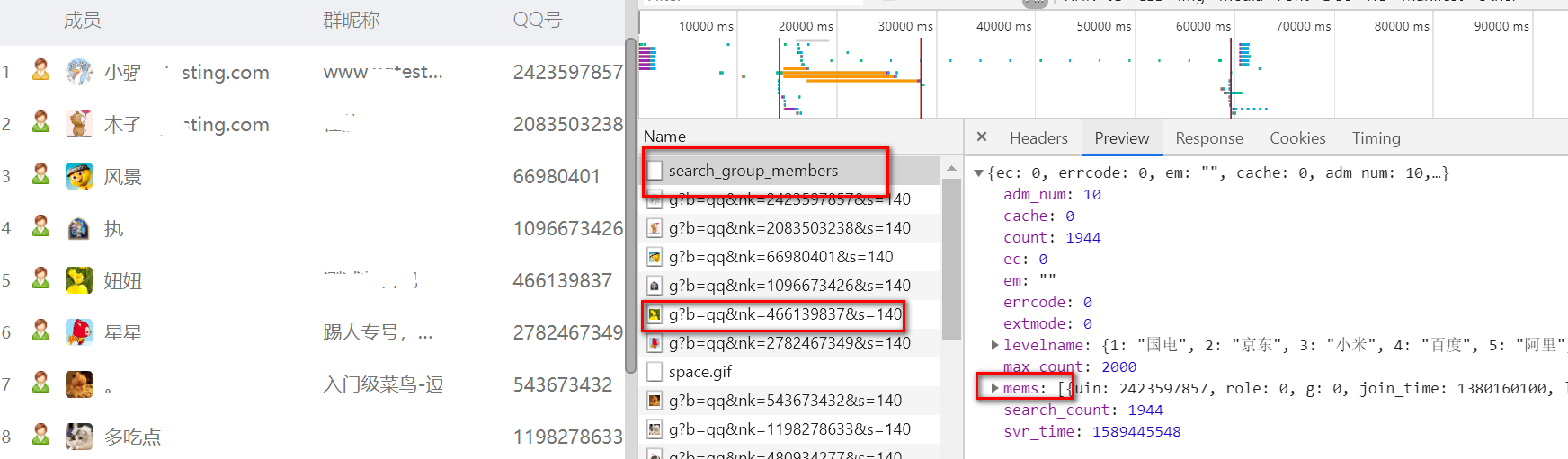
从第一步开始,先分析下qq群的请求,打开https://qun.qq.com/member.html,这个url是qq群的网页管理版,可以选择一个你加入的任意一个qq群,看到所有成员的信息,然后选择一个qq群,抓包,可以看到它是请求了一个search_group_members的接口,传入群号,返回了群里的一些成员信息
请求头信息:
请求分析完,现在能获取到每个群成员的信息了,返回的mems这个list里面存的是所有qq成员的信息,每个信息是一个字典,nick这个是qq昵称,uin这个key是每个人的qq号。
通过上面的请求也拿到了获取头像的url,就是qq号不一样而已,https://q4.qlogo.cn/g?b=qq&nk=498201529&s=140,nk这个是qq号,想获取谁的头像,换个qq号就可以了
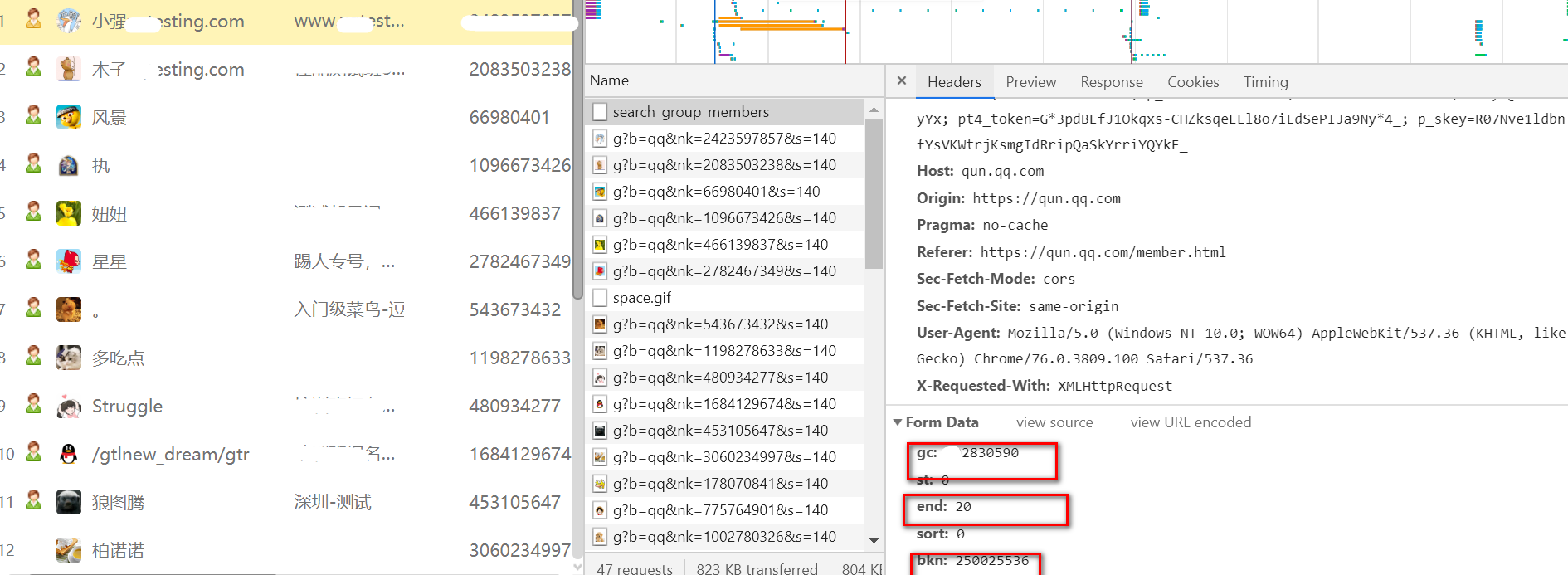
用postman请求一下这个搜索接口,看下返回数据的格式,因为这个qq群管理的网页必须得登录才能看到群信息,所以调用这个接口的时候,要传入cookie,所以直接从浏览器里面把cookie复制过来拿进去
url:https://qun.qq.com/cgi-bin/qun_mgr/search_group_members,post请求,把headers里面的请求数据拿过来
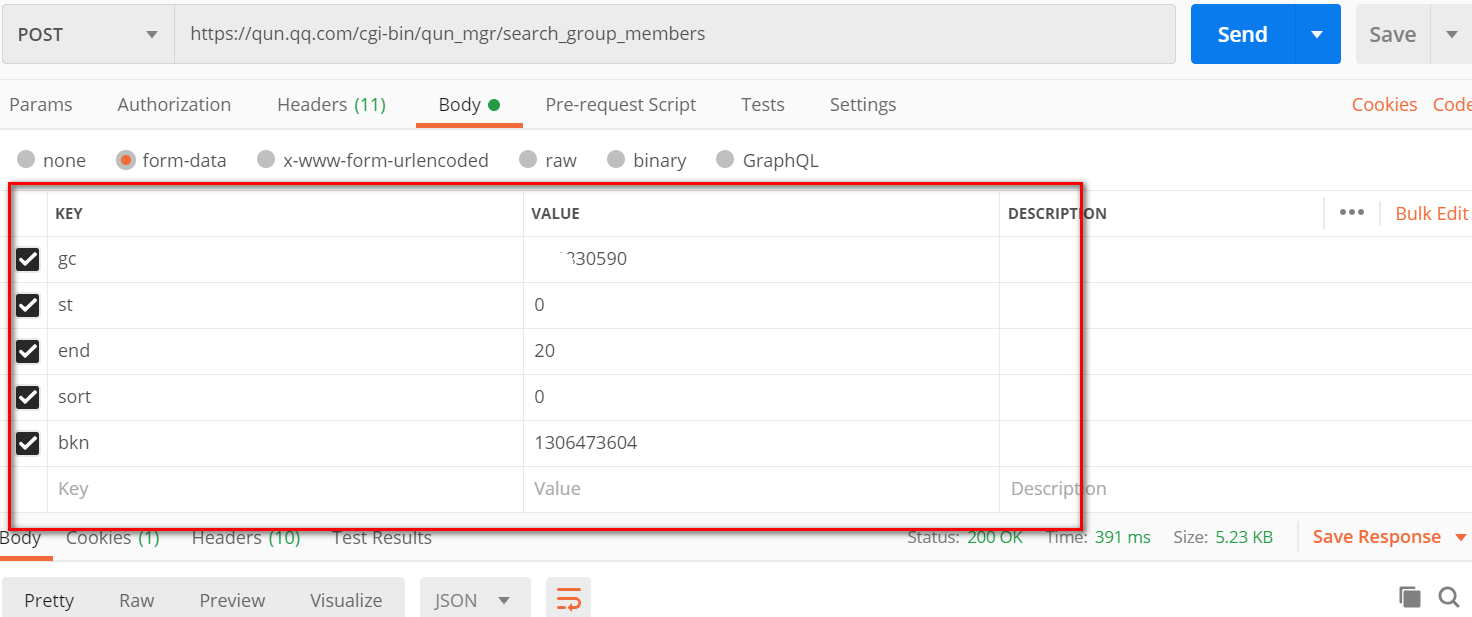
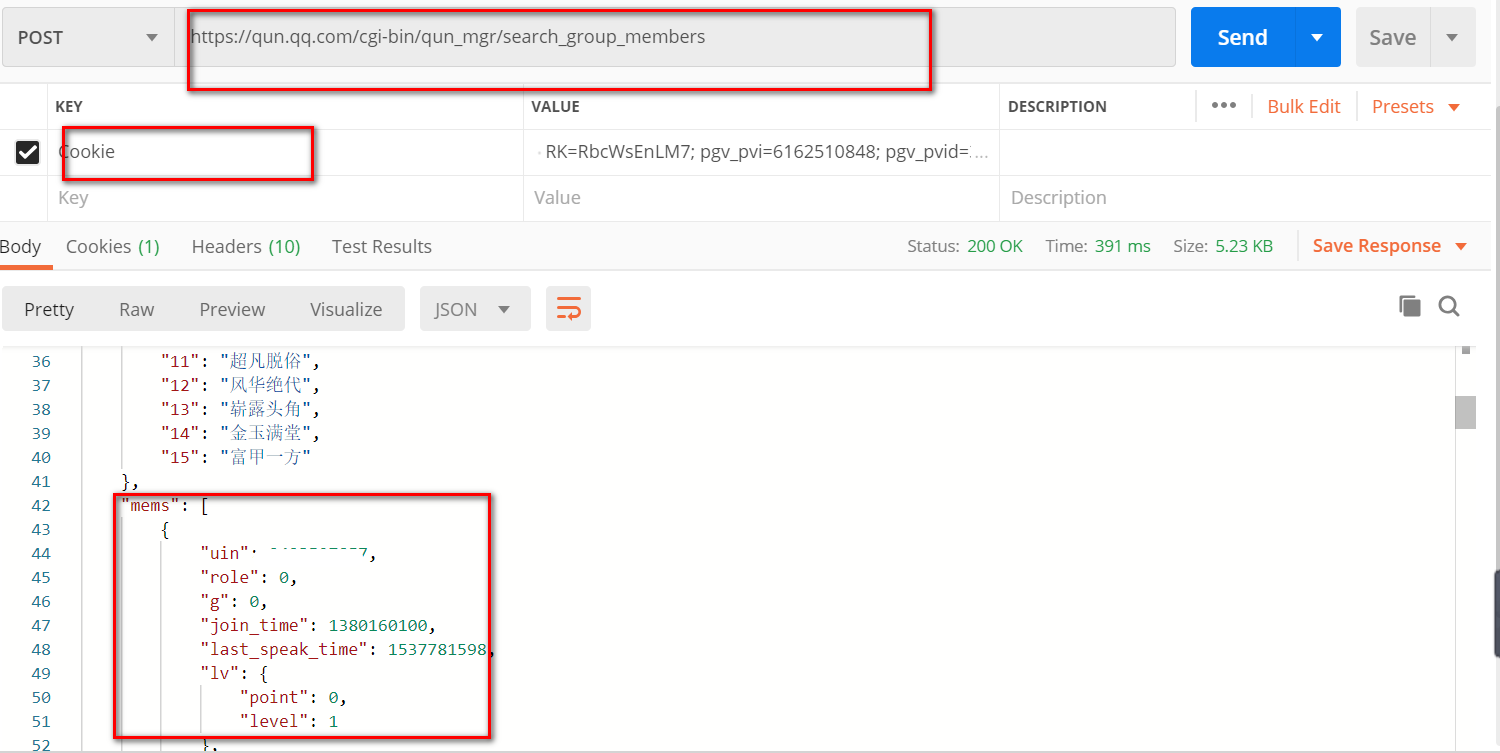
上面的分析已经完成了,知道了通过search_mems这个接口可以获取到所有群成员信息,还有下载qq头像的url。
import requests,random
from os import listdir
import os,re
from PIL import Image
import math
from wordcloud import WordCloud
import urllib3
class GenQQMem:
group_url='https://qun.qq.com/cgi-bin/qun_mgr/search_group_members'#获取群信息的url,这里用类变量,因为他不会变
def __init__(self,qq_num,group_name='',mem_count=20):
self.qq_num=qq_num #qq号码,这里绑定之后,下面就可以self使用了
self.mem_count=mem_count #成员数量,默认获取20个
self.dir_name=qq_num+'_'+group_name #这个是每个群的文件夹,用群号+群名字做文件夹的名字,存放每个群里人的头像
def Foma(self,data):#将data格式变成字典格式
dic = {}
dat = data.split('&')
for d in dat:
d = d.replace('=', ':')
d1 = d.split(':')[0]
dic[d1] = d.split(':')[1]
return dic
def get_mems(self):
#这个函数用来下载所有的头像,获取所有的qq成员信息
#发送post请求,获取到所有群成员信息
all_nicks=[]
data='gc=%s&st=0&end=%s&sort=0&bkn=1828438990'%(self.qq_num,self.mem_count)#这个是请求数据
m=self.Foma(data)
cookies={
'Cookie': 'RK=RbcWsEnLM7; pgv_pvi=6162510848; pgv_pvid=3721560373; ptcz=9798ef4a481b00be429978523f36bf55a8ba136786e163956f53cb68945e8da7; tvfe_boss_uuid=7a26071928349f48; o_cookie=812850788; pac_uid=1_812850788; ue_uk=a4af0d6184a86ae4166560709ba31783; ue_uid=fd661495567e1f0184368388fba401d9; LW_pid=7912f88bc83769398d43039a416e5e0e; ue_ts=1550902178; ue_skey=b4c59a1426e1fbd14b252af98ebfc643; ts_uid=1346166200; mobileUV=1_16edbcf6e4c_65bde; eas_sid=51K5D8g7N8A2U4P689I0y3I8s2; [email protected]; _qpsvr_localtk=0.09521351065015837; pgv_si=s2111662080; p_uin=o0812850788; traceid=45e74bd00a; uin=o0812850788; skey=@J6lLo0QoR; pt4_token=-MTXVLvdsPtkxrx1yHDddHI5tcCdP3jNmy9I6-L5wjw_; p_skey=79fRjcT2WHV5pKwkJsi*pwUrspinS7*NFuMbhro69Zo_'
}#cookie信息,浏览器里面复制的
requests.packages.urllib3.disable_warnings()
res=requests.post(self.group_url,data=m,headers=cookies,verify=False).json()##发送post请求,传入cookie和data
print(res)
mems=res.get('mems')#mems这个key里面存的是一个list,所有的qq群成员在这里
if not os.path.isdir(self.dir_name):#判断这个群的文件夹是否存在,如果不存的话,创建
os.mkdir(self.dir_name)
for m in mems:
url='https://q4.qlogo.cn/g?b=qq&nk={}&s=140'.format(m.get('uin')) #通过替换qq号,生成每个qq成员的头像url
abs_path = os.path.join(self.dir_name, '%s.jpg' % m.get('uin')) # 拼好每个图片的绝对路径,以qq号命名
open(abs_path, 'wb').write(requests.get(url, verify=False).content) # 打开文件,因为是图片,所以wb,二进制模式打开
# content这个在requests模块的博客里面说过了
nick_name = m.get('nick') # 昵称
print('下载完成【%s】' % nick_name) # 打印提示
all_nicks.append(nick_name) # 把所有的昵称保存到一个list里面,用来做词云
return all_nicks # 返回所有的昵称list
def clear_nicks(self, nicks):
return [re.sub('&.*?;', '', nick) for nick in nicks]
# 因为有的人昵称里面有空格,空格是html标签
# 出来就是这样的 快乐 小猪
# 或者有大于号的就是这样的 天天>开心
# 这里用正则表达式,把&xx;这样的字符串都替换成空
def gen_wrodcloud(self, words):
# 生成词云
words = ' '.join(words) # 传过来的是一个list,给变成字符串,每个名字用逗号隔开,因为每个昵称就是一个词语了,所以不用jieba分词了
wordcloud = WordCloud(width=1000, # 图片的宽度
height=860, # 高度
margin=2, # 边距
background_color='black', # 指定背景颜色
font_path='C:\Windows\Fonts\Sitka Banner\msyh.ttc' # 指定字体文件,要有这个字体文件,自己随便想用什么字体,就下载一个,然后指定路径就ok了
)
wordcloud.generate(words) # 分词
wordcloud.to_file(self.dir_name + '_' + 'wordcloud' + '.jpg') # 保存到图片
def gen_pic(self):
# 拼接图片的函数,这个在拼接图片那个博客里写有
user = self.dir_name
pics = listdir(user)
random.shuffle(pics)
numPic = len(pics)
size = 760
eachsize = int(math.sqrt(float(size * size) / numPic))
numline = int(size / eachsize)
toImage = Image.new('RGBA', (size, size))
x = 0
y = 0
for i in pics:
try:
# 打开图片
img = Image.open(user + "/" + i)
except IOError:
print("Error: 没有找到文件或读取文件失败")
else:
# 缩小图片
img = img.resize((eachsize, eachsize), Image.ANTIALIAS)
# 拼接图片
toImage.paste(img, (x * eachsize, y * eachsize))
x += 1
if x == numline:
x = 0
y += 1
toImage.save(user + str(size) + ".png")
def main(self):
# 入口
all_nicks = self.get_mems() # 调用获取获取成员信息、下载图片接口
all_nicks = self.clear_nicks(all_nicks)
print(all_nicks)
self.gen_wrodcloud(all_nicks) # 调用生成词云函数
self.gen_pic()
if __name__=='__main__':
q = GenQQMem('202830590', 'jmeter')#实例化
q.main()#调用
同时这段代码出现的问题:1. 存在一个cookie失效的问题,尝试使用了selenium重新登录获取cookie,但是是使用扫描二维码登录,所以我也没有办法解决,如果有小伙伴有解决办法,麻烦留言告诉我,万分感谢;2. 还存在一个证书验证的设置问题,这个已解决:
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code)
打印结果:200
附上执行完毕后的两张图片:

