最近某个项目出现了查询非常慢的问题, 就是企业名称的模糊查询, 由于不知道关键词的位置, 所以都是 like '%keyword%' 进行全文检索, 正常搜索都要20秒以上. 普通的索引无法生效, 已有项目,不进行框架改造,考虑从数据库优化入手.
整体步骤大概是:
1 Mysql5.7.6版本之后是支持INNODB的中文全文索引的. 创建索引时需要用到 with parser ngram
创建语句:
ALTER TABLE tablename ADD FULLTEXT INDEX tablename_columnname (columnname) with parser ngram;500w的记录数, 需要大概200秒. 供参考. 索引的创建需要放置到停用词配置完毕之后.
通过
show VARIABLES like '%innodb_ft_%';可以查看配置

这里我调整了innodb_ft_result_cache_limit的大小,从原来的 2000000000 调大了 4000000000.
由于中文全文索引的关键词是插件分割的, 没细研究,不知道其按语义分割的情况.
自己写了个测试的 innodb_ft_user_stopword_table
结构要跟mysql默认的结构一致:
create table my_innodb_ft_stopword (value varchar(32)) ENGINE = innodb default charset utf8 collate utf8_general_ci;自己往里面插入了一些stopword避免无效的关键词查询, 停用词的添加可考虑无意义或者查询结果集 >50% 的词语, 比如"有限公司","公司" 按照n=3的分词策略, 有限股分公司 可拆分为
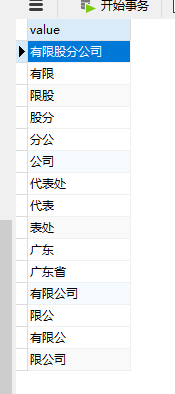
设置全局的停用词表
SET GLOBAL innodb_ft_user_stopword_table = 'mysql/my_innodb_ft_stopword'全文索引主要包括 自然语言模式 IN NATURAL LANGUAGE MODE 和布尔模式 IN BOOLEAN MODE
其中boolean模式中,
“+”表示必须包含
“-”表示必须排除
“>”表示出现该单词时增加相关性
“<”表示出现该单词时降低相关性
“*”表示通配符
“~”允许出现该单词,但是出现时相关性为负
“""”表示短语
官方解析:
'"some words"'
Find rows that contain the exact phrase “some words” (for example, rows that contain “some words of wisdom” but not “some noise words”). Note that the " characters that enclose the phrase are operator characters that delimit the phrase. They are not the quotation marks that enclose the search string itself.""双引号效果 类同于 like '%keyword%'
执行全文索引创建脚本.
查询效率对比:

官方资料链接: https://dev.mysql.com/doc/refman/5.7/en/innodb-fulltext-index.html
