这篇博客是看微软亚洲研究院的王井东讲解CNN做的笔记,图片居多。30分钟的视频,我看+写用了2个小时,可以说干货满满。适合已经对机器学习,CNN有一定了解的人,但对于CNN实践环节还不太清楚或者是想对最新的研究情况做进一步跟踪。
视频资源见链接:https://v.qq.com/x/page/s05667eq28w.html
视频主要从四个部分讲述CNN:卷积神经网络的基本架构、神经网络的组成、如何学习神经网络以及神经网络的最新的进展
1.卷积神经网络的基本架构
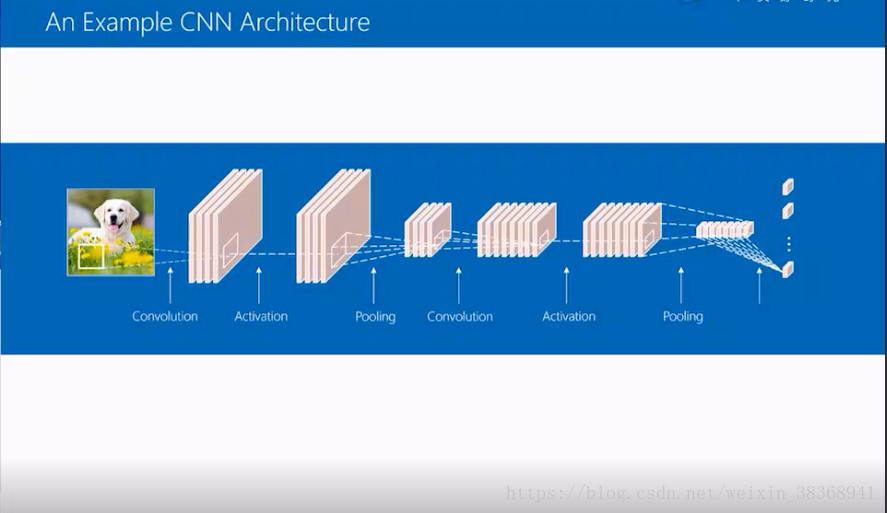
从一个例子进行说明:首先图像会经过第一个卷积层,然后得到四个通道,接着经过非线性的激活函数,得到新的四个卷积层,再通过pooling层,将通道map的大小降到一半,此时经过一个卷积层,可将4个通道变为8个通道,再经过非线性激活函数,得到新的8个通道,再经历一个全局的pooling过程,把8个map变成8维的向量,最后经过一个全连接层,最终可以得到分数。如果在分类中就可以给出各类的分数。
如下图所示:
2.神经网络的组成
1.卷积层
卷积层依赖卷积操作,在二维空间中,进行翻转平移操作。下面是连续卷积和离散卷积的两种形式的表达式。此外计算机视觉中,卷积一般用互相关DNN来代替,卷积的翻转在NN网络中并没有很多的用途。右图是一个图像与一个3*3 的kernel卷积的结果。在这里给出四个通道的例子,每个位置取出一个tensor,于是得到的tensor大小是3*3*4,然后经过一个同样大小的filter,会得到一个新的response,每个位置都做一下,就能得到一个新的map,于是4个filter就能得到4个通道map。

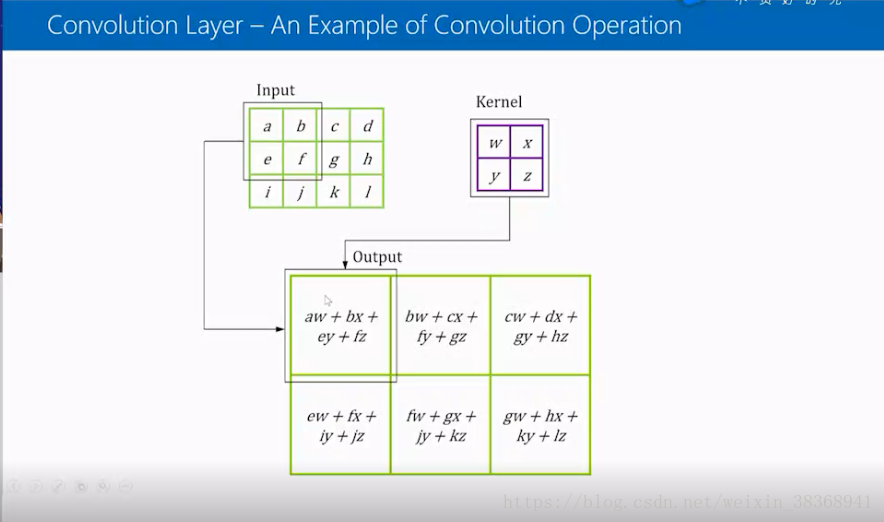
接下来就是具体计算,输入的矩阵(在计算中图像的存储方式是3维矩阵,这里用单维的矩阵表示)与kernel做卷积操作时,计算的结果是对应位置的相乘后相加,这里的例子是a*w+b*x+e*y+f*z,a和w是对应位置,然后kernel一次对应位置相乘的结果相加。这里可以注意到输入是一个4*3的矩阵,kernel是一个2*2 的矩阵时,得到循环卷积的结果是3*2的矩阵。
如下图所示:
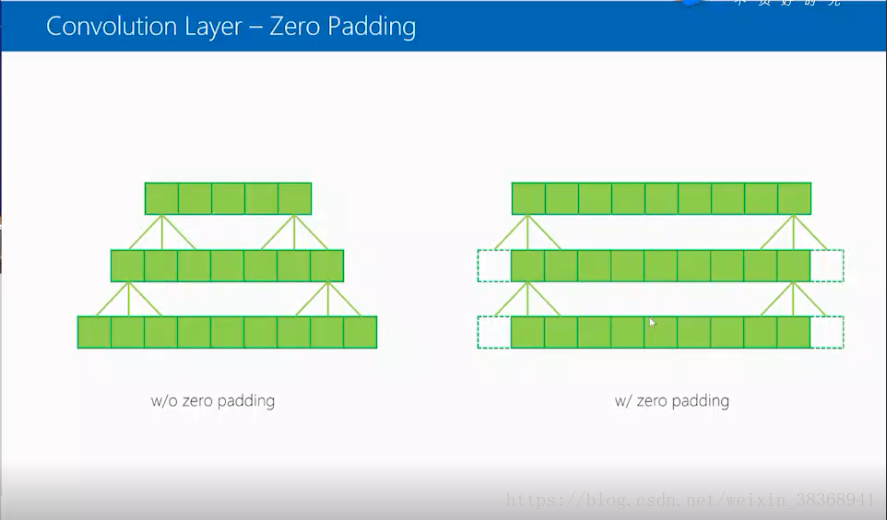
卷积里面含有两个问题,首先是zero padding的问题,给出一个一维的例子,假如这里有9个像素值,首先是没有padding的情况下,在kernel卷积是3的情况下,9个像素点在两次卷积之后得到的5个像素点,这里我们在做卷积操作时,每次引入左右两个padding,此时两次卷积的结果就变成了和原来输入一个的9个像素点。这也说明了zero padding的作用是使得完成卷积操作之后的结果与输入大小不变。需要注意的是,再完成padding操作时需要注意根据kernel的大小调整padding的数量。比如下面的例子改成5个像素的kernel时,需要左右各增加两个padding。
另一个问题是striding,上面的例子中右边就是stride=1 的情况,stride=2 的情况下,会对原输入跳过一个像素做卷积操作,再完成一次stride=2的卷积操作之后,得到5个像素点,再一次得到3个像素点。stride操作是使得sequence/map从大变小,在实际中应用也很广泛。

2.激活层
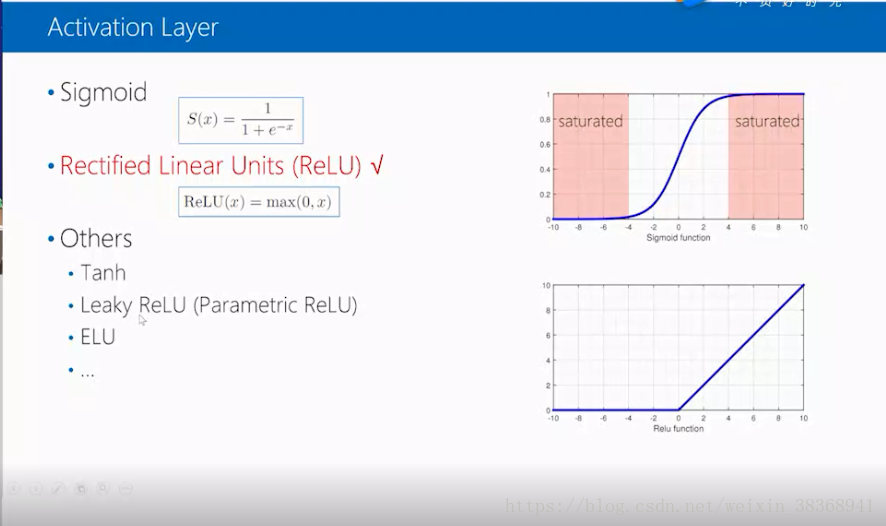
激活层依赖激活函数,这里先介绍sigmoid 函数,这里画出sigmoid函数的曲线,需要注意到的是在图像的两边各有一个红色的区域,在这个区域里,函数曲线是饱和的,导数近似为0,在深度网络中会遇到困难。于是在深度网络中更多的是ReLU 函数,它的表达式为ReLU(x)=max(0,x),它比sigmoid函数更容易优化,目前比较通用。当然也有tanh,Leaky ReLU,和ELU激活函数,这里不做详细说明。
3.pooling层
这里给出两个pooling层常用的例子:Max pooling和average pooling,也即分别对pooling区域内的值分别做取最大值和做平均操作,也用一个stride=2,filter size=2的例子说明,拿左上角的矩阵说明,max pooling 可以得到最大值6,average pooling可以得到平均值3.

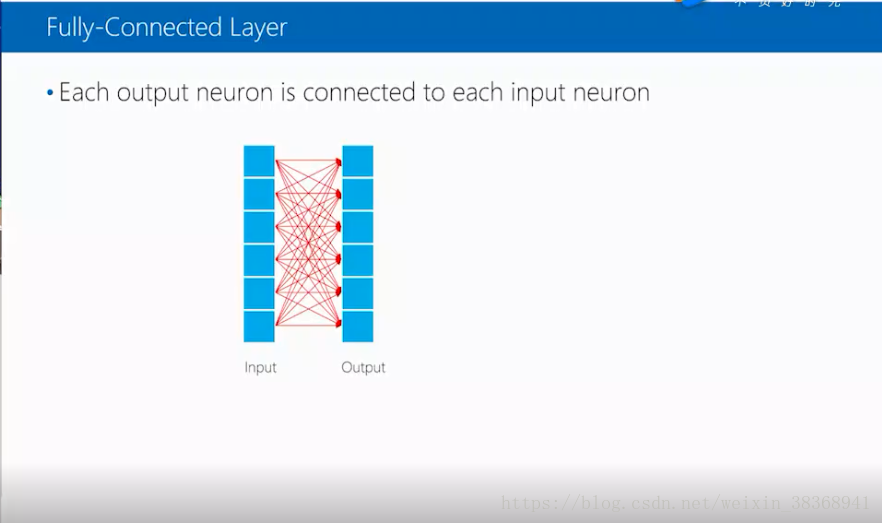
4.全连接层
全连接的意思是输入的每个神经元都和每个输出神经元相连,输入和输出层的神经元的数量可以不相等。
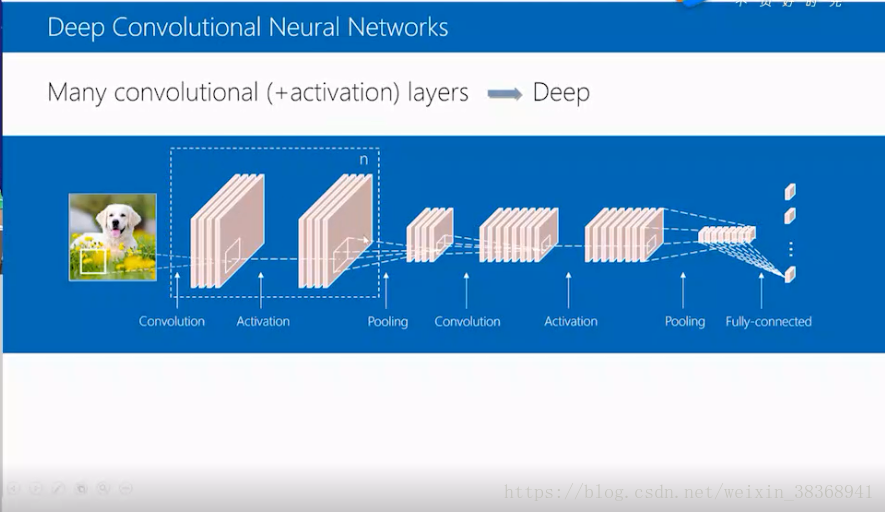
我们通常说的深度卷积网络,其实就是许多卷积层和激活层的叠加,以开头的例子为例,将其中的卷积层和激活层分别进行了N次和M次的重复,就能得到一个深度卷积网络。
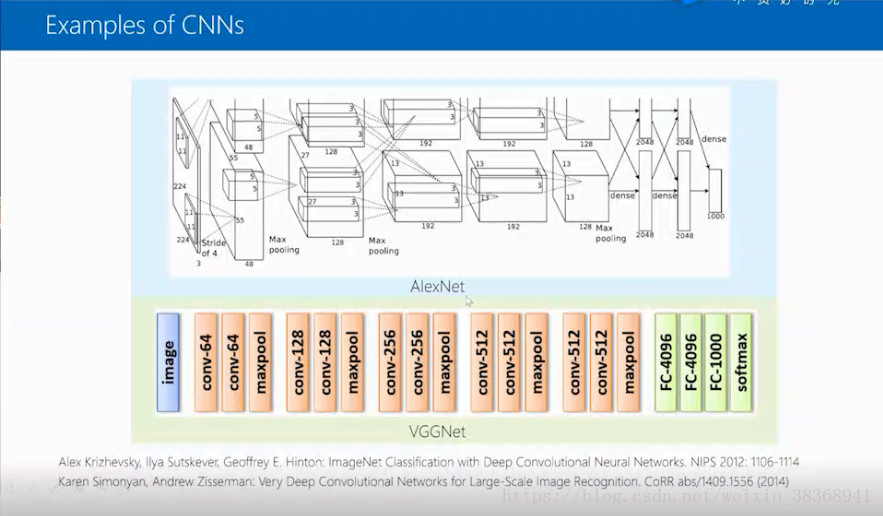
接下来我们看两个最近的典型案例,一个是AlexNet 是2012年Hilton和他的学生设计的,另一个VGGNet,是在2014年由牛津大学的一个实验室完成的。
3.如何学习神经网络
1.loss function
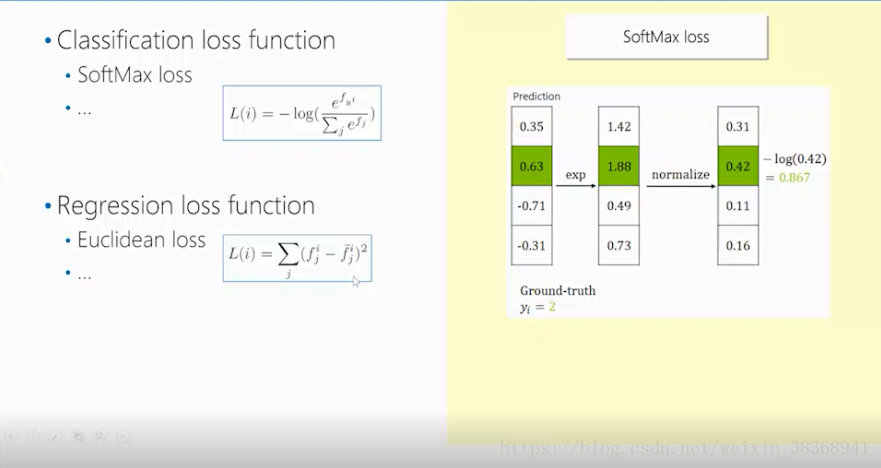
在学习参数前,首先需要定义loss function,这里我们介绍一些常用的loss function,首先是分类的loss function中常用的softmax loss,由下图可以看到它的表达式和计算实例,本质上是对预测的结果,做指数操作时,再归一化,最后取对数,可以通过设置Ground-truth的值来确定对数的底。接着是Regression loss function中的Euclidean loss(欧式损失),本质上是对预测值和真实值值差的平方相加。具体如下图:
2.参数优化
参数优化一般选择随机梯度下降,SGD,一般分为四步,第一步:做采样一部分样本,从n个样本中选择m个样本出来。第二步:计算m个样本的梯度。第三步:更新速度,最后更新模型参数。
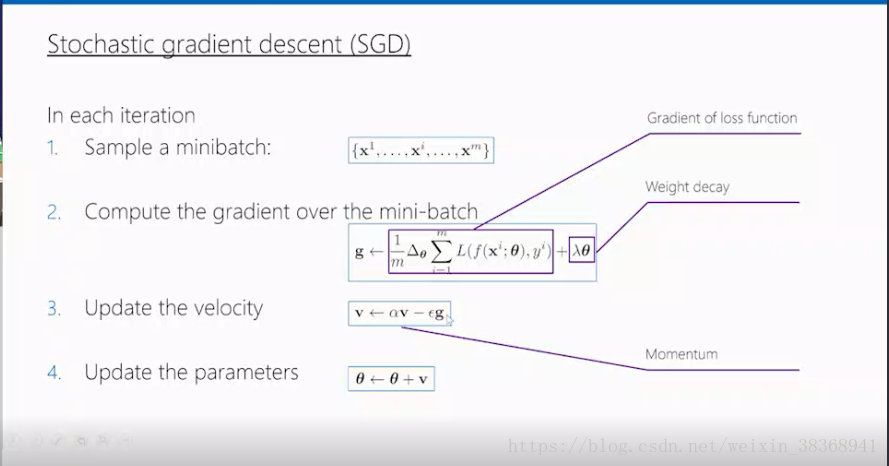
在这里我们介绍一个框出来的重点,首先是梯度,梯度的计算方法:反向传播,计算时选择求导的链式法则完成。

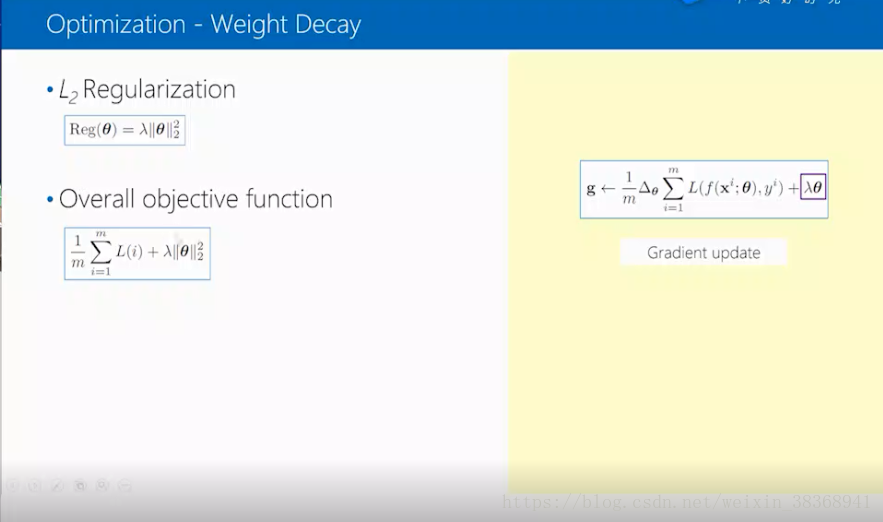
接着权重衰减,相当于L2的正则化,和loss function相加,可以得到整个的目标函数,对其进行求偏导就可以得到右边的形式。
之后是momentum,用来解决两个问题,
1.把上次的迭代的速度加到这次的迭代中去,减少了梯度变化,更加稳定。
2.解决Hessian 矩阵的变态问题,例子中黑色线是等高线,红色是迭代过程,红色线越来越接近最优解,而黑色则慢一点。

其他的问题和解决方法、改进方法就不展开讲了。

4.最新的研究成果
1.batch Normalization
算法分为4步,包括计算均值和方差,标准化,线性变化(使得网络性能维持)
它的目的是稳定每一层的输入分布,减少偏移。

2.Skip connection
用于使得优化简单,P可以选择不同的形式,比如I、幂次、或者是正交形式

3.Group Convolution
用来提高参数效率,例子:将通道分为两部分,然后分别卷积,接着输出结果相加,最后再做1*1 的卷积,使得两部分结果相关

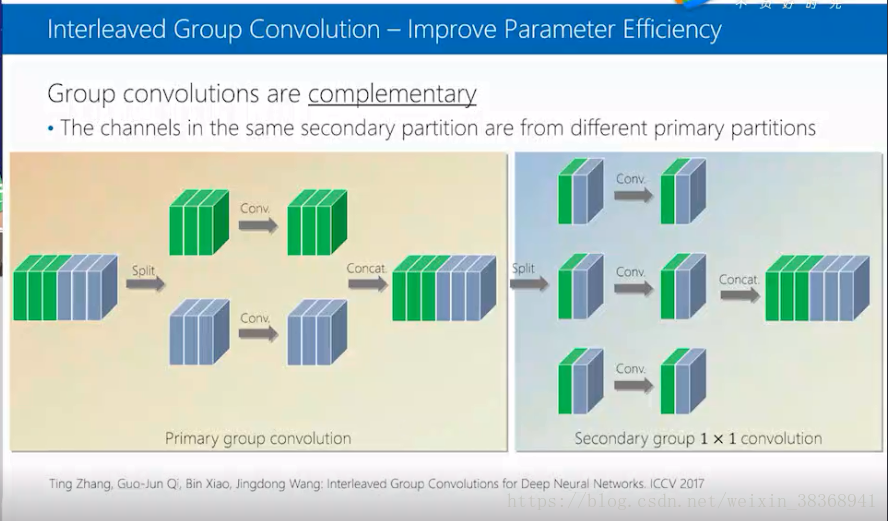
3.Interleaved Group Convolution
这个模型先用Group convolution,然后再做第二次的Convolution,分成三组,每组中选择上次不同的分组,然后分别做卷积,适用于手机和电视,模型参数小,比别的卷积网络性能更好。
4.Bottleneck Layer
这个模型先做一个1*1 的卷积操作,降低宽度,然后再做3*3的卷积操作,之后再做1*1 的卷积操作,回复到之前的宽度。用于降低参数的数量,提高训练的效率。

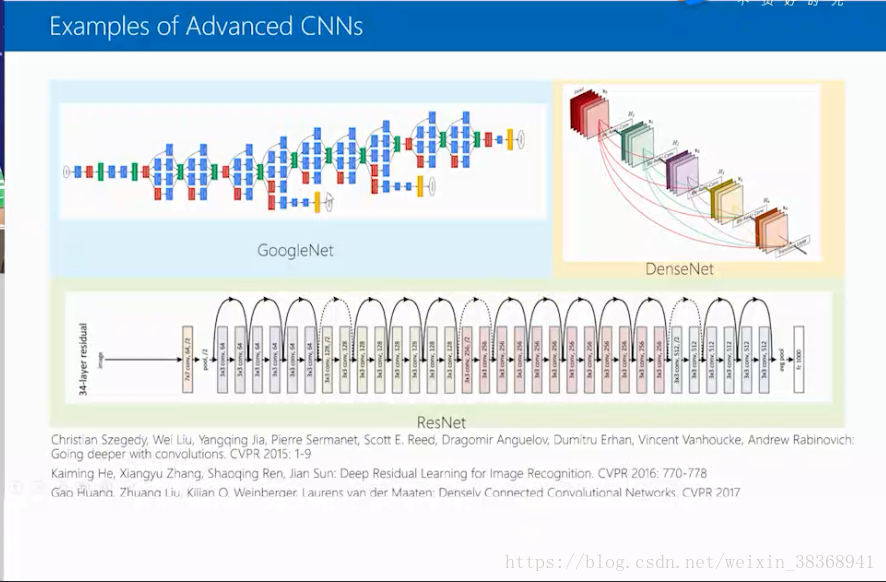
最后给出最新的CNN例子: