目录
- B站视频《[数说弹幕]我不小心看了后浪弹幕》
- 关于《后浪》的B站弹幕分析总结(一)——爬取B站视频的上万条弹幕的方法
- 关于《后浪》的B站弹幕分析总结(二)——分词常用的词典、颜文字处理以及格式统一
- 关于《后浪》的B站弹幕分析总结(三)——怎么制作好看的交互式词云
这一步的实现是建立在分词工作已经做好了的基础上,具体方法可以参考我之前的文章,这里不再重复说明。这里介绍两种方法,两种方法都好用,看你习惯哪种了。
一、使用sklearn里面的LatentDirichletAllocation做主题挖掘
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer #基于TF-IDF的词频转向量库
tf_vectorizer=TfidfVectorizer(stop_words=stoplist,tokenizer=jieba_cut,use_idf=True) #创建词向量模型,这里的jieba_cut是自定义的分词函数
tf=tf_vectorizer.fit_transform(comment_list) #将评论关键字列表转换为词向量空间
from sklearn.decomposition import LatentDirichletAllocation #导入 LDA模型库
n_topics=5 #设置主题个数
lda=LatentDirichletAllocation(n_components=n_topics,max_iter=200,
learning_method='online',
learning_offset=50.,
random_state=0)
lda.fit(tf)#拟合模型
得到下面模型结果
LatentDirichletAllocation(batch_size=128, doc_topic_prior=None,
evaluate_every=-1, learning_decay=0.7,
learning_method='online', learning_offset=50.0,
max_doc_update_iter=100, max_iter=50,
mean_change_tol=0.001, n_components=5, n_jobs=None,
perp_tol=0.1, random_state=0, topic_word_prior=None,
total_samples=1000000.0, verbose=0)
#定义展示模型函数
def print_top_words(model,feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" %topic_idx)
print(' '.join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
n_top_words=20 #设置每个主题展示词组个数
tf_feature_names=tf_vectorizer.get_feature_names()
print_top_words(lda,tf_feature_names,n_top_words)
结果如下:
Topic #0:
奔涌 后浪 BILIBILI 排面 泪目 高考 看到 P3 帅 弹幕 作文 TESTV 河流 沙滩 当自强 老泪纵横 必胜 热乎 星巴克 嘶吼
Topic #1:
干杯 哔哩哔哩 加油 FPX 哭 牌面 冲冲冲 复旦 中考 说 博爱 哥哥 牛壁 牛皮 写 电 鸭 刘振邦 子霖叔 青年人
Topic #2:
光 火 牛逼 和而不同 IG 老番茄 NB 美美与共 君子 青年 时代 前辈 同学 学习 有幸 感谢 遇见 冠军 浪 祖国
Topic #3:
站 B 爱 老师 中国 何冰 破 党妹 年轻 感动 共勉 谢谢 小破站 朋友 喜欢 RNG 李子 最好 时代 NANA
Topic #4:
致敬 强大 鼓励 赞美 内心 热泪盈眶 未来 奔跑 吝啬 青春 世界 合影 年轻人 激动 拥抱 热血沸腾 否定 表达 嘲讽 弱小
二、使用gensim的ldamodel做主题挖掘
from gensim.corpora import Dictionary
from gensim.models import ldamodel
from gensim.models import CoherenceModel, LdaModel
from gensim import models
%matplotlib inline
d=Dictionary(words_list) #分词列表转字典
corpus=[d.doc2bow(text) for text in words_list] #生成语料库
model=ldamodel.LdaModel(corpus,id2word=d,iterations=2500,num_topics=4,alpha='auto')#生成模型
model.show_topics(num_words=20) #展示每个主题下的20个词组
结果如下:
[(0,
'0.028*"老师" + 0.027*"来" + 0.027*"站" + 0.024*"破" + 0.023*"小" + 0.021*"要" + 0.021*"是" + 0.021*"好" + 0.020*"何冰" + 0.017*"看" + 0.016*"未来" + 0.015*"冲" + 0.015*"哭" + 0.014*"致敬" + 0.012*"牛逼" + 0.011*"NB" + 0.010*"高能" + 0.009*"B站" + 0.008*"世界" + 0.008*"热血沸腾"'),
(1,
'0.418*"后浪" + 0.417*"奔涌" + 0.009*"谢谢" + 0.006*"奔跑" + 0.006*"中考" + 0.006*"前辈" + 0.006*"是" + 0.004*"感谢" + 0.004*"中国" + 0.004*"生活" + 0.004*"否定" + 0.004*"弱小" + 0.004*"嘲讽" + 0.003*"演员" + 0.003*"习惯" + 0.003*"看着" + 0.003*"感激" + 0.003*"满怀" + 0.002*"人" + 0.002*"优秀"'),
(2,
'0.337*"干杯" + 0.265*"哔哩哔哩" + 0.109*"有" + 0.053*"光" + 0.049*"火" + 0.035*"泪目" + 0.025*"爱" + 0.013*"牌面" + 0.004*"B站" + 0.004*"感动" + 0.003*"长江后浪推前浪" + 0.003*"朋友" + 0.002*"水印" + 0.002*"了解" + 0.002*"讲" + 0.002*"厉害" + 0.002*"事" + 0.002*"好看" + 0.002*"小人" + 0.002*"泪光"'),
(3,
'0.216*"加油" + 0.135*"排面" + 0.047*"BILIBILI" + 0.025*"人" + 0.016*"B" + 0.016*"强大" + 0.015*"鼓励" + 0.015*"赞美" + 0.015*"内心" + 0.014*"时代" + 0.014*"君子" + 0.014*"站" + 0.013*"吝啬" + 0.011*"美美与共" + 0.011*"干杯" + 0.010*"喜欢" + 0.010*"和而不同" + 0.009*"青春" + 0.009*"小破站" + 0.009*"今年"')]
可以看到不仅展示了主题词组,还展示了词组权重。
三、如何将结果可视化
import warnings
try:
import pyLDAvis.gensim
CAN_VISUALIZE=True
pyLDAvis.enable_notebook()
from IPython.display import display
except ImportError:
ValueError("SKIP: please install pyLDAvis")
CAN_VISUALIZE=False
warnings.filterwarnings('ignore')
%matplotlib inline
prepared = pyLDAvis.gensim.prepare(model,corpus,d)
pyLDAvis.show(prepared, open_browser=True)
结果输出为html可交互的可视化图表
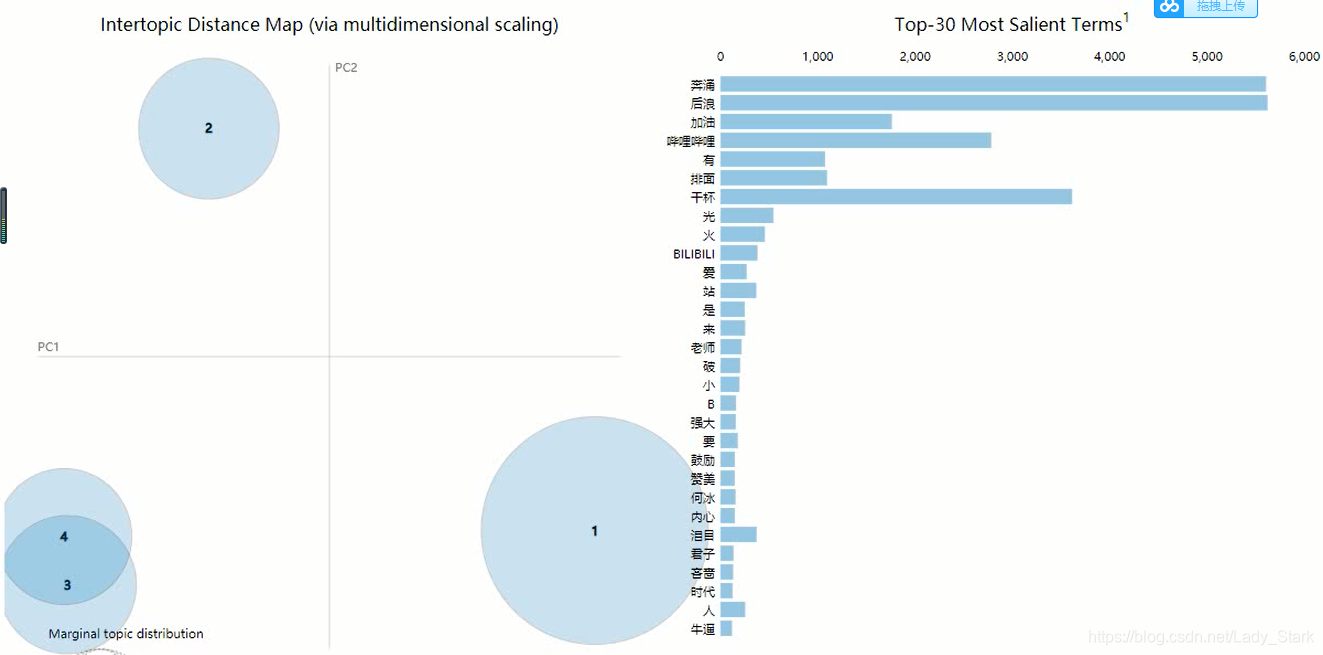
具体动图可参看我的B站视频,视频链接在文章开头。
四、如何确定主题数
4.1 观察可视化图形
通过上面的可视化图表,看每个类别圆形区域是否重叠较多,再在程序中手动调整主题数。
4.2 使用模型检验指标判断
通过一些模型检验指标来判断,例如u_mass, c_v等
设置两个用作比较的模型
goodLdaModel = LdaModel(corpus=corpus, id2word=dictionary, iterations=50, num_topics=3)
badLdaModel = LdaModel(corpus=corpus, id2word=dictionary, iterations=50, num_topics=10)
使用U_Mass Coherence
goodcm = CoherenceModel(model=goodLdaModel, corpus=corpus, dictionary=dictionary, coherence='u_mass')
badcm = CoherenceModel(model=badLdaModel, corpus=corpus, dictionary=dictionary, coherence='u_mass')
可视化主题模型
pyLDAvis.enable_notebook()
pyLDAvis.gensim.prepare(goodLdaModel, corpus, dictionary)
pyLDAvis.gensim.prepare(badLdaModel, corpus, dictionary)
print goodcm.get_coherence()
-14.0842451581
print badcm.get_coherence()
-14.4434307511
这个指标值越大越好,所以goodcm要好于badcm
使用C_V coherence
goodcm = CoherenceModel(model=goodLdaModel, texts=texts, dictionary=dictionary, coherence='c_v')
badcm = CoherenceModel(model=badLdaModel, texts=texts, dictionary=dictionary, coherence='c_v')
结果是:
print goodcm.get_coherence()
0.552164532134
print badcm.get_coherence()
0.5269189184
这个指标也是越大越好。
下一篇文章我将着重讲情感分析以及一点点情绪分析的内容,敬请期待
