字典树
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。[wikipedia]
Trie的典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。[百度百科]
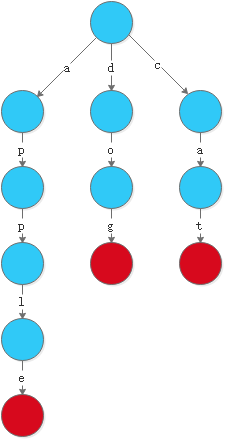
红色节点表示一个单词的结尾。
节点的设计
第一版
每个节点包含该节点的值,是否为单词的结尾,该节点的子节点。设计如下:
class Node{
public boolean isWord;
public char val;
public char[26] next;
}
问题所在:
- 多余的val,实际上指向该节点的引用中就包含了该节点的值是多少 ,所以val是多余的;
- 使用数组不合理,实际需求中不可能只有26个字母,也许有大小写,也许有其他符号,所以需要使用其他数据结构。
第二版
class Node{
public boolean isWord;
public Map<Character,Node> next;
}
舍去了val,将指向下一节点的引用放在map里。此时暂时只考虑英文字符不考虑其他语言(中文等等)。
Trie的第一步
根据第二版Node的设计我们实现Trie。
public class Trie {
private class Node{
public boolean isWord;
public TreeMap<Character,Node> next;
public Node(boolean isWord){
this.isWord = isWord;
this.next = new TreeMap<>();
}
public Node(){
this(false);
}
}
private Node root;
private int size;
public Trie(){
this.root = new Node();
this.size = 0;
}
/**
* 返回Trie节点数
*/
public int getSize(){
return this.size;
}
}
Trie的添加
往字典树中添加节点步骤如图所示:

/**
* 添加单词
* @param word
*/
public void add(String word){
Node curr = root;
for(int i=0;i<word.length();i++){
char c = word.charAt(i);
if(curr.next.get(c)==null){
curr.next.put(c,new Node());//没有该节点,直接添加新的
}
curr = curr.next.get(c);//有该节点,移动curr,继续查找下一节点
}
if(!curr.isWord){//如果之前已经存在该单词了size不能加1
curr.isWord = true;
size++;
}
}
Trie的查找单词
查询Trie中是否包含该单词。
/**
* 查询单词
*/
public boolean contains(String word){
Node curr = root;
for(int i=0;i<word.length();i++){
char c = word.charAt(i);
if(curr.next.get(c)==null){
return false;//无下一个值的节点,直接返回false
}
curr = curr.next.get(c);
}
return curr.isWord;//单词到达末尾,根据isWord标志判断
}
判断前缀
与查询单词方法大同小异。
/**
* 查询是否在Trie中有单词以prefix为前缀
* @param prefix
* @return
*/
public boolean isPrefix(String prefix){
Node curr = root;
for(int i=0;i<prefix.length();i++){
char c = prefix.charAt(i);
if(curr.next.get(c)==null){
return false;
}
curr = curr.next.get(c);
}
return true;
}
删除单词
删除节点的情况共有如下四种情况:

- 情况一:逐一将节点去除即可;
- 情况二:直接将isWord置为false即可;
- 情况三:逐一删除节点,如果待删除节点是另外一个单词结尾则停止删除;
- 情况四:逐一删除节点,但是如果待删除节点还有其他孩子节点则停止删除。
/**
* 删除单词
*/
public void delete(String word){
Stack<Node> preNodes = new Stack<>();
//删除前查找是否存在这个单词,存在才能删除
if(!contains(word)){
return;//不存在该单词,直接返回
}
Node curr = root;
for(int i=0;i<word.length();i++){
char c = word.charAt(i);
preNodes.push(curr);//添加前驱节点
curr = curr.next.get(c);
}
if(curr.next.size()==0){//到了单词末尾,节点是叶子节点
for(int i=word.length()-1;i>=0;i--){
char c = word.charAt(i);
Node pre = preNodes.pop();//获得前驱节点
//判断是否为其他单词的结尾,是则停止删除节点
//判断待删除节点是否还有其他孩子,有则停止删除节点
if((i!=word.length()-1&&pre.next.get(c).isWord)||pre.next.get(c).next.size()!=0){
break;
}
pre.next.remove(c);//删除节点
}
}else{
curr.isWord = false;//情况2
}
size--;
}
