并查集
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。
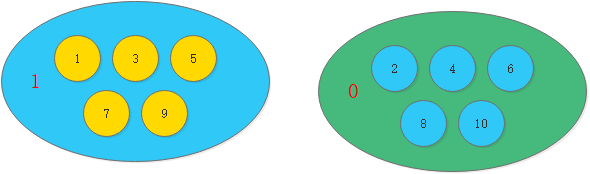
如图所示,1,3,5,7,9节点属于集合1;2,4,6,8,10节点属于集合0。每一个节点都有一个属性表示此节点所属集合的id,如果两个节点的集合id相同,那么这两个节点是连通的。
对于并查集主要支持两个方法:isConnected(判断两个节点是否连通)和union(将两个节点合并在同一个集合中)
实现并查集接口:
public interface IUnionFind {
boolean isConnected(int p,int q);
void unionElements(int p,int q);
int getSize();
}
基础:数组表示
假设现在我们有10个编号(抽象表示),每个编号都有一个id表示所在集合id。

当我们判断p和q是否同属于一个集合时只需要判断对应id是否相同即可,时间复杂度为O(1)。
实现find和isConnected
public class UnionFindImpl implements IUnionFind {
private int[] id;//存储每个数据所属集合的编号
public UnionFindImpl(int size){
id = new int[size];
for(int i=0;i<id.length;i++){
id[i] = i;//开始时让每个元素构成一个单元素的集合
}
}
@Override
public boolean isConnected(int p, int q) {
return find(p)==find(q);
}
/**
* 查找元素p所对应的集合编号
*/
private int find(int p){
assert p>=0&&p<id.length;
return id[p];
}
@Override
public int getSize() {
return id.length;
}
}
实现unionElements
现在我们需要合并1和4两个编号,首先我们需要将4所对应的id更改为1(修改1的也行),但是还没结束,我们还需要修改所有和4连通的编号所对应的id。最终结果如下:

@Override
public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if(pID == qID){//待合并的两个编号在同一个集合中,无需任何操作
return;
}
for(int i=0;i<id.length;i++){
if(id[i]==pID){//将pID所有元素的id都改为qID
id[i] = qID;
}
}
}
union时间复杂度为O(n)。
进化:不一样的树
在基础中我们使用数组模拟并查集的操作,在find中速度十分快,可是在union操作中就十分慢了,对此我们可以使用树来表示并查集。但是,这棵树和我们以往看到的树不一样,这是一棵由子节点指向父节点的树。
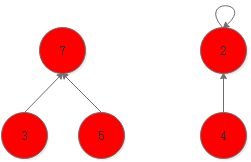
我们可以使用数组存储节点的父节点值。

public class UnionFindImpl2 implements IUnionFind {
private int[] parent;//存储每一节点父节点值
public UnionFindImpl2(int size){
parent = new int[size];
for(int i=0;i<parent.length;i++){
parent[i] = i;//初始时每个节点自称一个集合所以父节点就是自己
}
}
@Override
public int getSize() {
return parent.length;
}
}
寻根操作
我们可以逐级向上寻找根节点,如果某节点的父节点就是自己本身那么此节点就是根节点。
/**
* 查找节点p的根节点
* 时间复杂度O(h),h为树的高度
* @param p
* @return
*/
private int find(int p){
assert p>=0&&p<parent.length;
while(p!=parent[p]){
p = parent[p];
}
return p;
}
判断是否为同一集合中的元素比较是否是相同的根即可。
合并操作
3和5都指向节点7,4指向节点2,指向自己。如果我们需要将节点5和节点2合并只需要将节点7指向节点2即可(2指向7也行)。
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)//相同集合无需操作
return;
parent[pRoot] = qRoot;//将pRoot添加到qRoot中,成为qRoot的孩子。(后期待优化)
}
优化:Rank
在上述中我们使用树的思想实现并查集,但是它依旧不够完美,主要体现在union上,在上述方法中我们是随意将一个节点置为另一棵树的子节点,而find操作的时间复杂度为O(h),h代表树的深度,如果我们如此随意的合并两棵树会导致最终的树深度特别大。

可以看到合并后的树有两种形式,我们当然应该寻找合并后树深度更小的树为合并结果。为此我们为每一节点添加一个属性——rank,它表示以该节点为根的树的深度。
public class UnionFindImpl4 implements IUnionFind {
private int[] parent;
private int[] rank;//存储以每一节点为根节点的树的深度
public UnionFindImpl4(int size){
parent = new int[size];
rank = new int[size];
for(int i=0;i<parent.length;i++){
parent[i] = i;
rank[i] = 1;//初始时树的深度都为1
}
}
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
//深度小的树添加到深度大的树中,无需更新rank值
//相同深度的两棵树可以随意添加,但是rank需要更新(+1即可)
if(rank[pRoot] < rank[qRoot]){
parent[pRoot] = qRoot;
} else if(rank[pRoot]>rank[qRoot]) {
parent[qRoot] = pRoot;
}else{
parent[qRoot] = pRoot;
rank[pRoot] += 1;
}
}
//其他方法不变……
}
优化:路径压缩1

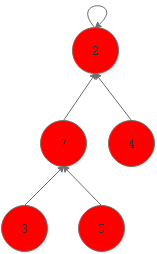
如图所示,这两棵树都是表示同一并查集,显然,如果并查集使用右侧的那棵树速度更加快,因为它的深度更小。事实上我们可以很简单的将左侧的树转换为右侧的树,我们将这一过程称为——路径压缩。
一行代码搞定路径压缩
修改find方法:
private int find(int p){
assert p>=0&&p<parent.length;
while(p!=parent[p]){
parent[p] = parent[parent[p]];//路径压缩:将当前节点的父节点设置成父节点的父节点
p = parent[p];
}
return p;
}
也许您会有疑问,路径压缩后我们是不是要去更新rank的值呢?答案是否定的,此时的rank值只是一个参考的值,并不确切的表示树的深度。
优化:路径压缩2

基于路径压缩的优化策略我们还可以更将完美的优化路径,此时这种路径压缩思想我们需要使用递归的思想。
依旧是修改find方法:
private int find(int p){
assert p>=0&&p<parent.length;
if(p!=parent[p]){
parent[p] = find(parent[p]);//递归设置父节点
}
return parent[p];
}
