背景
jdk 8
数据容器
在程序代码中,用来暂时存储数据的“盒子”(容器),用于后续的逻辑处理。
与HashMap比较
LinkedHashMap继承自HashMap,因此主数据结构、主功能与hashMap完全一样。
HashMap可以遍历key和value,此遍历是无序的(即插入的先后顺序与循历顺序不一致)。
LinkedHashMap遍历key或value是有序的(即插入(也可以是查询get()顺序)的先后顺序与循历顺序不一致)
linkedHashMap使用场景
需要像HashMap一样高性能,又需要数据元素循历时有序。
数据结构
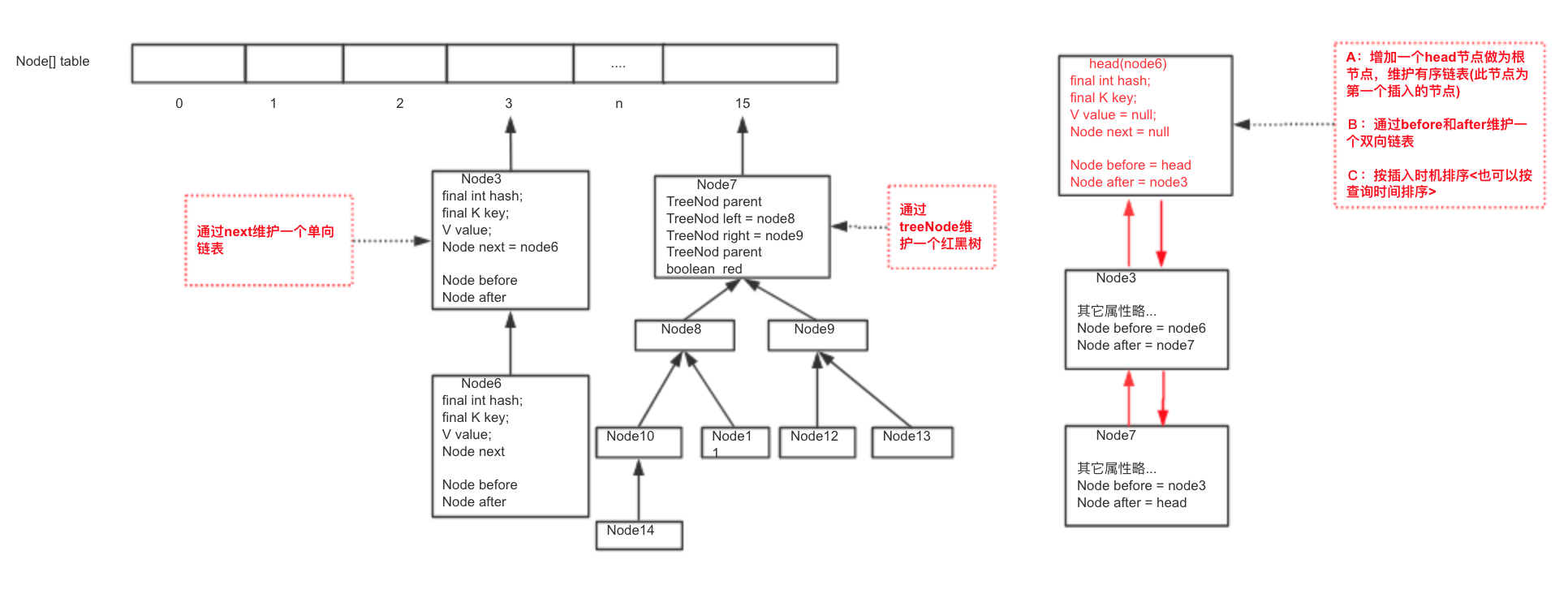
HashMap: 数组+链表/红黑树
linkedHashMap: 数组+链表/红黑树 + 额外的-双向链表
重要参数:
final boolean accessOrder;
LinkedHashMap存储的数据是有序的,不仅可以按插入时间有序,还可以按查询时间有序。而这有序方式则是通过accessOrder控制。如果accessOrder为false(默认),则是通过插入时间顺序,否则按查询时间有序(实际是混序:即不完全是按查询,而是按操作有序,只有对元素进行了操作<插入或查询>,就把元素放到双向链表尾部)。
对应构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
对应操作get/put,参照下面两个操作具体过程 。
put 执行过程:
A:put(key,value)
B:调用newNode()-linkedHashMap重写了此方法,并调用linkNodeLast()
C:调用linkNodeLast() - 把当前node插入到双向链表尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
get过程:
A:调用get(key)
B:LinkedHashMap重写了 HashMap中的get()方法,调用afterNodeAccess()
C:afterNodeAccess(),如果accessOrder为true,即如果按访问顺序排序,则把最新访问的节点放到双向链表尾部
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
遍历过程
LinkedHashMap与HashMap的最大区别就是有序,而是否有序主要体现在遍历过程中。
遍历主要通过LinkedHashMap两个重写的方法:keySet()和vaues(),分对代表key和value集合。返回的集合类LinkedKeySet和LinkedValues是对LinkedHashMap中双链表操作的"代理"。
KeySet和values仅仅是创建一个内部类LinkedKeySet或LinkedValues的对象,然后操作双向链表。
public Set<K> keySet() {
Set<K> ks;
return (ks = keySet) == null ? (keySet = new LinkedKeySet()) : ks;
}
public Collection<V> values() {
Collection<V> vs;
return (vs = values) == null ? (values = new LinkedValues()) : vs;
}
LinkedKeySet和LinkedValues 均继承自:LinkedHashIterator
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
public final K next() { return nextNode().getKey(); }
}
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
LinkedHashIterator 中的next指向head,即双向链表。
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}