前天618大促演练进行了全链路压测,在此之前刚好我的热key探测框架(点击可跳转到开源地址)也已经上线灰度一周了,小范围上线了2500台服务器,每秒大概接收几千个key探测,每天大概2-4亿左右,因为量很小,所以框架表现稳定。借着这次压测,刚好可以检验一下热key框架在大流量时的表现。毕竟作为一个新的中间件,里面很多东西还是第一次用,免不得会出一些问题。
压测期,我没有去扩容热key的worker集群,还是平时用的3个16C+1个4C8G的组合,3个16核是是主力,4核的是看上限能到什么样。
由于之前那一周的平稳表现,导致我有点大意了,没再去好好检查代码。导致实际压测期间表现有点惨淡。
框架的架构如下:
大概0点多压测开始,初始量比较小,从10w/s开始压,当然都是压的APP的后台,我的框架只是被动的接收后台发来的热key探测请求而已。我主要检测的就是worker集群,也就是那4台机器的情况。
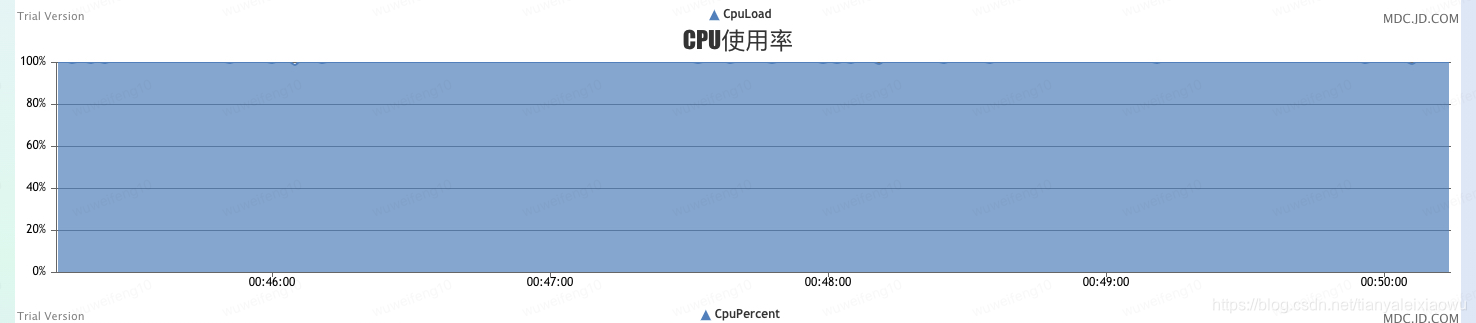
从压测开始的一瞬间,那台4核8G的机器就cpu100%,16核的cpu在90%以上,4核的100%即便在压测暂停的间隙也没有恢复,一直都是100%,无论是10w/s,还是后期40多w/s(废话,10万都凉了,40w当然也凉)。16核的在20w/s以上时也开始cpu100%,整体卡到不行了已经,连10秒一次的定时任务都卡的不走了,导致定时注册自己到etcd的任务都停了,再导致etcd里把自己注册信息过期删除,大量和client断连。
然后dashboard控制台监听etcd热key信息的监听器也出了大问题,热key产生非常密集,导致dashboard将热key入库卡顿,甚至于入库时,都已经过期1分钟多了,导致插入数据库的时间全部是错的。
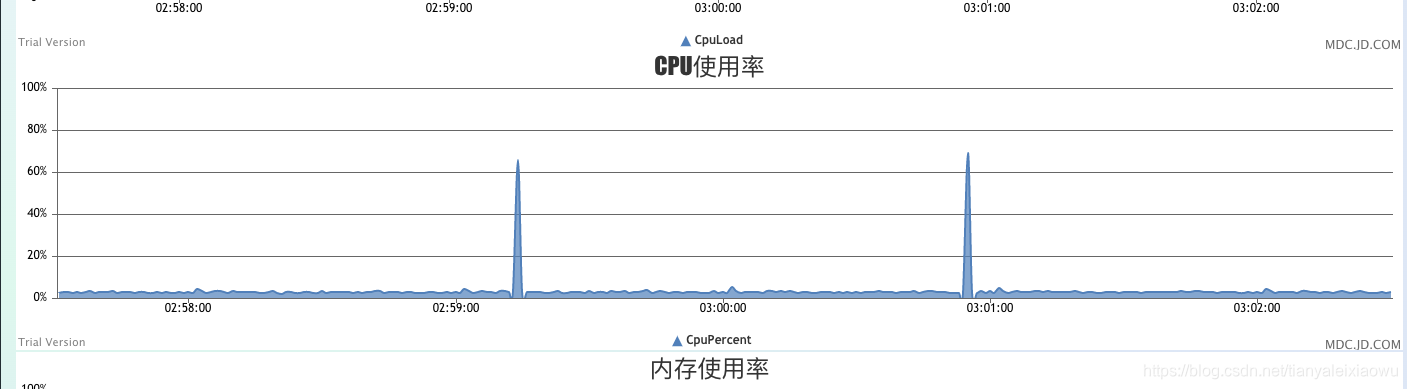
虽然worker问题蛮多,也蛮严重,但好在etcd集群稳如老狗,除了1分钟一次的热key密集过期导致cpu有个小尖峰,别的都非常稳定,接收、推送都很稳,client端表现也可以,没有什么异常表现。
其中etcd真的很不错,比想象中的更好,有图为证:
worker呢就是这样子
后来经过一系列操作,我还乐观的修改上线了一版,然后没什么用,在100%上稳的一匹。
后来经过我一天的研究分析,发现当时没找到关键点,改的效果不明显。当然后来我自我感觉找到问题点了,又修改了一些,有待下次压测检验。
这一篇就是针对各个发现的问题进行总结,包括压测期间的和之前灰度期间发现的一些。总的来说,无论书上写的、博客写的,各路这个说的那个说的虽然在本地跑的时候各种正常,但真正在大流量面前,未必能对。还有一些知名框架,参数配不好,效果未必达到预期。
平时发现的问题列表
先说压测前小流量时的问题
1 在worker端,会密集收到client发来的请求。其中有代码逻辑为先后取系统时间戳,居然有后取的时间戳小于前面的时间戳的情况(罕见、不能复现),猜测为docker时间对齐问题。造成时间戳相减为负值,代码数组越界,cpu瞬间达到100%。注意,这可是单线程的!
解决:问题虽然很奇葩,但很好解决,为负时,按0处理。
2 使用网上找的的netty自定义协议(我前几天还转过那篇问题),在本地测试以及线上灰度测试时,表现稳健。但在全量上线后,2千台client情况下,出现过单worker关闭一段时间并重启后,瞬间收到高达数GB的流量包,直接打爆内存,导致worker停机,后续无法启动的情况。
解决:书上及网上均未找到相关解决方案,类似场景别人极难遇到。后通过使用netty官方自带协议StringDecoder加分隔符后,未复现突传大包的情况,目前线上表现稳定。
3 Netty client是可以反复连接同一个server的,造成单个client对单个server产生多个长连接的情况,使得server的tcp连接数远远大于client的总数量。此前书上、网络教程等各个地方均未提及该情况。使得误认为,client对server仅会保持一个长连接。
解决:对client的连接进行排重、加锁,避免client反复连接同一个server。
4 Netty server在推送信息到大量client时,会造成cpu瞬间飙升至60-100%,推送完毕后cpu下降至正常值
解决:在推送时,避免做循环体内json序列化操作,应在循环体外进行
5 在复用netty创建出来的ByteBuf对象时,反复的使用它,会出现大量的报错。原因是对ByteBuf对象了解不深,该对象和普通的Java对象不一样,Java对象是可以传递下去反复使用的,不存在使用后销毁的情况,而ByteBuf在被netty传出去后,就销毁了,里面携带的字节组就没了
解决:每次都创建新的ByteBuf对象,不要复用它。
6 2千台client在监听到worker发生变化后,会同时瞬间去连接它,和平时上线时,每次几百台缓慢连接server的场景不同,突发瞬间数千连接时,可能发生server丢失一部分连接,导致部分client连接失败。
解决:不再采用监听的方式,而采用定时轮训的方式,错开连接的时机,对连不上的worker进行本地保存,后加一个定时任务,定时去连接那些没连上的server。
7 worker机器占用的内存持续增长,超过给docker分配的内存后,被系统杀死进程
解决:worker全部是部署在docker里的,刚开始我是没有给它配JVM参数的,譬如那个4核8G的,我只是将它部署上去,就没有管它了。随后,它的内存在持续稳定上涨,从未下降。直到内存爆满。后来经进入到容器内部,执行查看内存命令,发现虽然docker是4核8G的,但是宿主机是250G的。JVM采用默认的内存分配策略,初始分配1/64的内存,最大分配1/4的内存。但是是按250G进行分配的,导致jvm不断扩容再扩容,直到1/4 * 250G,在到达docker分配的8G时就被杀死了。后来给容器配置了JVM参数后,内存平稳。这块带来的经验教训就是,一定要给自己的程序配JVM,不然JVM按默认的执行,后果就不可控了。
压测发现的问题列表
前面发现的多是代码逻辑和配置问题,压测期间主要是cpu100%的问题,也列一下。
1 netty线程数巨多、disruptor线程数也巨多,导致cpu100%
问题描述:worker部署的jdk版本是1.8.20,注意,这个版本是在1.8里算比较老的版本。worker里面作为netty server启动,我是没有给它配线程池的(如图,之前boss和worker我都没有指定线程数量),所以它走的就是默认Runtime.getRuntime().availableProcessors() * 2。这个是系统获取核数的代码,在jdk1.8.31之前,docker容器内的这段代码获取到的是宿主机的核数,而非给容器分配的核数!!!譬如我的程序取到的就是32核,而非分配的4核。再乘以2后,变成了64个线程。导致netty boss和worker线程数高达64,另外我还用了disruptor,disruptor的consumer数量也是64!导致压测一开始,瞬间cpu切换及其繁忙,大量的空转。大家都知道,cpu密集型的应用,线程数最好比较小,等于核数是比较合适的,而我的程序线程数高达180,cpu全部用于轮转了。
之后我增加了判断jdk版本的逻辑,jdk1.8.31后的获取到的availableProcessors就是对的了,并且我限制了bossGroup的线程数为1.再次上线后,cpu明显有下降!
带来的经验教训是,用docker时,需要注意jdk版本,尤其是有获取系统核数的代码作为逻辑时。cpu密集型的,切勿搞很多线程。

2 cpu持续100%,导致定时任务都不执行了
和第一个问题是连锁的,因为worker接收到的请求非常密集,每秒达10万以上,而cpu已经全部用于N个线程的轮转了,真正工作的都没了,我的一个很轻的定时任务5s上传一次worker自己的ip信息到配置中心etcd,连这个定时任务都工作不ok了,通过jstack查看,一直处于wait状态。之后导致etcd里该worker信息过期被删除,再导致2千多个client从etcd没取到该worker注册信息,就把它给删掉了,发生了大量client没有和worker进行连接。
可见,cpu满时,什么都不靠谱了,核心功能都会阻塞。
3 caffeine密集扩容,耗费cpu大
因为worker里是用caffeine来存储各client发来的key信息的,之后读取caffeine进行存取。caffeine底层是用ConcurrentHashMap来进行的数据存储,大家都知道HashMap扩容的事,扩容2倍,就要进行一次copy,里面动辄几十万个key,扩容resize时,cpu会占用比较大。尤其是cpu本身负荷很重时,这一步也会卡住。
我的worker给caffeine分配的最大500万容量,虽然不是很大,但卡顿时,resize这一步执行很慢。不过这个不是什么大问题,也没有什么好修复的,就保持这样就行。
4 caffeine在密集失效时,老版本jdk下,caffeine默认的forkJoinPool有bug
caffeine我是设置的写入后一分钟过期,因为是密集写入,自然也会密集失效。caffeine采用线程池进行过期删除,不指定线程池时采用默认的forkJoinPool。问题是什么呢,大家自己也能试出来。搞个死循环往caffeine里写值,然后看它的失效。在jdk1.8.20之前,这个forkJoinPool存在不提交任务的bug,导致key过期后未被删除。进而caffeine容量爆满超过阈值,发生内存溢出。架构师针对该问题给caffeine官方提了issue,对方回复,请勿过于密集写入caffeine,写入过快时,删除跟不上。还需要升级jdk,至少要超过1.8.20.不然forkJoinPool也有问题。
5 disruptor消费慢
大名鼎鼎的disruptor实际表现并不如名气那么好,很多文章都是在讲disruptor怎么怎么牛x,一秒几百万。在worker里的用法是这样的,netty的worker线程池接收到请求后,统一全部发到disruptor里,然后我搞cpu核数个线程来消费这些请求,做计算热key数量的操作。而压测期间,cpu100%时,几乎所有的线程都卡在了disruptor生产上。即N个线程在这个生产者获取next序列号时卡住,原因很简单,就是没消费完,生产者阻塞。我设置的disruptor的队列长度为100万,实际应该写不满这个队列,但不知道为什么还是大量卡在了这个地方。该问题有待下次压测时检验。

6 有个定时任务里面有耗大量cpu的方法
之前为了统计caffeine的容量和占用的内存,我搞了个定时任务10秒一次上传caffeine的内存占用。就是被注释掉的那行,上线后坑到我了,那一句特别耗cpu。赶紧删掉,避免这种测试性质的代码误上线,占用大量资源。

7 数据库写入速度跟不上热key产生的速度
我是有个地方在监听etcd里热key的,每当有新key产生时,就会往数据库里插值。结果由于key瞬间来了好几千个,数据库处理不过来,导致大量的阻塞,等轮到这条key信息插入时,早就已经过期了,造成数据库里的数据全是错的。
这个问题比较好解决,可以做批量入库,加个队列缓冲就好了。
初步总结
其实里面有很多本地永远无法出现的问题,譬如时间戳的那个,还有一些问题是jdk版本的,还有是docker的。但最终都可以归纳为,代码不够严谨,没有充分考虑到这些可能会带来问题的地方,譬如不配JVM参数。
但是不上线又怎么都测试不出来这些问题,或者上线了量级不够时也发现不了。这就说明一个稳定健壮的中间件,是需要打磨的,不是说书上抄了一段netty的代码,上线了它就能正常运行了。
当然进步的过程其实就是踩坑的过程,有了相应的场景,实实在在的并发量,踩过足够的坑,才能打磨好一个框架。
也希望有相关应用场景的同学,关注京东热key探测框架。

 博客专家
博客专家