上次写了爬取笔趣阁小说,这次来爬点常用的表情包图片。
还是沿用上次的策略,找一个网速快点的地方,找个方便爬取的网站。
本次爬取的网站是:https://www.doutula.com/photo/list/
先上完整代码,点这里。
分为两步:
1、爬取单页;
①分析网页结构,获取图片下载地址。
②获取图片名和格式后缀。
③下载图片。
2、爬取多页。
1、爬取单页:
①分析网页结构,获取图片下载地址。
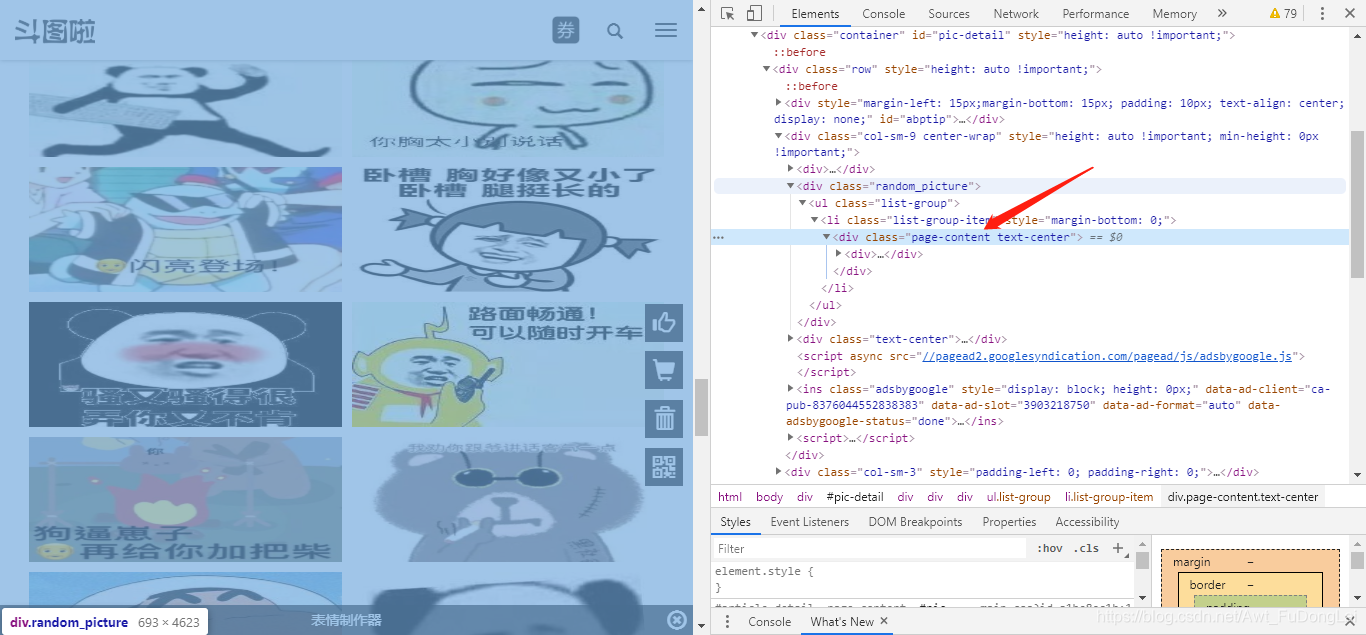
可以看到,所有图片都在这个div目录下。那么,通过下面代码,拿到这一页所有图片的下载地址。
r = requests.get(url, headers=headers)
text = r.text
# print(text)
bs = BeautifulSoup(text, 'html5lib')
imgs_div = bs.find_all('div', class_='page-content text-center')[0]
imgs_list = imgs_div.find_all('img')
for index, img in enumerate(imgs_list):
# print(img)
if img.has_attr('data-original'):
img_src = img['data-original']
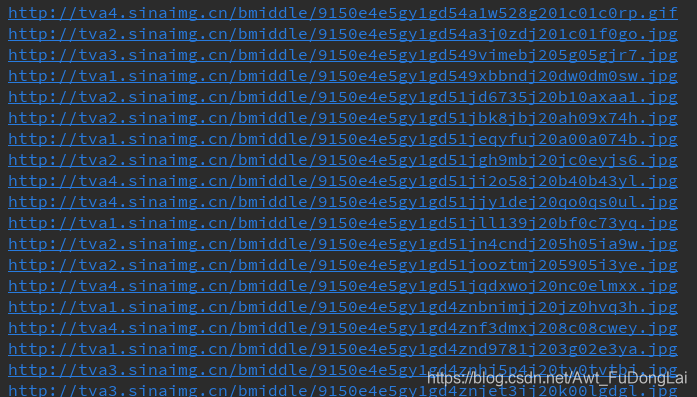
print(img_src)
打印如下:
②获取图片名和格式后缀。
既然是图片,我们还要获取它的文件名和后缀,方便以它们原有的格式存储。分析网页源代码:

通过下面代码拿到文件名和后缀。
img_front_name = img['alt']
img_end_name = img_src.split('.')[-1]
img_front_name = re.sub(r'[\??\.,。!!]', '', img_front_name)
img_name = str(img_front_name) + '.' + str(img_end_name)
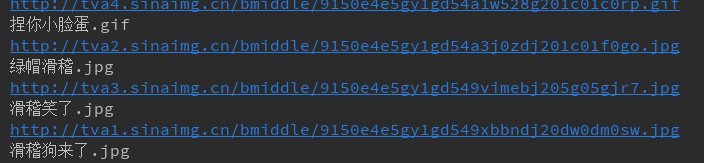
print(img_name)
打印如下:
③下载图片。
接下来就可以下载图片,并命名了。
res = requests.get(img_src, headers=headers)
with open('./images/' + img_name, 'wb') as fp:
fp.write(res.content)
2、爬取多页:
将上述步骤抽象成一个函数,然后加一个循环即可。
这里爬取第1到第5页。
for i in range(1, 6):
url = 'https://www.doutula.com/photo/list/?page=%d' % i
print("当前正在下载第%d页的图片,共有5页" % i)
catch_one_page(url)
print("第%d页的图片下载完成,共有5页" % i)
最终结果如下:

至此,代码结束。
不够好的是,没有加入多线程机制,导致下载的速度过慢,等我学习了,再来重构下代码。
