1. 基本概念
情感倾向分析接口(通用版):对只包含单一主体主观信息的文本,进行自动情感倾向性判断(积极、消极、中性),并给出相应的置信度。为口碑分析、话题监控、舆情分析等应用提供基础技术支持,同时支持用户自行定制模型效果调优
还是直接调用百度AI开放平台的接口,需要三个步骤:
① 创建应用(已完成!)
② 获取AccessToken(已完成!)
③ 调用接口做情感倾向分析(未完成!)
2. 情感倾向分析
1) 生成情感倾向分析接口的url
url_sentiment_classify = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=' + access_token
print(url_sentiment_classify)
–> 输出的结果为:(还是之前的access_token)
https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=24.6c5e1ff107f0e8bcef8c46d3424a0e78.2592000.1485516651.282335-857407
2) 进行情感倾向分析
步骤为:按照要求设置请求头 –> 创建变量,写入需要分词的文本 –> 用requests工具包发送请求 –> 返回处理结果
#按照要求设置请求头
headers = {'content-type': 'application/json'}
# 创建变量,写入需要分词的文本
st = '百度是一家高科技公司'
# 用requests工具包发送请求
response = requests.post(url_sentiment_classify,
data = json.dumps({'text': st}), # st变量写在这里
headers = headers)
if response:
result = response.json()
print(result)
–> 输出的结果为:(将所有的信息都返回在一个字典里面)
{'log_id': 244924604822151288,
'text': '百度是一家高科技公司',
'items': [{'positive_prob': 0.994472,
'confidence': 0.987716,
'negative_prob': 0.00552789,
'sentiment': 2}]}
3) 提取情感倾向分析结果
print(result['items'],'\n-------') # 提取items
print(result['items'][0],'\n-------') # 提取items中列表的第1个元素
print(result['items'][0]['negative_prob'],'\n-------') # 提取'negative_prob'信息
–> 输出的结果为:
[{'positive_prob': 0.994472, 'confidence': 0.987716, 'negative_prob': 0.00552789, 'sentiment': 2}]
-------
{'positive_prob': 0.994472, 'confidence': 0.987716, 'negative_prob': 0.00552789, 'sentiment': 2}
-------
0.00552789
-------
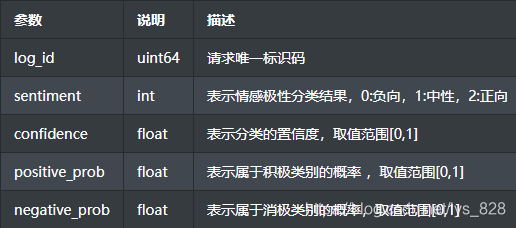
返回的参数官方的解析:(sentiment → 感情极性分类
positive_prob or negative_prob → 对于积极类别概率和消极类别概率,我们选择1个作为分析参数即可,可以看到之前的分析结果中{‘positive_prob’: 0.994472, ‘negative_prob’: 0.00552789},两者之和为1,所以如果选择negative_prob作为情感的量化指标,该指标>0.5代表本句话是负向,反之为正向)
3. 分析逻辑梳理及数据准备
对于实际新闻的文本内容,如果要查看其情感倾向变化分析,核心是如何做文字拆分。举个例子:如果我们可以把文章做断句,并对每句话都做情感倾向分析,就可以找到该文章的情感倾向变化趋势了。
这个过程中我们从positive_prob / negative_prob两者中选取一个量化指标即可,比如选择negative_prob,分析逻辑如下:
① 对文章进行断句处理,做好数据准备
② 针对每句话做情感倾向分析,并记录好negative_prob值
③ 结果整理,处理成表格型数据pandas.DataFrame
④ 绘制图表查看情感倾向变化趋势
4. 实战操作
1)首先是要进行文章断句处理
news = '''
孙杨的事情,还没有结束。最近,他的妈妈杨明,也被卷进了舆论风波中。在国际体育仲裁法庭宣布孙杨禁赛八年后,爱子心切的孙妈妈,在朋友圈发了一条长文。文章开头,就在哭诉儿子的不容易。之后,她就开始指责领导的不负责,指派律师的不专业。首先,她表明孙杨在08年因为身体不适服用了含有盐酸曲美他嗪的“万爽力。”当时,这药物还未变成“赛内禁用,赛外可用”的违禁药。直到过了6年,中国反兴奋剂网站才下发通知,表明“万爽力”是违禁药,强调运动员对此是毫不知情。当年不知情的孙杨,还是正常使用了“万爽力”,没想到体检是阳性,为此还被口头警告,要求罚款5000元。对于自己被“冤枉”,孙杨当然是不乐意的。但是在领导说出“不会影响成绩”后,孙杨妈妈选择先把这件事情放下,让儿子继续比赛。孙杨,也这么做了。听话的后果,就让这件事成为了“孙杨职业生涯最大的耻辱柱。”再之后参加国际听证会和仲裁会,孙杨妈妈也认为领导指派的律师专业性十分不强,影响了最终结果的判断,导致了自己儿子被禁赛8年的事情发生。整篇文章看下来,可以看出孙杨妈妈的不甘和怒气。也能看出,她意在把事情的全部责任,都推卸到别人身上。但是,真相似乎并不像孙杨妈妈所指的一样,孙杨被禁赛长达8年,只有别人的责任,自己毫无问题。前不久,有人在网上放出了孙杨妈妈在听证会的一段视频曝光。在听证会上,孙杨妈妈一直不愿正面回答对方提出的问题。并且不顾规则,总是中途打断对方,浪费了许多时间。法官问了三遍“孙杨是否撕毁了他之前签字的检验单?”孙杨妈妈是承认了,但却一直解释,自己儿子的暴力抗检,是“有理有据。”明明是回答是或者不是的问题,孙杨妈妈却一直自说自话,胡乱辩解。直到她的证词时间已经结束了,她还要强调“我还没说完。”不听安排,无视规则。而且据爆料,孙杨妈妈在去年6月,还曾私下联系过血检官和尿检官。这些,都是WADA明令禁止的。这一系列操作看下来,孙杨妈妈对于整件事而言,没有任何正面帮助,还帮了倒忙。在孙杨的成长道路,运动员生涯中,最离不开和最常见到的身影,就是他的妈妈杨明。作为曾经的浙江女排主力,专业的运动员,杨明深知运动员锻炼时间的重要性。在孙杨小时候,杨明是风雨无阻开车送儿子去训练,完全没有自我时间。为了让孩子把一切时间运用在游泳上,杨明更是把孙杨当成了“巨婴”去养。小学六年级,孙杨还不会系鞋带,上学训练也是从不背书包。在杨明的眼里,这些都是小事,什么事情,都没有游泳训练重要。对于自己无私奉献,杨明也是十分的骄傲。她认为是自己的牺牲成全,才有了现今的孙杨。不能否认,孙杨是一个游泳健将,他在国际赛事上的成绩,就是最好的证明。但私下里的孙杨,远没有他在国际体坛上表现的那么完美。生活中孙杨的不完美,也同样离不开母亲杨明的“帮助”。2010年,孙杨跟随朱志根前往澳大利亚训练。在公开训练场,19岁的孙杨没有围浴巾换泳裤,正好被外国女选手撞见。女选手走后找到了教练朱志根,希望他能能提醒孙杨不要再做这种不雅的事情。孙杨对于自己做过的事情是矢口否认,连着被问两次,他也强硬表示“决无此事。”明明在撒谎却如此有底气,气不过的朱志根直接给了孙杨一巴掌。这件事被杨明知道后,她并没有平息双方怒火,反而火上浇油向学院领导打了电话,痛斥教练不尊重孙杨,伤害了孩子的自尊心。之后,杨明为了孙杨的运动生涯,更是多次与人起过冲突,丝毫不在意他人的看法。为照顾孙杨,杨明要求住进运动员酒店与儿子同住。为孙杨的游泳训练,杨明在现场记录对手的训练记录,还会对着旁人埋怨:“这要换成朱志根,他能做到这些?”对于集体安排的活动,杨明有异议就直接向国家体育总局开炮。孙杨成绩不如意,杨明不去想儿子的问题,而是去指责教练教导的有问题。有媒体不远万里从巴西过来想要采访孙杨,杨明直接问了一句:你们电视节目在巴西放,对我们有什么好处?对国外的记者不客气,杨明对国内的记者媒体,也十分的不礼貌。有一次孙杨进行完体能训练走出场馆后,记者和粉丝拿着镜头对孙杨拍照。身为领队和母亲的杨明,看到现场状况后疯狂发飙,大喊:“别拍了!烦死了!讨厌死了!”更有传言称,杨明还用水瓶砸了一个记者的相机。据知情者爆料,孙杨在天津训练时不仅要求卡宴,奥迪接送,下水前还要母亲和保镖陪着。杨明更是大牌到只接受央视记者的采访,其余的记者,通通不见。事情被报道后,杨明着重强调是“无中生有。”孙杨更是为妈妈开了个发布会,“希望大家能够理解妈妈。”接受其他采访,杨明更是对主持人有很大的意见,在现场就直接黑脸。杨明仗着孙杨的名气耍大牌,对儿子一次次的纵容和任性,终于惹怒了训练队。12年伦敦奥运结束才半年,孙杨就开始不听组织安排不服从纪律。在运动员最需要集中系统训练的时候,孙杨不仅私自谈恋爱,还频繁出席商业活动。面对教练的批评,孙杨根本不听,还对着朱志根说“你的训练太落后,我不跟你练了。”一次次的顶撞冲突,浙江体育职业技术学院对孙杨做出了严厉处罚。院长接受采访时,也明确表明“在浙江只有优秀运动员,没有特殊运动员。”经历耍大牌,不听要求,被训练队惩罚后,孙杨的名气一落千丈,个人形象顷刻坍塌。这时的孙杨,仍没有吸收教训,触犯了法律,因为无证驾驶被行政拘留了7天。而且在交涉过程中,孙杨再一次撒了慌,对外说自己有驾驶证。同时还被曝出早前就曾多次在没有驾照的情况下独自驾车外出。个人形象再次受损。也因为这次无证驾驶,孙杨的空姐女友浮出了水面。孙杨对于这个女友也是十分宝贝,曾对着母亲杨明说要把她娶进门。但杨明并不满意这个比孙杨大6岁的女朋友,并未同意。后有媒体拍到该空姐曾带着一个孩子外出,有不少人怀疑这个孩子是孙杨的私生子。只不过孙杨对外,从未正面回应过。对外风评不佳,在队里,孙杨也不受队友的待见。有队友爆料,孙杨成绩提高后十分傲慢目中无人。孙杨也因为傲慢性格被孤立后,就开始和圈外的狐朋狗友交朋友,逛夜店,泡歌厅。这些事情,放在任何一个公众人物身上,都能让他一蹶不振很难东山再起。但对于有着超强业务能力的孙杨来说,这些都不是问题。即使有负面新闻缠身,在他再次取得取得傲人成绩后,人们就逐渐忘记了他之前的任性耍大牌。摇身一变,孙杨又成为了大家眼中可爱的大白杨。即使后面他因穿个人签约品牌违反规定遭争议,孙杨也并未回应。而这些也都未击垮他的职业生涯,观众们也没做太多关心。直到14年,孙杨因为服用违禁药品问题,完美的职业生涯出现了一个缺口。这一次的抗检事件,更成为压死骆驼的最后一根稻草。孙杨也为他的不配合,蛮横嚣张的态度付出了太过于沉重的代价。而这背后,离不开他母亲杨明在后面的无限纵容,推波助澜。从此次她在听证会的表现可看出,这么多年,她的脾气仍没有改变,面对官方和媒体,她依旧按着自己的那一套处理事情。她以为靠着自己的七寸不烂之舌可以为儿子洗清冤屈,殊不知她的一番话,把孙杨推向了摸不见底的深潭。这次孙杨能被禁赛长达8年,更是离不开她的“亲力亲为。”事情再次发酵后,杨明删除了朋友圈的控诉,孙杨的微博里,也没有他当晚发的几条证据。好在孙杨这次还有上诉的机会,如若成功,他的职业生涯还能延长几年。希望这次惨痛教训能让孙杨妈妈知道,孙杨,早就不是象牙塔里的孩子。你的亲切关怀不是蜜糖,是砒霜。29岁的孙杨,也应该明白,人生除了比赛,还有做人。奥运冠军的光环,不可能罩着你一辈子。
'''
news_r = news.replace('孙杨妈妈', '孙母')
news_r = news_r.replace('孙妈妈', '孙母')
news_r = news_r.replace('母亲', '孙母')
news_r = news_r.replace('杨明', '孙母')
news_r = news_r.replace('妈妈', '孙母')
news_r = news_r.replace('儿子', '孙杨')
#还可以加更多的替换
sentenceslst = news_r.split('。')
print(type(sentenceslst))
print(len(sentenceslst))
sentenceslst[:5]
–> 输出的结果为:(这里还是针对孙杨的那篇文章)
<class 'list'>
95
['\n孙杨的事情,还没有结束',
'最近,他的妈妈杨明,也被卷进了舆论风波中',
'在国际体育仲裁法庭宣布孙杨禁赛八年后,爱子心切的孙妈妈,在朋友圈发了一条长文',
'文章开头,就在哭诉儿子的不容易',
'之后,她就开始指责领导的不负责,指派律师的不专业']
2) 逐句做情感倾向分析
① 这里构建函数做情感倾向分析,以negative_prob为情感倾向量化指标
def sentiment_ana(text):
# 写入参数text
responsei = requests.post(url_sentiment_classify,
data = json.dumps({'text': text}),
headers = headers)
if response:
return responsei.json()['items'][0]['negative_prob']
# 情感倾向分析测试
print(sentenceslst[0])
print(sentiment_ana(sentenceslst[0]))
–> 输出的结果为:
孙杨的事情,还没有结束
0.952837
② 遍历循环,实现逐句做情感倾向分析
sc_data = []
# 导入time模块,用于查看代码执行时间
import time
start_time = time.time()
# for循环遍历
for i in sentenceslst:
try:
sen_dic = {'sentence':i, 'negative_prob':sentiment_ana(i)} # 创建字典存储情感倾向分析结果
sc_data.append(sen_dic) # 将结果存入列表
except:
continue
# 计算代码执行时间
end_time = time.time()
print('代码运行时间(s):', end_time - start_time)
sc_data[:5]
–> 输出的结果为:
代码运行时间(s): 17.278812885284424
[{'sentence': '\n孙杨的事情,还没有结束', 'negative_prob': 0.952837},
{'sentence': '最近,他的妈妈杨明,也被卷进了舆论风波中', 'negative_prob': 0.162765},
{'sentence': '在国际体育仲裁法庭宣布孙杨禁赛八年后,爱子心切的孙妈妈,在朋友圈发了一条长文',
'negative_prob': 0.248906},
{'sentence': '文章开头,就在哭诉儿子的不容易', 'negative_prob': 0.395767},
{'sentence': '之后,她就开始指责领导的不负责,指派律师的不专业', 'negative_prob': 0.99982}]
3) 分析结果数据整理
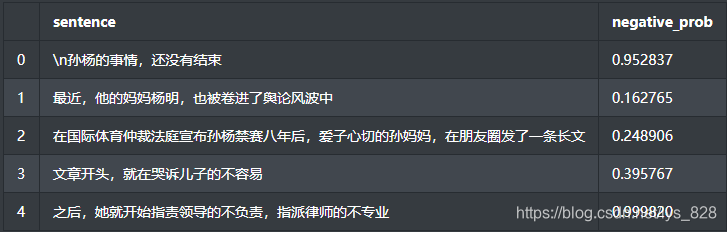
对于已经处理好的sc_data,由于字典列表格式并不是很方便做数据分析,这里我们需要把它整理成表格型数据,也就是转化为DataFrame数据
df_sen = pd.DataFrame(sc_data)
print(df_sen.head())
–> 输出的结果为:(【0-1】之间,偏向1说明情感偏向负向)
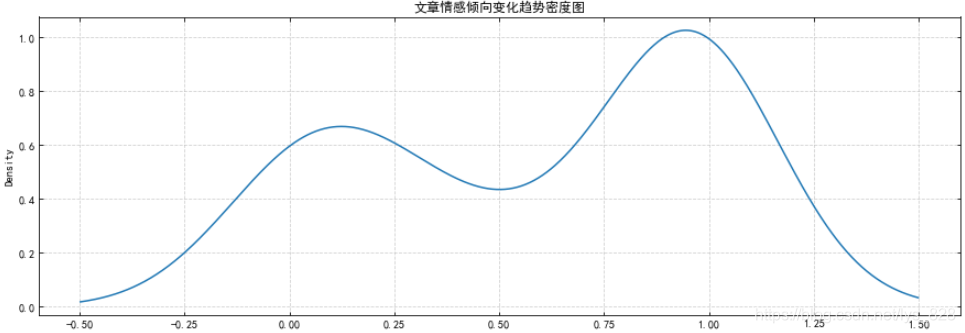
4) 绘制图表查看情感倾向变化趋势
df_sen['negative_prob'].plot(title = '文章情感倾向变化趋势密度图',
figsize = (15,5),
kind = 'kde',
grid = True)
–> 输出的结果为:(横坐标代表negative_prob字段的值区间,准确来说其值区间应该是[0:1],但由于密度图是平滑曲线所以<0以及>1的值也显示在图表上了,但这里无具体意义可以忽略;纵坐标代表密度,可以理解为negative_prob字段对应值的出现频率比较,由于negative_prob在[0:0.5]区间代表正向情绪,[0.5:1]代表负向情绪,所以从图中可以看出文章整体情感倾向是负向,峰值在[0.75:1]之间)
5. 绘制情感倾向指标趋势曲线折线图
from pyecharts.charts import Line
from pyecharts import options as opts
c = (
Line()
.add_xaxis(x)
.add_yaxis("情感倾向指标", y, is_smooth=True,)
.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="情感倾向指标趋势曲线 折线图"),
datazoom_opts=[opts.DataZoomOpts()],
xaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_align_with_label=True),
is_scale=False,
boundary_gap=False,
),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
)
)
.render("C:\\Users\\86177\\Desktop\\line.html")
)
–> 输出的结果为:(有不理解的可以直接参考官方文档进行绘制图形和添加参数)
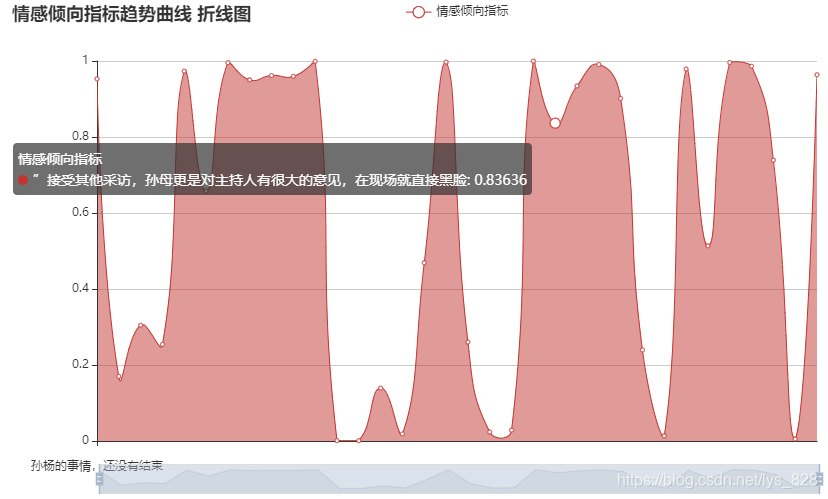
成功绘制情感倾向指标趋势曲线折线图,可以更直观的看到整篇文章按句顺序的情感倾向指标及趋势:整理呈现负向,且在前小段及后大半部分负向情绪较为明显。
