数据结构--查找
基本概念
- 生活中处处有查找,例如:搜索引擎、大数据问题等等。
- 我们学习查找想要解决的问题:对于超大数据量,如何提高查找的效率?
- 基本概念:
- 关键码:用以标识一个记录的某个数据项。如果该关键码可以唯一的标识一条记录,则称为主关键码,反之为次关键码。
- 查找:在具有相同类型的记录集中找出满足给定条件的记录。
- 查找结果:在查找集中找到匹配的记录,称为查找成功;否则查找失败。一般情况下,查找需要返回记录的位置。

P.S.
- 散列技术其实有很多,例如HASH哈希(题外话:在python中,字典就是一种哈希映射~欲知详情,请查看我的另一篇笔记
),散列查找的效率是相当高的,在最近十几年才崛起。 - 二叉排序树与平衡二叉树的区别?
因为对于一组无序数据,通过二叉排序树排序以后得到的树有很大可能是不平衡的(左右子树大小相差太多),而平衡二叉树称得上是二叉排序树的升级版,可以解决左右子树不平衡的问题。
**思考:**查找结构与存储结构有什么区别?
线性表查找
顺序查找
问题: 对于乱序数据,如何快速查找出关键字Key是否在乱序中?若是,如何返回位置?
方法一:简单粗暴的直接查找
int search(int a[],int n,int key)
{
for(int i=0;i<n;i++)//①
if(a[i] == key)//②
return i+1;//找到key,返回位置
return 0;//没有找到,返回0
}
反思: 上述代码的时间复杂度?是O(n^2),因为有二次比较。
思考: 如何进一步提高效率?
方法二:哨兵法–用空间换时间
思想: 对于长度为n的乱序表,另建一个长度为n+1的表,其中a[0]做哨兵,其值赋为key。哨兵的意义–使函数无论如何都会返回一个值,而且只需要比较一次。
int search(int a[],int n,int key)
{
a[0] = key; //哨兵
for(int i=n;a[i]!=key;i--); //从后向前查找
return i; //如果找到key,就返回位置i,没有找到,就返回0
}

计算ASL:
- 查找不成功 ASL = n+1
- 查找成功
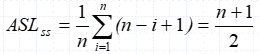
折半查找(敲黑板:必考题)
思考: 折半法的前提是什么?待查找序列为有序表。
基本思想: 先确定待查记录所在的范围,再用二分法逐步缩小范围直到找到或找不到且查完整个表。
再思考: 对存放在数组中的有序表,如何快速找到Key?



注意:
- (以上题为例)low的第一次移动要移动到 mid+1,因为mid原来坐在的位置,数据已经比较过一次了,可以直接跳到它的下一个。(同理:high=mid-1)
- 如何判断没有找到key?
low > high 时就说明没有找到。换句话说,循环条件就是 low<=high
int Search_Bin(int a[],int n,int key)
{
int low = 1;
int high = n;
while(low<=high)
{
mid = (low+high)/2;
if(key == a[mid])
return mid;
else if (key<a[mid])
high = mid-1;
else
low = mid +1;
}
return 0;
}
折半查找的性能分析
折半查找的判定树:

- 一般情况下,表长为n的折半查找的判定树的深度和含有n个结点的完全二叉树的深度相同。
所以:

索引查找(分块查找)
- 分块查找的性能介于顺序查找和折半查找。只用于分段有序的信息表。
- 分段查找的核心思想:在建立顺序表的同时,建立一个索引表。
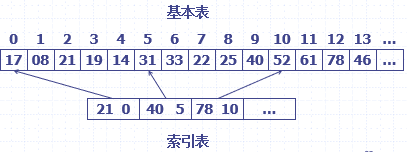
- 可以看出索引表可以用折半查找,而基本表不可以。
- 基本思想:首先根据索引表确定待查记录的区间,然后再确定的主表区间采用顺序查找。(索引思想是当前大数据处理方面常用的思想。)
- 性能分析:

缺点:需要有辅助数组,且初始表要经过分块排序。
三种查找方式的比较
| 查找方式 | 性能 | 适用条件 |
|---|---|---|
| 顺序查找 | ASL= (n+1)/2 或n+1,性能最差 | 乱序表 |
| 折半查找 | ASL=(2log)n 或 (2log)n+!,性能最好 | 有序表 |
| 分块查找 | 性能位于前两者中间 | 分块有序表 |
然而这三者都只适用于静态查找。如果我们想在查找的同时,对一些记录进行添加、删除操作,就要使用下面的树表。

