笔者最近需要使用pyspark进行数据整理,于是乎给自己整理一份使用指南。pyspark.dataframe跟pandas的差别还是挺大的。
1、——– 查 ——–
— 1.1 行元素查询操作 —
像SQL那样打印列表前20元素
show函数内可用int类型指定要打印的行数:
df.show()
df.show(30)以树的形式打印概要
df.printSchema()获取头几行到本地:
list = df.head(3) # Example: [Row(a=1, b=1), Row(a=2, b=2), ... ...]
list = df.take(5) # Example: [Row(a=1, b=1), Row(a=2, b=2), ... ...]查询总行数:
int_num = df.count()
查询某列为null的行:
from pyspark.sql.functions import isnull
df = df.filter(isnull("col_a"))输出list类型,list中每个元素是Row类:
list = df.collect()注:此方法将所有数据全部导入到本地,返回一个Array对象
jdbcDF.collectAsList()功能和collect类似,只不过将返回结构变成了List对象
— 1.2 列元素操作 —
获取Row元素的所有列名:
r = Row(age=11, name='Alice')
print r.__fields__ # ['age', 'name']选择一列或多列:select
df["age"]
df.age
df.select(“name”)
df.select(df[‘name’], df[‘age’]+1)
df.select(df.a, df.b, df.c) # 选择a、b、c三列
df.select(df["a"], df["b"], df["c"]) # 选择a、b、c三列重载的select方法:
jdbcDF.select(jdbcDF( "id" ), jdbcDF( "id") + 1 ).show( false)会同时显示id列 + id + 1列
还可以用where按条件选择
jdbcDF .where("id = 1 or c1 = 'b'" ).show()— 1.3 排序 —
orderBy和sort:按指定字段排序,默认为升序
df = df.sort("age", ascending=False)
jdbcDF.orderBy(- jdbcDF("c4")).show(false)
// 或者
jdbcDF.orderBy(jdbcDF("c4").desc).show(false)按指定字段排序。加个-表示降序排序
2、——– 增、改 ——–
— 2.1 新增数据列 withColumn—
withColumn是通过添加或替换与现有列有相同的名字的列,返回一个新的DataFrame
result3.withColumn('label', 0)**报错:**AssertionError: col should be Column,一定要指定某现有列
有两种方式可以实现:
一种方式通过functions
from pyspark.sql import functions
result3 = result3.withColumn('label', functions.lit(0))另一种方式通过另一个已有变量:
result3 = result3.withColumn('label', df.result*0 )修改原有df[“xx”]列的所有值:
df = df.withColumn(“xx”, 1)修改列的类型(类型投射):
df = df.withColumn("year2", df["year1"].cast("Int"))修改列名
jdbcDF.withColumnRenamed( “id” , “idx” )
— 2.2 过滤数据—
过滤数据(filter和where方法相同):
df = df.filter(df['age']>21)
df = df.where(df['age']>21)多个条件jdbcDF .filter(“id = 1 or c1 = ‘b’” ).show()
对null或nan数据进行过滤:
from pyspark.sql.functions import isnan, isnull
df = df.filter(isnull("a")) # 把a列里面数据为null的筛选出来(代表python的None类型)
df = df.filter(isnan("a")) # 把a列里面数据为nan的筛选出来(Not a Number,非数字数据)3、——– 合并 join / union ——–
3.1 横向拼接rbind
result3 = result1.union(result2)
jdbcDF.unionALL(jdbcDF.limit(1)) # unionALL— 3.2 Join根据条件 —
单字段Join
合并2个表的join方法:
df_join = df_left.join(df_right, df_left.key == df_right.key, "inner")其中,方法可以为:inner, outer, left_outer, right_outer, leftsemi.
多字段join
joinDF1.join(joinDF2, Seq("id", "name"))混合字段
joinDF1.join(joinDF2 , joinDF1("id" ) === joinDF2( "t1_id"))跟pandas 里面的left_on,right_on
— 3.2 求并集、交集 —
jdbcDF.intersect(jdbcDF.limit(1)).show(false)intersect方法可以计算出两个DataFrame中相同的记录
jdbcDF.except(jdbcDF.limit(1)).show(false)except获取一个DataFrame中有另一个DataFrame中没有的记录
— 3.3 分割:行转列 —
有时候需要根据某个字段内容进行分割,然后生成多行,这时可以使用explode方法
下面代码中,根据c3字段中的空格将字段内容进行分割,分割的内容存储在新的字段c3_中,如下所示
jdbcDF.explode( "c3" , "c3_" ){time: String => time.split( " " )}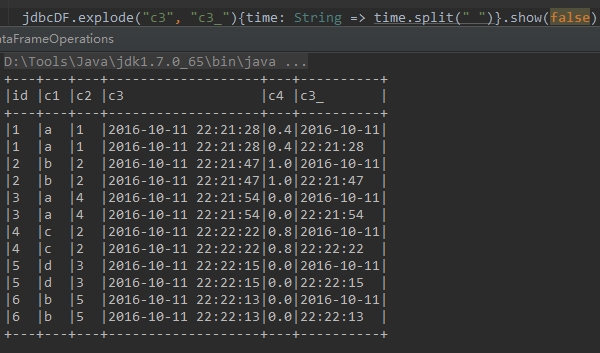
4 ——– 统计 ——–
— 4.1 频数统计与筛选 —-
jdbcDF.stat.freqItems(Seq ("c1") , 0.3).show()根据c4字段,统计该字段值出现频率在30%以上的内容
— 4.2 分组统计—
groupBy方法整合:
GroupedData = df.groupBy(“age”)应用单个函数
(按照A列同名的进行分组,组内对B列进行均值计算来合并):
df.groupBy(“A”).avg(“B”).show()应用多个函数:
from pyspark.sql import functions
df.groupBy(“A”).agg(functions.avg(“B”), functions.min(“B”), functions.max(“B”)).show()整合后GroupedData类型可用的方法(均返回DataFrame类型):
avg(*cols) —— 计算每组中一列或多列的平均值
count() —— 计算每组中一共有多少行,返回DataFrame有2列,一列为分组的组名,另一列为行总数
max(*cols) —— 计算每组中一列或多列的最大值
mean(*cols) —— 计算每组中一列或多列的平均值
min(*cols) —— 计算每组中一列或多列的最小值
sum(*cols) —— 计算每组中一列或多列的总和
— 4.3 apply 函数 —
将df的每一列应用函数f:
df.foreach(f) 或者 df.rdd.foreach(f)将df的每一块应用函数f:
df.foreachPartition(f) 或者 df.rdd.foreachPartition(f)—- 4.4 【Map和Reduce应用】返回类型seqRDDs —-
df.map(func)
df.reduce(func)——– 5、删除 ——–
df.drop('age').collect()
df.drop(df.age).collect()dropna函数:
df = df.na.drop() # 扔掉任何列包含na的行
df = df.dropna(subset=['col_name1', 'col_name2']) # 扔掉col1或col2中任一一列包含na的行
——– 6、去重 ——–
6.1 distinct:返回一个不包含重复记录的DataFrame
返回当前DataFrame中不重复的Row记录。该方法和接下来的dropDuplicates()方法不传入指定字段时的结果相同。
示例:
jdbcDF.distinct()6.2 dropDuplicates:根据指定字段去重
根据指定字段去重。类似于select distinct a, b操作
示例:
jdbcDF.dropDuplicates(Seq("c1"))——– 7、 格式转换 ——–
pandas-spark.dataframe互转
Pandas和Spark的DataFrame两者互相转换:
pandas_df = spark_df.toPandas()
spark_df = sqlContext.createDataFrame(pandas_df)转化为pandas,但是该数据要读入内存,如果数据量大的话,很难跑得动
转化为RDD
与Spark RDD的相互转换:
rdd_df = df.rdd
df = rdd_df.toDF()——– 8、SQL操作 ——–
DataFrame注册成SQL的表:
df.createOrReplaceTempView("TBL1")进行SQL查询(返回DataFrame):
conf = SparkConf()
ss = SparkSession.builder.appName("APP_NAME").config(conf=conf).getOrCreate()
df = ss.sql(“SELECT name, age FROM TBL1 WHERE age >= 13 AND age <= 19″)