1 Spark源码的下载
作为一名大数据开发工程师,研读源码是我们日常开发学习中必不可少的环节,而万里长征的第一步就是编译源码。开源Spark主要有3大发行版Apache,CDH和HDP,本文以Apache Spark 2.4.5为例展开。
1) 访问Apache Spark官网http://spark.apache.org/,点击Download

2)选择版本和文件类型
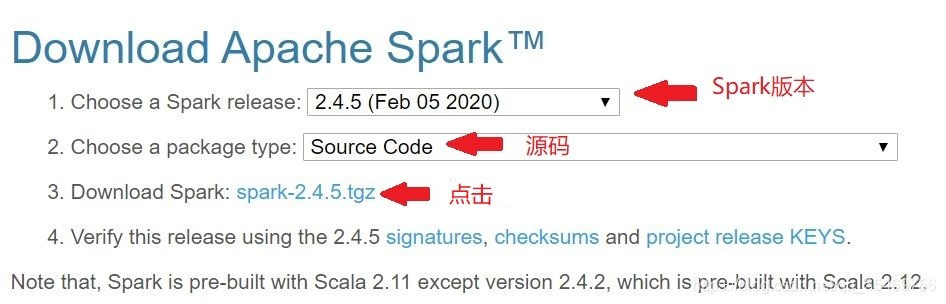
特别注意最后一行声明,除了Spark2.4.2版本依赖Scala 2.12,其余Spark版本都依赖Scala 2.11。
3) 下载源码的压缩包到本地

4)博主是下载到Linux上,使用tar解压文件夹
root@ubuntu18:~/workspace# tar -zxvf ep spark-2.4.5.tgz
root@ubuntu18:~/workspace# ls | grep spark-2.4.5
spark-2.4.5
spark-2.4.5.tgz
2 Spark源码的编译
Spark源码编译的方式有maven和sbt两种,本文选取maven为例进行编译。
2.1 准备系统环境
Java 1.8
Scala 2.11
Maven 3.6.1
这些组件的安装教程网上很多,因此不再赘述。有一点需要补充,编译Spark需要较大堆内存,因此需要提高maven堆内存的上限。
root@ubuntu18:~/workspace# vim /etc/profile
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
2.2 执行编译过程
root@ubuntu18:~/workspace# cd spark-2.4.5
#参数-T代表线程数,可以并行地构建那些相互间回没有依赖关系的模块,充分利用多核CPU资源,博主虚拟机是4核心,因此设置为4。
root@ubuntu18:~/workspace/spark-2.4.5# build/mvn -T 4 -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0
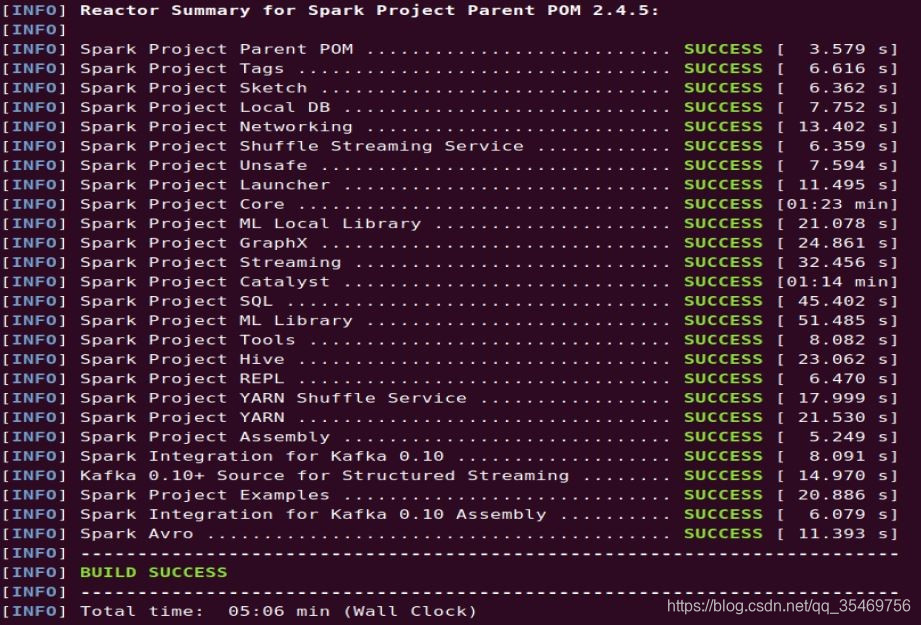
运行结果如下图所示,博主是以前编译过的,因此maven仓库已经存在相关依赖,所以采用了5分钟,如果是第一次编译,时间会比较久,当时来回折腾了好几个小时。
2.3 编译过程遇到问题
编译过程中,可能存在因为网络等问题,导致某一模块编译失败,建议重新编译当前模块。比如在spark-streaming-kafka模块编译失败。
root@ubuntu18:~/workspace/spark-2.4.5#build/mvn -T 4 -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 clean package -rf :spark-streaming-kafka-0-10_2.11
3 使用Spark交互环境(REPL)开发wc
3.1 新建数据集
root@ubuntu18:~/workspace/spark-2.4.5# vim ./data/wc.txt
写入内容:
tensorflow pytouch
python java scala
elasticsearch spark
hadoop spark
3.2 打开REPL
root@ubuntu18:~/workspace/spark-2.4.5#./bin/spark-shell
3.3 编写wc的代码
scala> val rdd = sc.textFile ("file:///root/workspace/spark-2.4.5/data/wc.txt")
rdd: org.apache.spark.rdd.RDD[String] = file:///root/workspace/spark-2.4.5/data/wc.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> rdd.flatMap(line => line.split("//s+")).map(word => (word, 1)).reduceByKey(_ + _).collect
res0: Array[(String, Int)] = Array((python java scala,1), (hadoop spark,1), (elasticsearch spark,1), (tensorflow pytouch,1))
4 在Idea调试Spark自带的案例wc
4.1 导入源码
将源码导入到idea。执行此步骤之前,需要调整idea JVM参数,增到JVM堆内存的大小,否则后面运行时会出现idea会卡死,挂掉的现象。
root@ubuntu18:~# vim /usr/local/idea-IU-182.4129.33/bin/idea.vmoptions
-Xms512m
-Xmx1024m
-XX:ReservedCodeCacheSize=300m
4.2 向主函数传入参数
wc案例需要传入统计的文本,在idea中具体参数可以通过main函数传递。
在JavaWordCount类点击鼠标右键,选择Creat ‘JavaWordCount.Main’
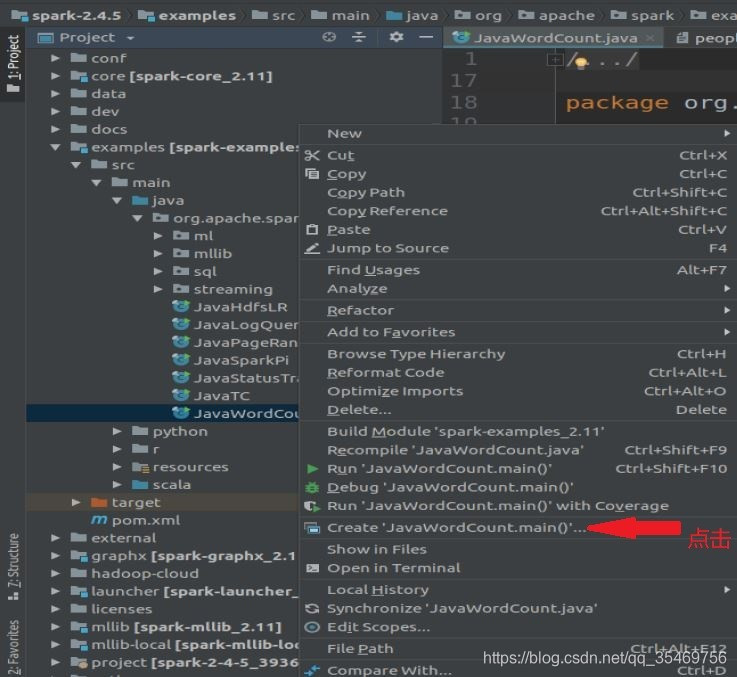
填写参数:

1)VM options:-Dspark.master=local,表明Spark是本地运行模式
2)Program arguments:传入要统计的文件地址。
3)勾选包含scope值为Provided
4.3 运行程序
在JavaWordCount类点击鼠标右键,选择Run “JavaWordCount.main()” with Coverage
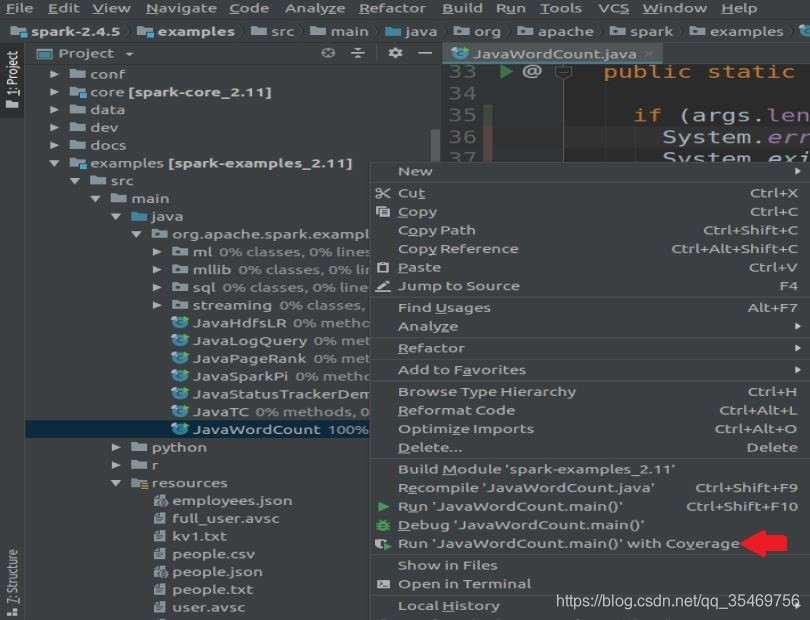
运行结果会打印在控制台:
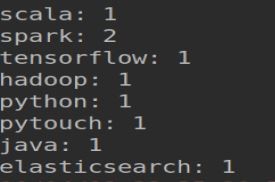
4.4 遇到问题
1)编译成功,运行过程还报XX类缺失
打开idea的Maven Projects,在对应的模块上面点击鼠标右键执行“Generate Sources and Update Folders For All Projects”即可。
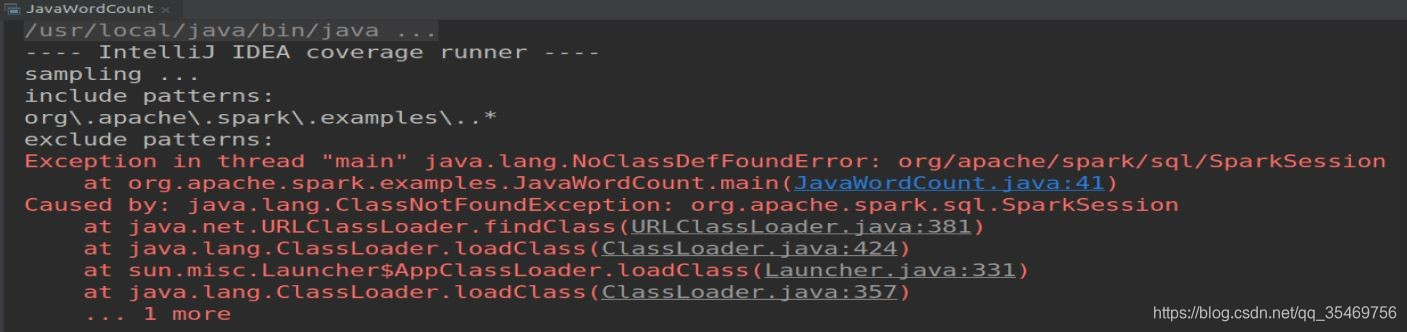
2)运行过程中报java.lang.NoClassDefFoundError异常
Provided的作用是打包过程中会将带有Provided的依赖exclude,可以减轻发布包的大小。但在本实验中,我们需要在运行wc案例的时候依赖这些组件,如果不勾选,运行时候就找不到相关依赖,会报java.lang.NoClassDefFoundError异常。
5 参考文献
- 《Spark源码分析调试环境搭建》 https://zhuanlan.zhihu.com/p/30333691
- Apache spark官方文档
- 耿嘉安,Spark内核设计的艺术:架构设计与实现 第1版. 2018, 机械工业出版社.
