文章目录

1 概述
对图片进行分类是常见的计算机视觉任务,其中对交通标志图片的分类是自动驾驶识别算法中必不可少的,在本文,我们一起学习怎么用tensorflow2实现一个交通标志图片分类器并最终达到98%的准确率。
我在本文里使用的是jupyter notebook,读者朋友也可以使用其他编辑器。
2 数据集
本文使用的数据是一份德国的交通标志图片,数据地址为:https://bitbucket.org/jadslim/german-traffic-signs
2.1 下载数据
首先,我们把数据下载下来。
git clone https://bitbucket.org/jadslim/german-traffic-signs
cd german-traffic-signs
ls
signnames.csv test.p train.p valid.p
head signnames.csv
ClassId,SignName
0,Speed limit (20km/h)
1,Speed limit (30km/h)
2,Speed limit (50km/h)
3,Speed limit (60km/h)
4,Speed limit (70km/h)
5,Speed limit (80km/h)
6,End of speed limit (80km/h)
7,Speed limit (100km/h)
8,Speed limit (120km/h)
下载下来的文件有3个pickle序列化的文件和一个csv文件,可以看到csv文件是分类的id对应的名称;3个pickle文件分别为测试、训练和验证数据。我们接下加载数据并分析一下数据的构成。
2.2 分析数据
我们分别使用pickle和pandas来加载这些数据。
import pickle
import pandas as pd
with open('german-traffic-signs/train.p', 'rb') as f:
train_data = pickle.load(f)
with open('german-traffic-signs/valid.p', 'rb') as f:
val_data = pickle.load(f)
with open('german-traffic-signs/test.p', 'rb') as f:
test_data = pickle.load(f)
signnames = pd.read_csv('german-traffic-signs/signnames.csv')
print(len(signnames))
print(type(train_data))
print(train_data.keys()
43
<class 'dict'>
dict_keys(['coords', 'labels', 'features', 'sizes'])
可以看到共有43个类别的交通标志,pickle文件反序列化后是dict对象,该对象有4个属性,对于我们的任务,只需要用到labels和features,分别为图片的分类id和图片本身。
我们看看数据集的大小:
X_train, y_train = train_data['features'], train_data['labels']
X_val, y_val = val_data['features'], val_data['labels']
X_test, y_test = test_data['features'], test_data['labels']
print('Training data:', X_train.shape)
print('Validation data:', X_val.shape)
print('Test data:', X_test.shape)
训练数据有34799个,验证数据有4410个,测试数据有12630个;图片的大小为32 x 32,有3个颜色channel:
Training data: (34799, 32, 32, 3)
Validation data: (4410, 32, 32, 3)
Test data: (12630, 32, 32, 3)
接着,我们随机显示每个类别的5张图片和对应的标签看看。
import matplotlib.pyplot as plt
import random
%matplotlib inline
num_of_samples = []
cols = 5
num_classes = 43
fig, axs = plt.subplots(nrows=num_classes, ncols=cols, figsize=(5, 50))
fig.tight_layout()
for i in range(cols):
for j, row in signnames.iterrows():
x_selected = X_train[y_train == j]
axs[j][i].imshow(x_selected[random.randint(0, (len(x_selected) - 1)), :, :], cmap=plt.get_cmap('gray'))
axs[j][i].axis("off")
if i == 2:
axs[j][i].set_title(str(j) + " - " + row["SignName"])
num_of_samples.append(len(x_selected))

图片的差异比较大:明暗不一、背景不一等等。
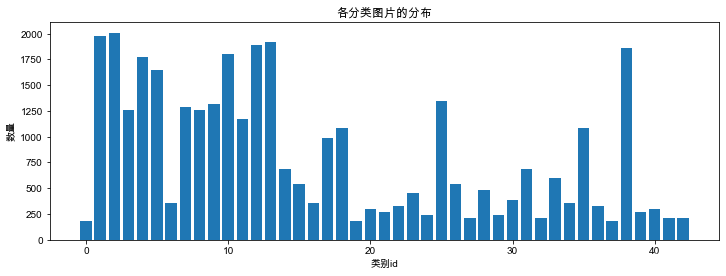
接下来看一下每个类别的图片的数量:
print(num_of_samples)
plt.figure(figsize=(12, 4))
plt.bar(range(0, num_classes), num_of_samples)
plt.title("各分类图片的分布")
plt.xlabel("类别id")
plt.ylabel("数量")
plt.show()
情况有点不太妙,有的类别只有不到200张图片,有的类别却有超过2000张图片,imbalanced dataset会对分类任务带来影响:
[180, 1980, 2010, 1260, 1770, 1650, 360, 1290, 1260, 1320, 1800, 1170, 1890, 1920, 690, 540, 360, 990, 1080, 180, 300, 270, 330, 450, 240, 1350, 540, 210, 480, 240, 390, 690, 210, 599, 360, 1080, 330, 180, 1860, 270, 300, 210, 210]
3 使用LeNet进行分类
我们先不对图片进行处理,先使用最简单的CNN网络对交通标志进行分类,在此基准上再进行各种优化来实现最终98%的准确率。
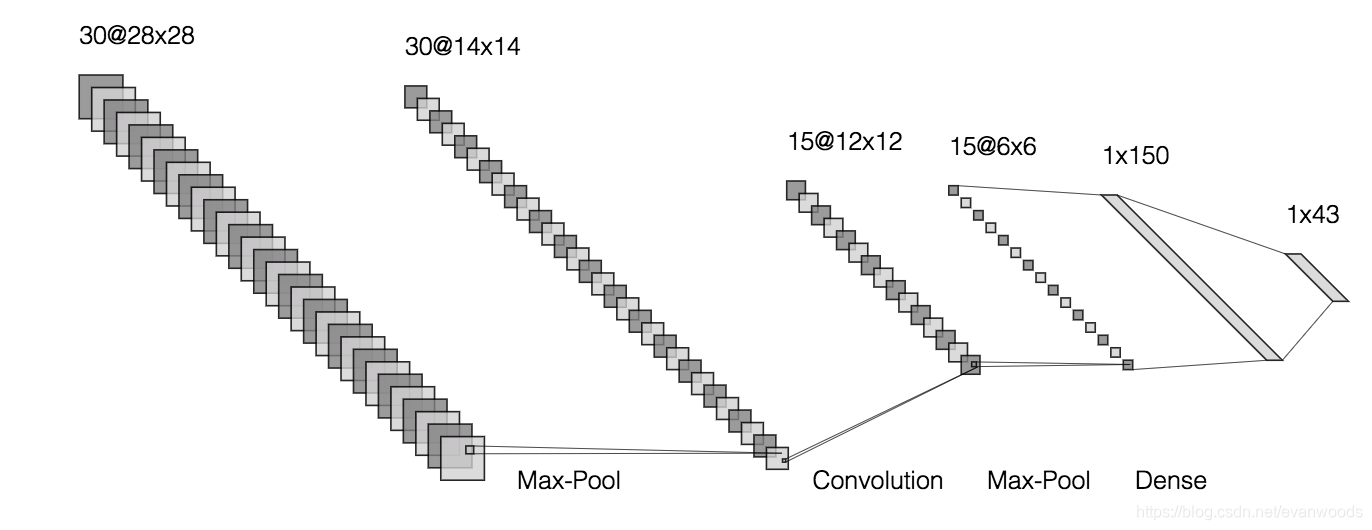
3.1 模型定义
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Dropout, Flatten
from tensorflow.keras.optimizers import Adam
def leNet_model():
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(32, 32, 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(150, activation='relu'))
model.add(Dense(43, activation='softmax'))
model.compile(Adam(lr=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
return model
model = leNet_model()
print(model.summary())
模型有两层CNN加MaxPooling,Flatten后经过一层Dense和一层softmax后得出43个分类每个分类的概率;优化器使用Adam,learning rate暂设为0.001。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 28, 28, 30) 2280
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 14, 14, 30) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 12, 12, 15) 4065
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 15) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 540) 0
_________________________________________________________________
dense_2 (Dense) (None, 150) 81150
_________________________________________________________________
dense_3 (Dense) (None, 43) 6493
=================================================================
Total params: 93,988
Trainable params: 93,988
Non-trainable params: 0
_________________________________________________________________
None
3.2 模型训练
首先,把43个分类做one hot处理:
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train, 43)
y_test = to_categorical(y_test, 43)
y_val = to_categorical(y_val, 43)
接着开始训练,使用20个epoch、每个batch为400个样本`:
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_val, y_val), batch_size=400, verbose=1, shuffle=True)
Train on 34799 samples, validate on 4410 samples
Epoch 1/20
34799/34799 [==============================] - 2s 52us/sample - loss: 5.3459 - accuracy: 0.2106 - val_loss: 2.3427 - val_accuracy: 0.4367
Epoch 2/20
34799/34799 [==============================] - 1s 40us/sample - loss: 1.1822 - accuracy: 0.6883 - val_loss: 1.2369 - val_accuracy: 0.6941
Epoch 3/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.5687 - accuracy: 0.8515 - val_loss: 0.9957 - val_accuracy: 0.7728
Epoch 4/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.3659 - accuracy: 0.9042 - val_loss: 1.0038 - val_accuracy: 0.7932
Epoch 5/20
...
Epoch 15/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.0461 - accuracy: 0.9879 - val_loss: 1.0673 - val_accuracy: 0.8642
Epoch 16/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.0499 - accuracy: 0.9859 - val_loss: 1.0070 - val_accuracy: 0.8667
Epoch 17/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.0564 - accuracy: 0.9843 - val_loss: 1.0201 - val_accuracy: 0.8610
Epoch 18/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.0399 - accuracy: 0.9887 - val_loss: 1.0586 - val_accuracy: 0.8678
Epoch 19/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.0346 - accuracy: 0.9905 - val_loss: 1.0694 - val_accuracy: 0.8773
Epoch 20/20
34799/34799 [==============================] - 1s 40us/sample - loss: 0.0379 - accuracy: 0.9895 - val_loss: 1.1620 - val_accuracy: 0.8710
def evaluate():
score = model.evaluate(X_test, y_test, verbose=0)
print('Test score:', score[0])
print('Test Accuracy:', score[1])
evaluate()
Test score: 1.5260828396982364
Test Accuracy: 0.8539984
结果出来了,可以看到在训练集上的准确率达到了98.9%,但在验证集上的准确率只有87.1%,存在严重的过拟合(overfitting),在测试集上的成绩 – 准确率只有85.3%。我们再看看loss和accuracy的变化曲线:
def plot_history(history):
fig, axs = plt.subplots(1, 2, figsize=(20, 8))
axs[0].plot(history.history['loss'])
axs[0].plot(history.history['val_loss'])
axs[0].legend(['Training', 'Validation'])
axs[0].set_title('Loss')
axs[0].set_xlabel('epoch')
axs[1].plot(history.history['accuracy'])
axs[1].plot(history.history['val_accuracy'])
axs[1].legend(['Training', 'Validation'])
axs[1].set_title('Accuracy')
axs[1].set_xlabel('epoch')
plot_history(history)
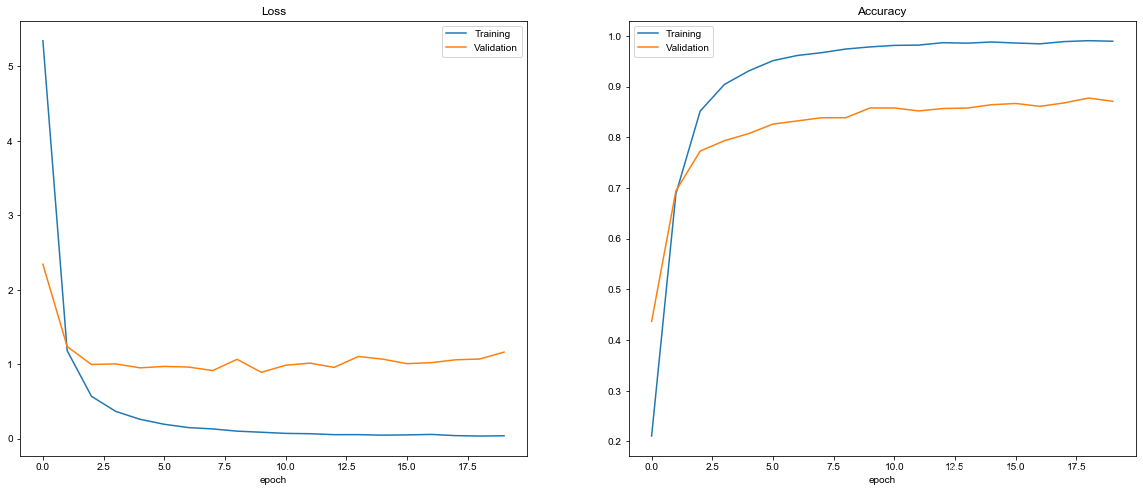
验证曲线距离训练曲线还很远。
4 优化
接下来我们开始针对性的优化。
4.1 Dropout
针对过拟合,最简单的模型优化方式就是使用Dropout了,我们添加两个Dropout层看看:
def modified_model():
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(32, 32, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(150, activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(43, activation='softmax'))
model.compile(Adam(lr=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
return model
model = modified_model()
print(model.summary())
Model: "sequential_12"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_48 (Conv2D) (None, 28, 28, 30) 2280
_________________________________________________________________
max_pooling2d_48 (MaxPooling (None, 14, 14, 30) 0
_________________________________________________________________
conv2d_49 (Conv2D) (None, 12, 12, 15) 4065
_________________________________________________________________
max_pooling2d_49 (MaxPooling (None, 6, 6, 15) 0
_________________________________________________________________
dropout_18 (Dropout) (None, 6, 6, 15) 0
_________________________________________________________________
flatten_24 (Flatten) (None, 540) 0
_________________________________________________________________
dense_48 (Dense) (None, 150) 81150
_________________________________________________________________
dropout_19 (Dropout) (None, 150) 0
_________________________________________________________________
dense_49 (Dense) (None, 43) 6493
=================================================================
Total params: 93,988
Trainable params: 93,988
Non-trainable params: 0
_________________________________________________________________
None
可以看到参数数量是没有变化的。
我们开始训练了,可能你会遇到跟我一样的意外(只是有可能):
model = modified_model()
history = model.fit(X_train, y_train, epochs=60, validation_data=(X_val, y_val), batch_size=400, verbose=1, shuffle=True)
Train on 34799 samples, validate on 4410 samples
Epoch 1/60
34799/34799 [==============================] - 2s 55us/sample - loss: 7.6550 - accuracy: 0.0534 - val_loss: 3.7177 - val_accuracy: 0.0544
Epoch 2/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.6863 - accuracy: 0.0563 - val_loss: 3.6767 - val_accuracy: 0.0544
Epoch 3/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.6388 - accuracy: 0.0558 - val_loss: 3.6372 - val_accuracy: 0.0544
Epoch 4/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.5953 - accuracy: 0.0557 - val_loss: 3.6030 - val_accuracy: 0.054
...
Epoch 16/60
34799/34799 [==============================] - 1s 40us/sample - loss: 3.4896 - accuracy: 0.0549 - val_loss: 3.5506 - val_accuracy: 0.0544
Epoch 17/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.4873 - accuracy: 0.0558 - val_loss: 3.5507 - val_accuracy: 0.0544
Epoch 18/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.4866 - accuracy: 0.0565 - val_loss: 3.5510 - val_accuracy: 0.0544
Epoch 19/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.4847 - accuracy: 0.0567 - val_loss: 3.5511 - val_accuracy: 0.0544
Epoch 20/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.4844 - accuracy: 0.0541 - val_loss: 3.5512 - val_accuracy: 0.0544
...
Epoch 56/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.4770 - accuracy: 0.0578 - val_loss: 3.5547 - val_accuracy: 0.0544
Epoch 57/60
34799/34799 [==============================] - 1s 40us/sample - loss: 3.4770 - accuracy: 0.0578 - val_loss: 3.5548 - val_accuracy: 0.0544
Epoch 58/60
34799/34799 [==============================] - 1s 40us/sample - loss: 3.4770 - accuracy: 0.0578 - val_loss: 3.5547 - val_accuracy: 0.0544
Epoch 59/60
34799/34799 [==============================] - 1s 41us/sample - loss: 3.4770 - accuracy: 0.0578 - val_loss: 3.5546 - val_accuracy: 0.0544
Epoch 60/60
34799/34799 [==============================] - 1s 40us/sample - loss: 3.4770 - accuracy: 0.0578 - val_loss: 3.5547 - val_accuracy: 0.0544

训练了60个epoch后, loss并没有什么变化!这是怎么回事呢?
4.1.1 死亡的ReLU
聪明如你可能已经知道了,原因在于我们的激活函数(activation function) – ReLU在值小于0的时候是0,梯度(gradient)也是0,这个时候就不能有效训练网络了。我们可以使用eLU或Leaky ReLU来替代它。

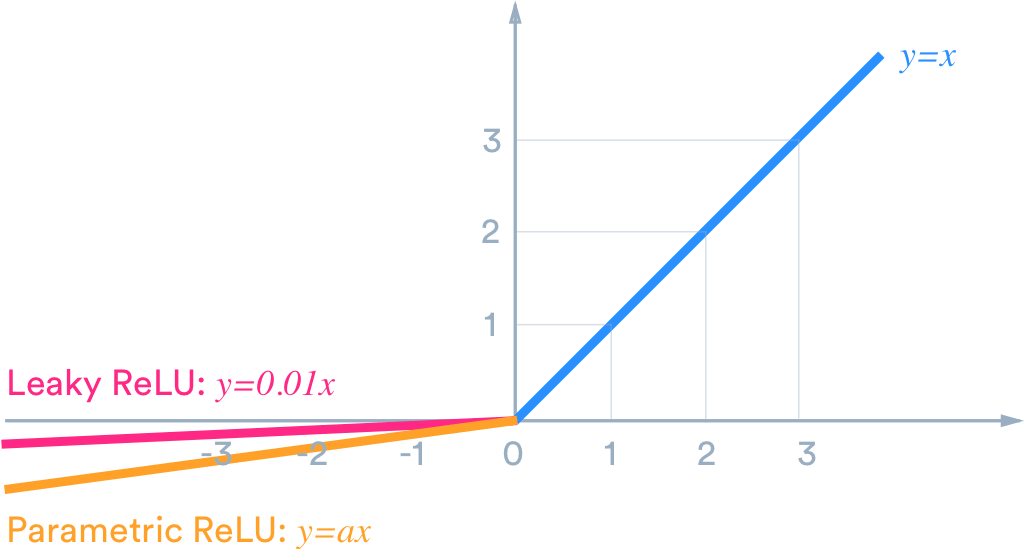
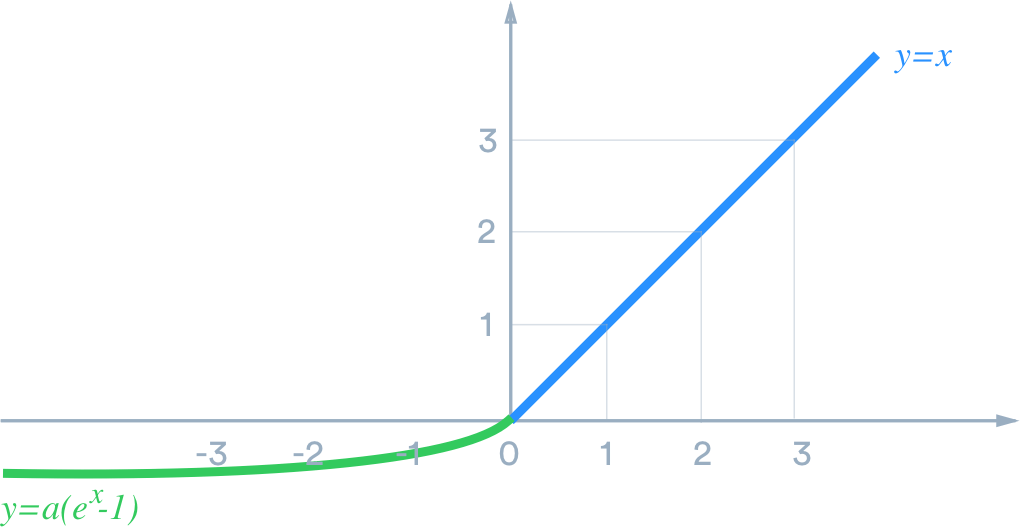
这里选择eLU,eLU应该也能更快的converge,注意我把第2个Dropout的比例调成0.5,把learning rate减少一半,并增加训练次数到100个epoch:
def modified_model():
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(32, 32, 3), activation='elu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='elu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(150, activation='elu'))
model.add(Dropout(0.5))
model.add(Dense(43, activation='softmax'))
model.compile(Adam(lr=0.0005), loss='categorical_crossentropy', metrics=['accuracy'])
return model
model = modified_model()
history = model.fit(X_train, y_train, epochs=100, validation_data=(X_val, y_val), batch_size=400, verbose=1, shuffle=True)
Train on 34799 samples, validate on 4410 samples
Epoch 1/100
34799/34799 [==============================] - 2s 56us/sample - loss: 12.5261 - accuracy: 0.0355 - val_loss: 3.5446 - val_accuracy: 0.0655
Epoch 2/100
34799/34799 [==============================] - 1s 41us/sample - loss: 4.0887 - accuracy: 0.0599 - val_loss: 3.3880 - val_accuracy: 0.1345
Epoch 3/100
34799/34799 [==============================] - 1s 41us/sample - loss: 3.7705 - accuracy: 0.1050 - val_loss: 2.9809 - val_accuracy: 0.2524
Epoch 4/100
34799/34799 [==============================] - 1s 42us/sample - loss: 3.3804 - accuracy: 0.1718 - val_loss: 2.5046 - val_accuracy: 0.3574
Epoch 5/100
34799/34799 [==============================] - 1s 42us/sample - loss: 2.9944 - accuracy: 0.2417 - val_loss: 2.1266 - val_accuracy: 0.4383
...
Epoch 96/100
34799/34799 [==============================] - 1s 42us/sample - loss: 0.1113 - accuracy: 0.9660 - val_loss: 0.1910 - val_accuracy: 0.9535
Epoch 97/100
34799/34799 [==============================] - 2s 43us/sample - loss: 0.1144 - accuracy: 0.9645 - val_loss: 0.1795 - val_accuracy: 0.9571
Epoch 98/100
34799/34799 [==============================] - 1s 41us/sample - loss: 0.1140 - accuracy: 0.9643 - val_loss: 0.1817 - val_accuracy: 0.9560
Epoch 99/100
34799/34799 [==============================] - 1s 41us/sample - loss: 0.1120 - accuracy: 0.9661 - val_loss: 0.1751 - val_accuracy: 0.9546
Epoch 100/100
34799/34799 [==============================] - 1s 41us/sample - loss: 0.1102 - accuracy: 0.9652 - val_loss: 0.1683 - val_accuracy: 0.9578
Amazing! 仅仅加了Dropout和微调了一下参数,我们训练的准确率达到了95.7%,测试集上准确率达到了 96.3%(85.3% -> 96.3%) :
plot_history(history)

evaluate()
Test score: 0.14850520864866457
Test Accuracy: 0.9631037
我们离目标98%不远啦!
4.2 图片增强(Image Augmentation)
由于训练集里某些类别的交通标志样本过少,同时为了增加训练样本的多样性,使网络学习到更稳定、更本质的特征,我们对训练图片做一些常见的增强,使用ImageDataGenerator即可。
我们将应用5种变换:
- width_shift: 水平方向移动,幅度10%
- height_shift: 垂直方向移动,幅度10%
- zoom: 放大与缩小,幅度20%
- shear: 平行四边形变换,可沿水平或者垂直方向变换,幅度为与坐标轴夹角0.1度
- rotation: 顺时针或逆时针旋转,幅度10度
from tensorflow.keras.preprocessing.image import ImageDataGenerator
X_train = X_train/255
X_val = X_val/255
X_test = X_test/255
datagen = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.2,
shear_range=0.1,
rotation_range=10.)
datagen.fit(X_train)
随便抽几张图片来看看:
batches = datagen.flow(X_train, y_train, batch_size=10)
X_batch, y_batch = next(batches)
fig, axs = plt.subplots(1, 10, figsize=(15, 5))
fig.tight_layout()
for i in range(10):
axs[i].imshow(X_batch[i])
axs[i].axis("off")
可以看到图片确实有一些改变,有的图片可能应用了不止1个变换:

接着开始训练:
model = modified_model()
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=50),
steps_per_epoch=len(X_train)/50,
epochs=100,
validation_data=(X_val, y_val), shuffle=True)
Train for 695.98 steps, validate on 4410 samples
Epoch 1/100
696/695 [==============================] - 19s 27ms/step - loss: 2.7106 - accuracy: 0.2586 - val_loss: 1.7745 - val_accuracy: 0.4687
Epoch 2/100
696/695 [==============================] - 18s 26ms/step - loss: 1.8986 - accuracy: 0.4307 - val_loss: 1.3028 - val_accuracy: 0.5889
Epoch 3/100
696/695 [==============================] - 19s 27ms/step - loss: 1.5969 - accuracy: 0.5062 - val_loss: 1.1169 - val_accuracy: 0.6503
Epoch 4/100
696/695 [==============================] - 19s 27ms/step - loss: 1.4203 - accuracy: 0.5563 - val_loss: 0.9490 - val_accuracy: 0.6930
Epoch 5/100
696/695 [==============================] - 19s 27ms/step - loss: 1.2934 - accuracy: 0.5892 - val_loss: 0.8621 - val_accuracy: 0.7327
...
Epoch 96/100
696/695 [==============================] - 18s 25ms/step - loss: 0.4447 - accuracy: 0.8595 - val_loss: 0.2044 - val_accuracy: 0.9406
Epoch 97/100
696/695 [==============================] - 17s 25ms/step - loss: 0.4433 - accuracy: 0.8602 - val_loss: 0.1746 - val_accuracy: 0.9476
Epoch 98/100
696/695 [==============================] - 18s 25ms/step - loss: 0.4392 - accuracy: 0.8612 - val_loss: 0.1928 - val_accuracy: 0.9433
Epoch 99/100
696/695 [==============================] - 18s 26ms/step - loss: 0.4249 - accuracy: 0.8644 - val_loss: 0.2079 - val_accuracy: 0.9370
Epoch 100/100
696/695 [==============================] - 18s 26ms/step - loss: 0.4259 - accuracy: 0.8650 - val_loss: 0.2012 - val_accuracy: 0.9454
可以看到图片增强后准确率并没有提升,在测试集上的准确率甚至下降了,为 93.6%(96.3% -> 93.6%):
evaluate()
Test score: 0.2087915445615258
Test Accuracy: 0.93634206

4.3 模型优化
万事开头难,然后中间难,最后最难。
首先,我们看到虽然应用了数据增强,但模型在训练集上的准确率是比较低的,只能达到86.5%,这说明模型可能有一点点欠拟合(underfitting)。因为我们的模型是最简单的LeNet结构,我们需要增加一些层次来抽取更复杂的特征。
说干就干:
def modified_model():
model = Sequential()
model.add(Conv2D(60, (5, 5), input_shape=(32, 32, 3), activation='elu'))
model.add(Conv2D(60, (5, 5), activation='elu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(30, (3, 3), activation='elu'))
model.add(Conv2D(30, (3, 3), activation='elu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(30, (3, 3), activation='elu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(500, activation='elu'))
model.add(Dropout(0.5))
model.add(Dense(43, activation='softmax'))
model.compile(Adam(lr=0.0005), loss='categorical_crossentropy', metrics=['accuracy'])
return model
m = modified_model()
print(m.summary())
Model: "sequential_62"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_161 (Conv2D) (None, 28, 28, 60) 4560
_________________________________________________________________
conv2d_162 (Conv2D) (None, 24, 24, 60) 90060
_________________________________________________________________
max_pooling2d_135 (MaxPoolin (None, 12, 12, 60) 0
_________________________________________________________________
conv2d_163 (Conv2D) (None, 10, 10, 30) 16230
_________________________________________________________________
conv2d_164 (Conv2D) (None, 8, 8, 30) 8130
_________________________________________________________________
max_pooling2d_136 (MaxPoolin (None, 4, 4, 30) 0
_________________________________________________________________
dropout_93 (Dropout) (None, 4, 4, 30) 0
_________________________________________________________________
conv2d_165 (Conv2D) (None, 2, 2, 30) 8130
_________________________________________________________________
max_pooling2d_137 (MaxPoolin (None, 1, 1, 30) 0
_________________________________________________________________
flatten_61 (Flatten) (None, 30) 0
_________________________________________________________________
dense_122 (Dense) (None, 500) 15500
_________________________________________________________________
dropout_94 (Dropout) (None, 500) 0
_________________________________________________________________
dense_123 (Dense) (None, 43) 21543
=================================================================
Total params: 164,153
Trainable params: 164,153
Non-trainable params: 0
_________________________________________________________________
None
加进了更多的CNN层,使用更多filter,Dense层的output也增加了,现在模型参数的数量从9万多增加到16万多了。
结果如何呢?且看:
model = modified_model()
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=50),
steps_per_epoch=len(X_train)/50,
epochs=200,
validation_data=(X_val, y_val), shuffle=True)
...
Epoch 196/200
696/695 [==============================] - 23s 33ms/step - loss: 0.8824 - accuracy: 0.7515 - val_loss: 0.0213 - val_accuracy: 0.9930
Epoch 197/200
696/695 [==============================] - 23s 33ms/step - loss: 0.8927 - accuracy: 0.7484 - val_loss: 0.0238 - val_accuracy: 0.9925
Epoch 198/200
696/695 [==============================] - 23s 33ms/step - loss: 0.8791 - accuracy: 0.7518 - val_loss: 0.0273 - val_accuracy: 0.9932
Epoch 199/200
696/695 [==============================] - 23s 33ms/step - loss: 0.8877 - accuracy: 0.7492 - val_loss: 0.0267 - val_accuracy: 0.9923
Epoch 200/200
696/695 [==============================] - 23s 33ms/step - loss: 0.9068 - accuracy: 0.7463 - val_loss: 0.0304 - val_accuracy: 0.9907
经过200轮训练,准确率终于有所上升了,为 97.6%!(93.6% -> 97.6%)
evaluate()
Test score: 0.09128276077196848
Test Accuracy: 0.9766429
plot_history(history)
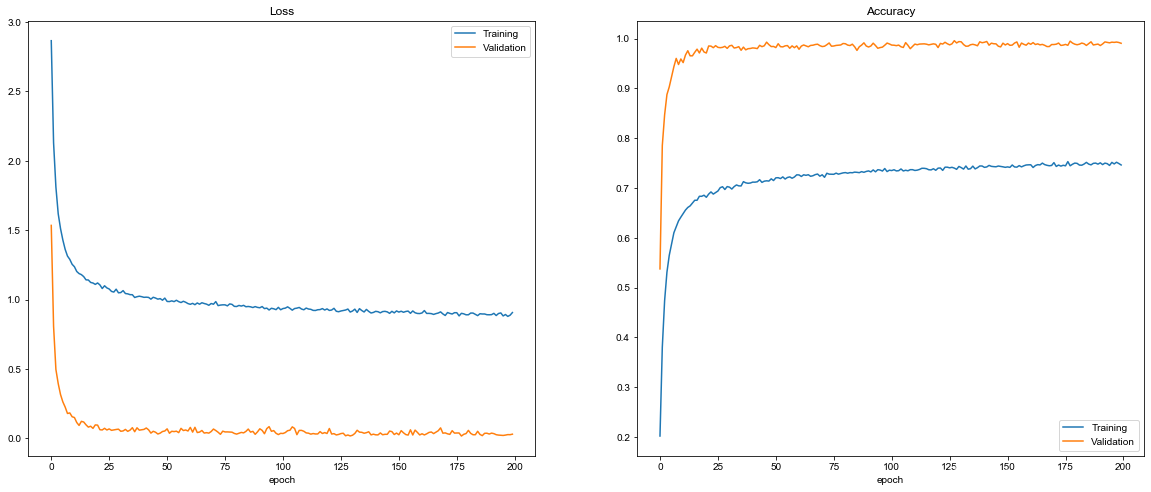
5 再优化
虽然97.6%的准确率四舍五入可以认为已经达到98%了,但总感觉差点意思。毕竟还没看到0.98这几个数字呢。
5.1 分类错误的图片
我们先看看那分类错误的2.4%的图片是什么样的:
y_predicted = model.predict_classes(X_test)
y_test_classes = test_data['labels']
uncorrect = test_data['features'][y_test_classes != y_predicted]
print(uncorrect.shape)
(295, 32, 32, 3)
有295个是识别错误的。随便看10个吧:
import random
fig, axs = plt.subplots(1, 10, figsize=(15, 5))
fig.tight_layout()
for i in range(10):
axs[i].imshow(uncorrect[random.randint(0, len(uncorrect) - 1)])
axs[i].axis("off")

这些图片比我想象中的更难识别,有更多的变形,有的图片有噪音(第2与第4张),有的图片有部分被遮挡(第8张),最后一张似乎快变成黑白的了。
5.2 图片再增强
根据以上信息,我们可以继续尝试对训练图片增加噪音、遮挡和改变色调等增强处理。
这里用到功能强大的图片处理库imgaug,使用其中的2个增强器:
- Cutout: 随机切掉图片的一些部分,我们切掉2小方块
- AddToHueAndSaturation: 改变色调和饱和度,我们设定范围为(-50, 50)
以下代码先调整了一下ImageDataGenerator的参数,幅度更大些;然后创建两个图片增强器;为了和ImageDataGenerator搭配使用,我定义了一个自己的generator,在ImageDataGenerator产生的batch里挑50%的图片做cutout,再挑50%做改变色调饱和度:
import imgaug as ia
from imgaug import augmenters as iaa
import numpy as np
datagen = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.2,
shear_range=10,
rotation_range=30.)
datagen.fit(X_train)
cutout = iaa.Cutout(nb_iterations=2)
change_hue_sat = iaa.AddToHueAndSaturation((-50, 50))
def my_generator():
batches = datagen.flow(X_train, y_train, batch_size=50)
while True:
X_batch, y_batch = next(batches)
for i in range(len(X_batch)):
if np.random.rand() < 0.5:
X_batch[i] = X_batch[i] * 255
X_batch[i] = cutout(image=X_batch[i].astype(np.uint8)) / 255
if np.random.rand() < 0.5:
X_batch[i] = X_batch[i] * 255
X_batch[i] = change_hue_sat(image=X_batch[i].astype(np.uint8)) / 255
yield (X_batch, y_batch)
5.3 最后的训练
model = modified_model()
history = model.fit_generator(my_generator(),
steps_per_epoch=len(X_train)/50,
epochs=200,
validation_data=(X_val, y_val), shuffle=True)
由于处理的步骤多了,训练的时间也长了很多。
Train for 695.98 steps, validate on 4410 samples
Epoch 1/200
696/695 [==============================] - 43s 62ms/step - loss: 2.5890 - accuracy: 0.2612 - val_loss: 1.3441 - val_accuracy: 0.5361
Epoch 2/200
696/695 [==============================] - 42s 61ms/step - loss: 1.6096 - accuracy: 0.4966 - val_loss: 0.7641 - val_accuracy: 0.7676
...
Epoch 196/200
696/695 [==============================] - 40s 57ms/step - loss: 0.1651 - accuracy: 0.9504 - val_loss: 0.0467 - val_accuracy: 0.9859
Epoch 197/200
696/695 [==============================] - 40s 58ms/step - loss: 0.1596 - accuracy: 0.9518 - val_loss: 0.0530 - val_accuracy: 0.9848
Epoch 198/200
696/695 [==============================] - 40s 57ms/step - loss: 0.1722 - accuracy: 0.9485 - val_loss: 0.0338 - val_accuracy: 0.9893
Epoch 199/200
696/695 [==============================] - 40s 57ms/step - loss: 0.1689 - accuracy: 0.9491 - val_loss: 0.0197 - val_accuracy: 0.9943
Epoch 200/200
696/695 [==============================] - 40s 57ms/step - loss: 0.1706 - accuracy: 0.9493 - val_loss: 0.0216 - val_accuracy: 0.9939
最终在训练集和验证集上都达到了比较高的准确率。
plot_history(history)
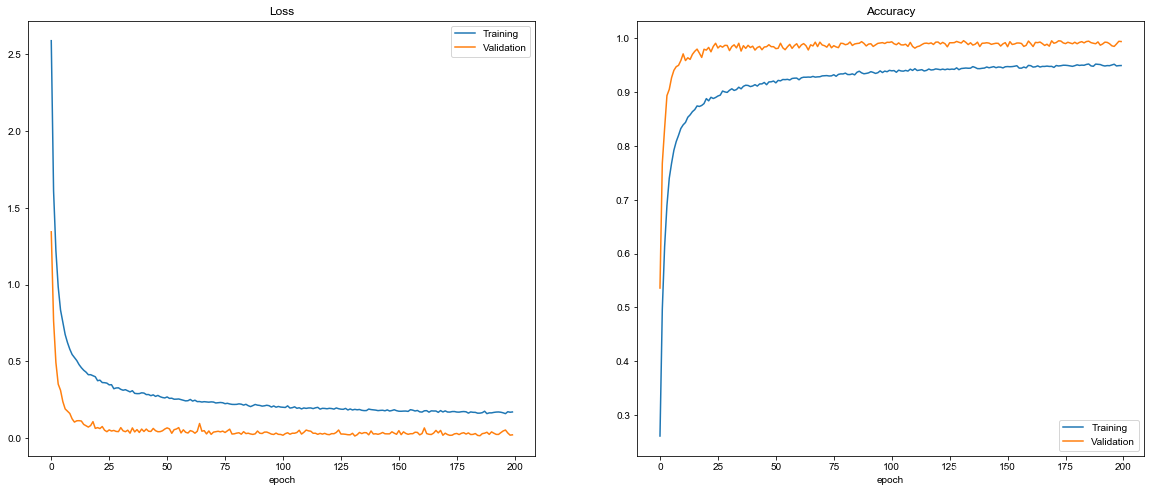
那么在测试集上是否达到目标了呢?
evaluate()
Test score: 0.0694863362028404
Test Accuracy: 0.9830562
是的,98.3%! (97.6% -> 98.3%),超过98% 。功夫不负有心人呐!
6 思考
在图片处理环节,我并没有把图片转成灰度,虽然认为交通标志的形状才是最重要的,但我觉得其颜色也是标准的,应该也是识别的线索。
欢迎读者朋友对灰度图片进行试验,看能否达到98%的准确率,期待你的好消息!
对图片的处理还有很多的方法,本文只是抛砖引玉,欢迎尝试更多更好的方法来得到更高的准确率,也欢迎提出问题一起讨论学习,谢谢!
