Kafka之KSQL简单安装操作
1.KSQL官网地址
2. KSQL安装步骤
2.1 下载地址
下载地址 confluent-oss-5.0.0-2.11.tar.gz
2.2 安装步骤
a. 解压
# tar -zxvf confluent-oss-5.0.0-2.11.tar.gz
b. 启动kafka
# ./bin/confluent start
c. 启动ksql客户端
# ./bin/ksql

3.操作说明
a. 创建流:
CREATE STREAM twitter_raw (
Created_At VARCHAR,
Id BIGINT,
Text VARCHAR,
Source VARCHAR,
Truncated VARCHAR,
User VARCHAR,
Retweet VARCHAR,
Contributors VARCHAR)
WITH (
kafka_topic='rm.oow',
value_format='JSON'
);
注:value_format 有两种格式 JSON(json格式) 和 DELIMITED(原生格式)
b. 在流的基础上创建流
create stream twitter_fixed as
select STRINGTOTIMESTAMP(Created_At, 'EEE MMM dd HH:mm:ss ZZZZZ yyyy') AS Created_At,
Id,
Text,
Source,
EXTRACTJSONFIELD(User, '$.name') as User_name,
EXTRACTJSONFIELD(User, '$.screen_name') as User_screen_name,
EXTRACTJSONFIELD(User, '$.id') as User_id,
EXTRACTJSONFIELD(User, '$.location') as User_location,
EXTRACTJSONFIELD(User, '$.description') as description
from twitter_raw
注:EXTRACTJSONFIELD 经过实践,并不能从json数据中解析出第二层数据字段
c. 在流的基础上创建table
create table tweets_by_users as
select user_screen_name, count(Id) nr_of_tweets
from twitter_with_key_and_timestamp group by user_screen_name
d. 查询所有的stream
# show streams;
e. 查询strream的详细信息
# describe [stream_name]
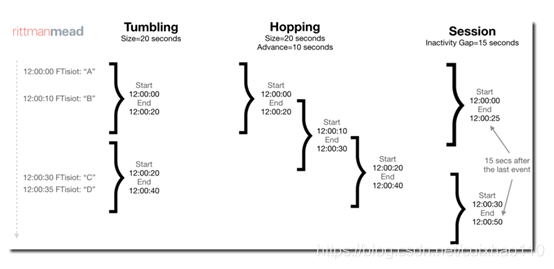
f. Stream 窗口
Tumbling 、Hopping、Session
关系图如下:
创建语法:
TUMBLING:
create table rm.tweets_by_location
as
select user_location,
count(Id) nr_of_tweets
from twitter_with_key_and_timestamp
WINDOW TUMBLING (SIZE 30 SECONDS)
group by user_location
HOPPING:
create table rm.tweets_by_location_hopping
as
select user_location,
count(Id) nr_of_tweets
from twitter_with_key_and_timestamp
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS)
group by user_location;
g. Ksql所创建的stream , table数据没有在kafka中存储。
