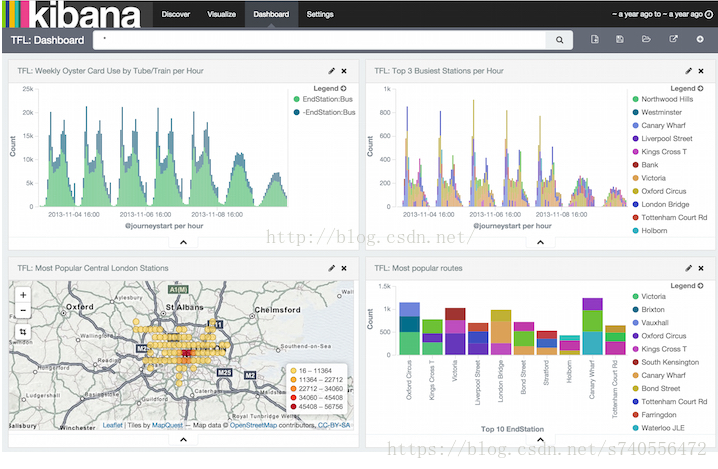
前言
大概是节前到节后的小2个月时间,已经把实时日志分析这一套小架子搭了起来,并且已经可以看到成果,现在继续利用业余时间把这个系列总结记录一下。
逻辑架构图
逻辑架构图如下:
一图胜过千言万语,来看下实时日志分析的技术选型以及整个流程。
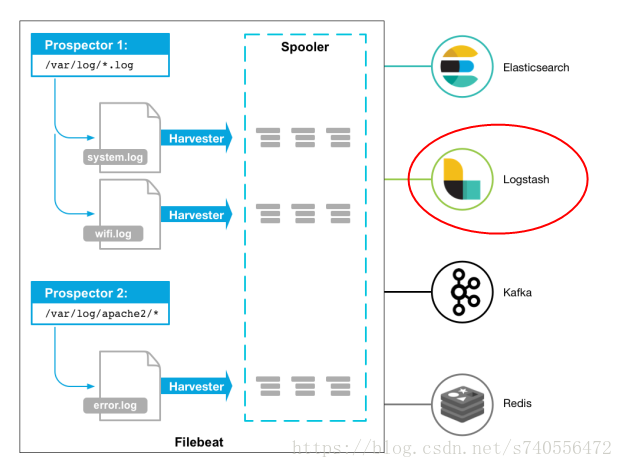
其实这一套大部分都是组件,而整套组件中用到的都是Elastic Stack中的组件。首先采用了filebeat ( elastic stack的组件) 对采集日志服务器进行日志采集,通过主动发的形式送入logstash (elastic stack的组件)中,在logstash中对日志的每行信息进行正则匹配,并且对应格式化成json串的形式。而logstash自带的output插件中是支持kafka的,在用其发向kafka集群。storm这里是需要写代码的,我们需要手动写一个拓扑(topology),而这个拓扑中的spout节点便是从kafka上读取数据,同时用java的普通类对数据进行处理,在用bolt写上连接elasticsearch客户端的逻辑代码,发向elasticsearch,最终通过kibana连接到elasticsearch上,对数据进行相应的数据分析以及界面展示。
技术选型介绍
Filebeat
Filebeat: 是一个日志文件托运工具,在服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读)。而相对于logstash,filebeat的优点是非常轻量级….并且不吃内存。
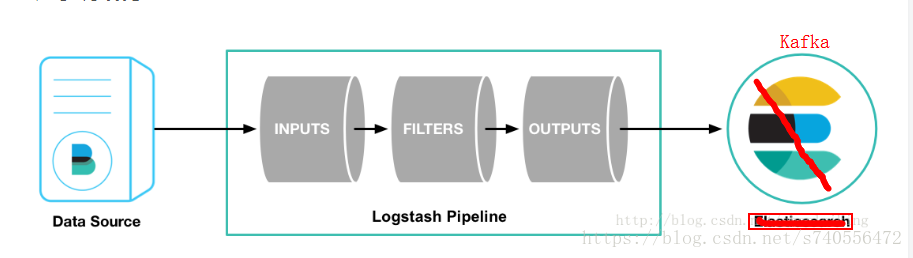
Logstash
是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
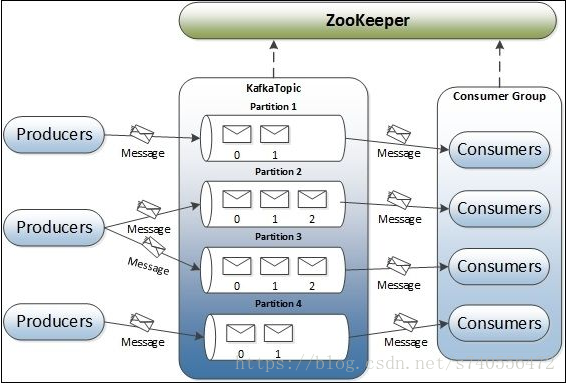
Apache Kafka
是一个快速、可扩展的、高吞吐、可容错的分布式发布订阅消息系统。Kafka具有高吞吐量、内置分区、支持数据副本和容错的特性,在离线和实时的消息处理业务系统中,Kafka都有广泛的应用。Kafka将消息持久化到磁盘中,并对消息创建了备份保证了数据的安全。Kafka在保证了较高的处理速度的同时,又能保证数据处理的低延迟和数据的零丢失。
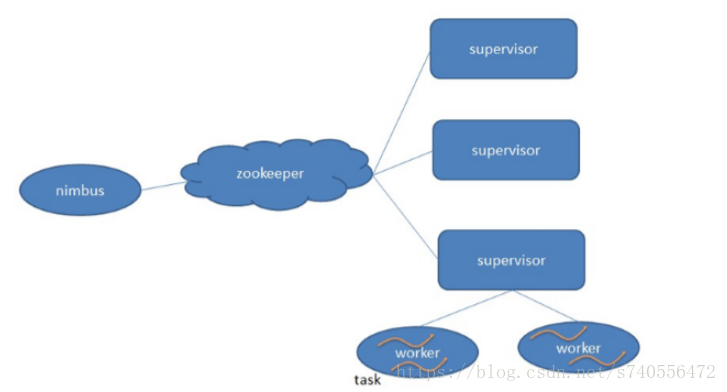
Storm
是一个分布式的,可靠的,容错的数据流处理系统。Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到某种存储器,要么把数据传递给其它的bolt。一个Storm集群就是在一连串的bolt之间转换spout传过来的数据。
Elasticsearch
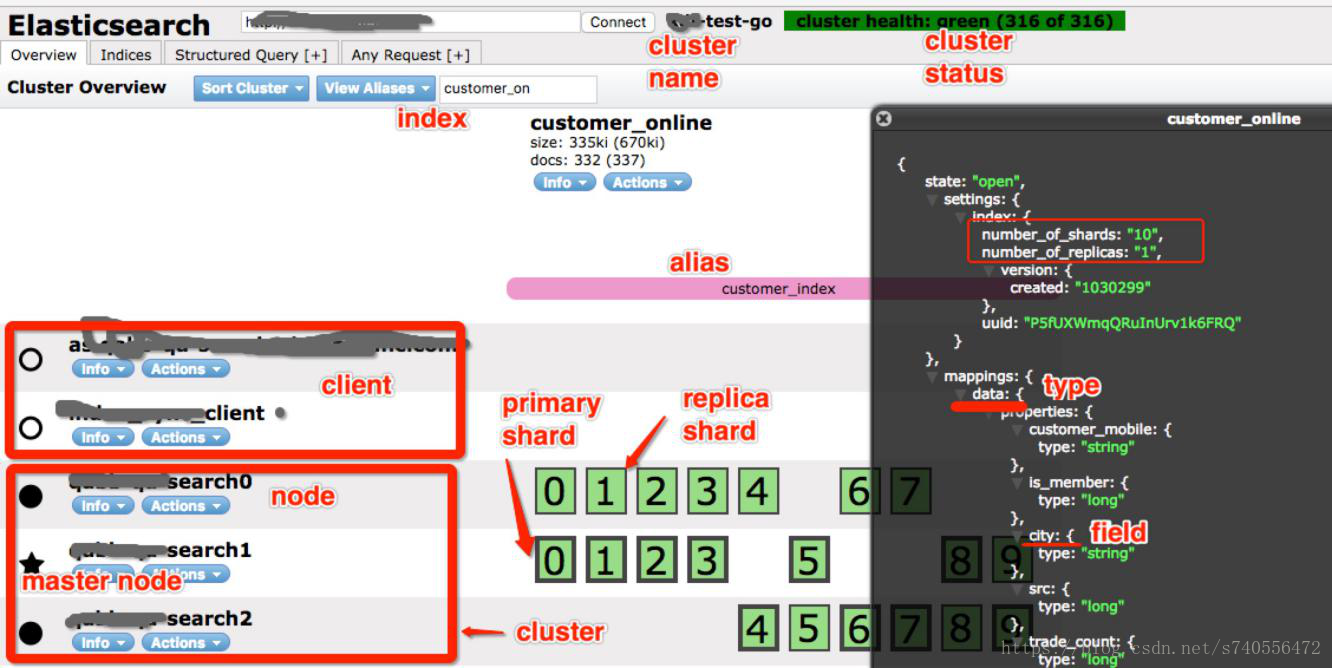
是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一,Wikipedia、Stack Overflow、GitHub 等都基于 Elasticsearch 来构建他们的搜索引擎。
下图是es的node插件的图:
Kibana
是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。