什么是决策树?
决策树是一种逻辑简单的机器学习算法,可用作分类,也可用作回归,属于监督学习(Supervised learning)。
决策树的模型表达式f(x)很难被写出,却很容易被画出
决策树是一种树形结构:
树形结构:
①结点+有向边
②没有回路,根结点为始、叶子结点为终
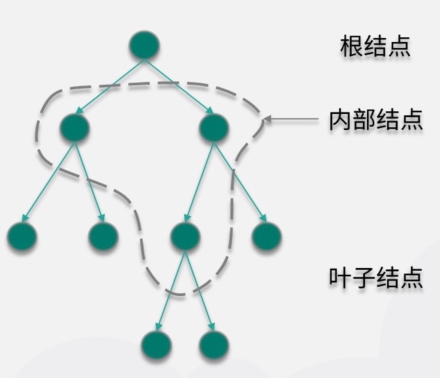
或者这么画:
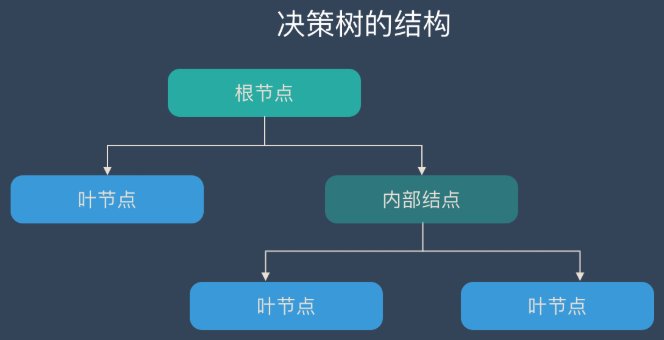
根节点:包含样本的全集
内部节点:对应特征属性测试
叶节点:代表决策的结果
决策树学习的步骤:
-
特征选择
根据信息增益的准则,筛选出跟分类结果相关性较高的特征,也就是分类能力较强的特征。 -
决策树生成及分裂
从根节点开始,对每个节点计算所有特征的信息增益,选择信息增益最大的特征作为节点特征,根据该特征的不同取值建立子节点;然后对每个子节点使用相同的方式生成新的子节点,直到信息增益很小或者没有特征可以选择为止。 -
决策树剪枝
主动去掉部分分支,防止过拟合。
决策树的分裂(决策):

根据 分裂的特征x 和 分裂的阈值a 进行分裂,即进行一次决策。然后由判断结果决定进入哪个分支节点,直至到达叶节点处,得到分类结果。
在构建决策树模型时,我们无法得知参数数量,而是采用启发式算法。
启发式算法:
- 将所有的训练数据都放在根结点中。
- 选择一个当前的最优决策,将根结点的数据分割成子集。
- 对每个子集,选择一个子集的最优决策,得到子集的子集。
- 递归执行,直到各个子集都有较好的分类时结束。
最优决策:
分类树决策的优劣用熵来衡量。


决策树的损失函数就是条件熵
决策树算法:
- ID3
- C4.5
- CART
ID3算法的思路:信息增益最大化
信息增益 = 熵 - 条件熵
C4.5算法的思路:信息增益率最大化
信息增益率 = 信息增益 / 熵
ID3算法和C4.5的区别仅在于信息增益和信息增益率。
决策树算法的优缺点:
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配问题。
- 适用数据类型:数值型和标称型。
参考资料:
https://kaiwu.lagou.com/course/courseInfo.htm?courseId=15#/detail/pc?id=224
https://easyai.tech/ai-definition/decision-tree/
《机器学习实战》
