一. Pandas简介
Pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
了解了Pandas的基本概念,再看一下Pandas在数据分析方面有哪些作用呢?

Pandas提供的数据结构和函数的设计,将使表格化数据的工作快速、简单、有表现力。所以利用Pandas进行数据操作、预处理、清洗是Python数据分析中的重要技能。
二. Pandas数据结构
常见的数据存储形式有Excel和数据库这两种,他们的存储有什么共同点呢?
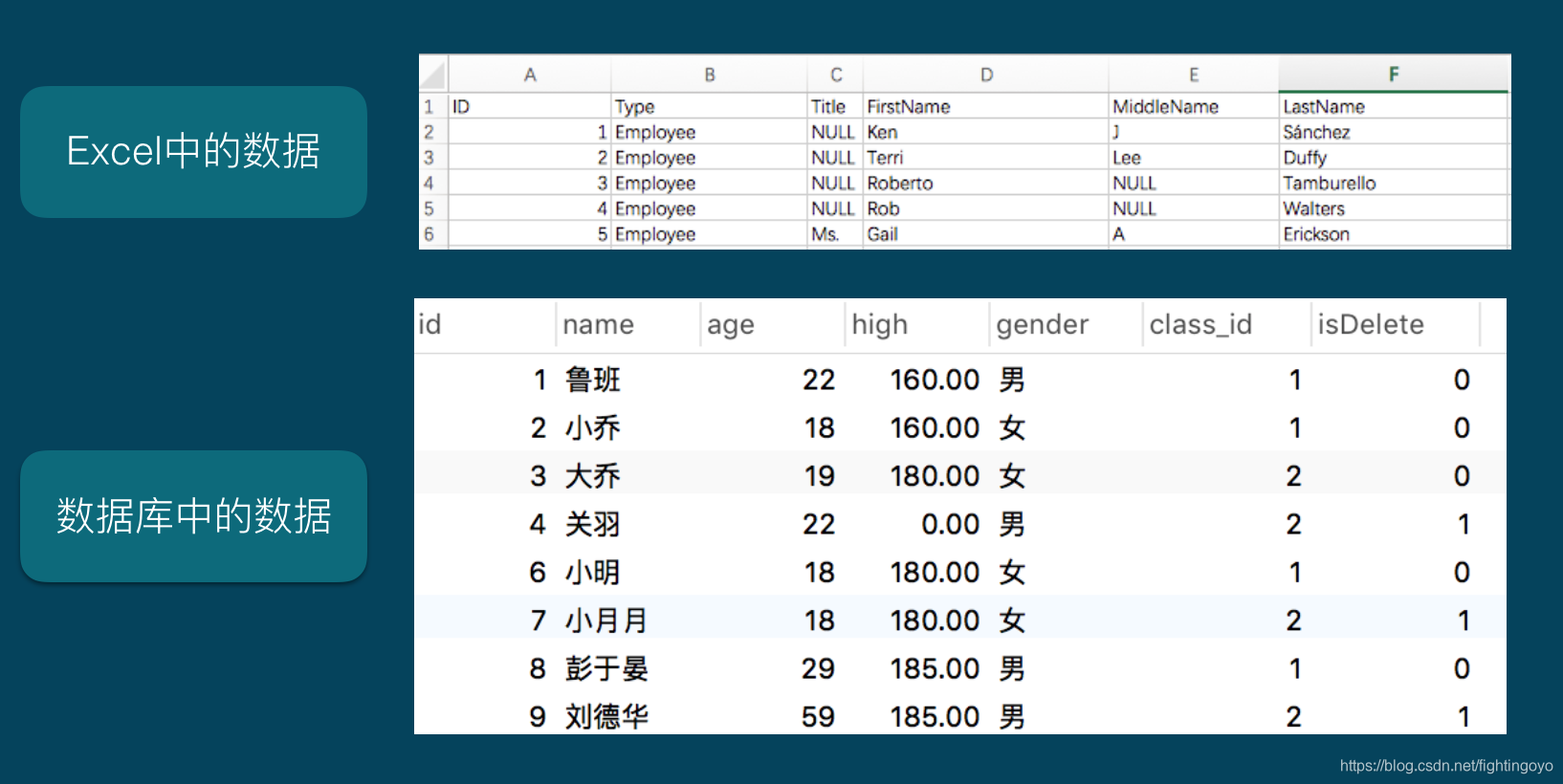
Pandas的DataFrame的结构就和他们相同,Series的结构和表中的行的结构相同。
import pandas as pd
# 通过Series存储每个英雄的基本信息
# 创建Series
s1 = pd.Series([1001,'lily','18','150.00','female'])
s2 = pd.Series([1002,'lucy','20','170.00','female'])
s3 = pd.Series([1003,'tomy','22','176.00','male'])
s4 = pd.Series([1004,'lilei','23','178.00','male'])
series_list = [s1,s2,s3,s4]
# 创建一个DataFrame对象存储通讯录
df = pd.DataFrame(series_list)
# 打印df
print(df)
# 输出结果如下:
0 1 2 3 4
0 1001 lily 18 150.00 female
1 1002 lucy 20 170.00 female
2 1003 tomy 22 176.00 male
3 1004 lilei 23 178.00 male
我们根据df的打印结果进一步解析DataFrame的结构。
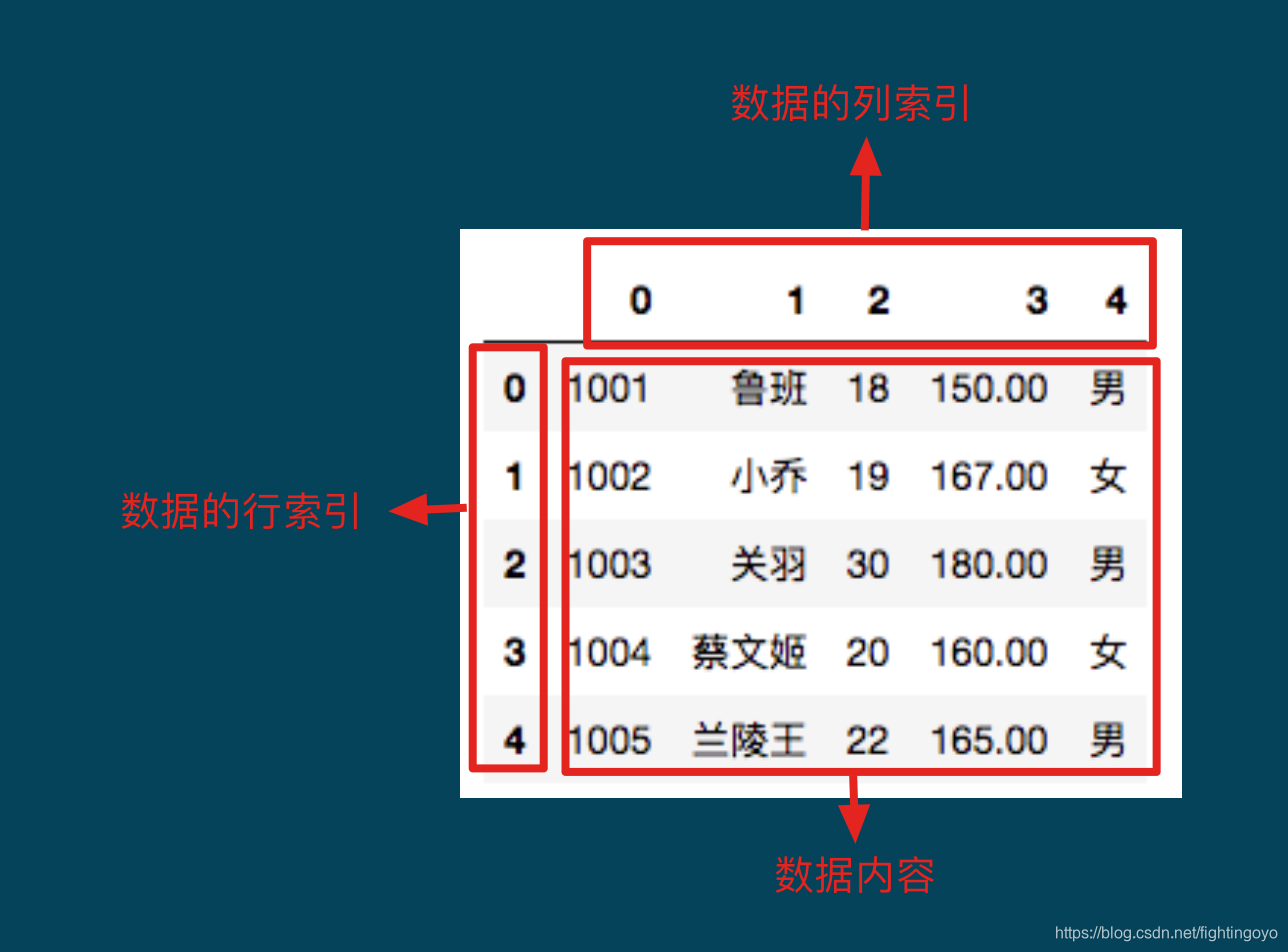
整个数据被分为三部分:行索引(index),列索引(columns)及数据内容(data)。
行、列索引的值在没有自定义的时候,会被默认设置上0-N的值,索引的作用就是为了更好的认知和查询数据。
可以看出每一列数据都是同种类型的数据,如果每一列设定一个有意义的名字,操作的时候就会更加方便。
三. Series的创建
Series是Pandas中最基本的对象,Series类似一种一维数组。事实上,Series 基本上就是基于 NumPy 的数组对象来的。和 NumPy 的数组不同,Series 能为数据自定义标签,也就是索引(index),然后通过索引来访问数组中的数据。
# 导入Series
from pandas import Series,DataFrame
# 创建Series,使用默认索引
se1 = Series(data=[1,'羞羞的尹志平','20','天生爱做色狼,杨过不喜欢他'])
print(se1)
# 输出结果:
0 1
1 羞羞的尹志平
2 20
3 天生爱做色狼,杨过不喜欢他
dtype: object
一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N)。
自定义一个索引看看。
# 导入Series
from pandas import Series,DataFrame
# 创建Series,使用自定义索引
se1 = Series(data=[1,'羞羞的尹志平','20','天生爱做色狼,杨过不喜欢他'],index=['序号','姓名','年龄','属性'])
print(se1)
# 输出结果:
序号 1
姓名 羞羞的尹志平
年龄 20
属性 天生爱做色狼,杨过不喜欢他
dtype: object
index参数是我们自定义的索引值,注意:参数值的个数一定要相同。
在创建Series时数据并不一定要是列表,也可以将一个字典传进去。
# 导入Series
from pandas import Series,DataFrame
# 将字典转换为Series
dic = {'name':'小龙女','属性':'超级漂亮','年龄':'29','备注':'杨过的老婆'}
se2 = Series(data=dic)
print(se2)
# 输出结果:
name 小龙女
属性 超级漂亮
年龄 29
备注 杨过的老婆
dtype: object
当数据是字典的时候,会将字典的键作为索引,字典的值作为索引对应的数据值。
综上可以看出,Series是一组带索引数组,与list相似,一般我们用其承装一条数据或者一行数据。多个Series可组成一个DataFrame。
四. DataFrame的创建
DataFrame(数据表)是一种 2 维数据结构,数据以表格的形式存储,分成若干行和列。通过 DataFrame,能很方便地处理数据。
调用DataFrame()可以将多种格式的数据转换为DataFrame对象,它的的三个参数data、index和columns分别为数据、行索引和列索引。
# 导入Series
from pandas import Series,DataFrame
# 创建二维列表,存储人物信息
list = [['杨过','神雕大侠','善于使用独臂大刀'],
['小龙女','神雕大侠的妻子','善于使用神雕大侠的大刀'],
['尹志平','神雕大侠的妻子的仇人','善于使用神雕大侠的妻子']]
# 创建dataframe
df = DataFrame(data=list)
print(df)
# 输出结果:
0 1 2
0 杨过 神雕大侠 善于使用独臂大刀
1 小龙女 神雕大侠的妻子 善于使用神雕大侠的大刀
2 尹志平 神雕大侠的妻子的仇人 善于使用神雕大侠的妻子
list是使用一个二维列表,将每一个人物的信息存储到一个列表中。
调用DataFrame()将二维列表转换为DataFrame对象,行列索引使用的是默认0-N数字代表。
# 导入Series
from pandas import Series,DataFrame
# 创建二维列表,存储人物信息
list = [['杨过','神雕大侠','善于使用独臂大刀'],
['小龙女','神雕大侠的妻子','善于使用神雕大侠的大刀'],
['尹志平','神雕大侠的妻子的仇人','善于使用神雕大侠的妻子']]
# 创建dataframe
df = DataFrame(data=list,index=[1,2,3],columns=['姓名','称号','特长'])
print(df)
# 输出结果:
姓名 称号 特长
1 杨过 神雕大侠 善于使用独臂大刀
2 小龙女 神雕大侠的妻子 善于使用神雕大侠的大刀
3 尹志平 神雕大侠的妻子的仇人 善于使用神雕大侠的妻子
当然我们也可以使用字典来创建一个DataFrame数据。
# 导入Series
from pandas import Series,DataFrame
# 创建字典,存储人物信息
# list = [['杨过','神雕大侠','善于使用独臂大刀'],
# ['小龙女','神雕大侠的妻子','善于使用神雕大侠的大刀'],
# ['尹志平','神雕大侠的妻子的仇人','善于使用神雕大侠的妻子']]
dic = {'姓名':['杨过','小龙女','尹志平'],
'称号':['神雕大侠','神雕大侠的妻子','神雕大侠的妻子的仇人'],
'特长':['善于使用独臂大刀','善于使用神雕大侠的大刀','善于使用神雕大侠的妻子']}
# 创建dataframe
df = DataFrame(dic)
print(df)
# 输出结果:
姓名 称号 特长
0 杨过 神雕大侠 善于使用独臂大刀
1 小龙女 神雕大侠的妻子 善于使用神雕大侠的大刀
2 尹志平 神雕大侠的妻子的仇人 善于使用神雕大侠的妻子
通过结果可以看出当字典格式的数据被dataframe整理后,字典的键将作为数据的列索引值。
五. Series常用属性与方法
表格数据中的每一列或者每一行的数据结构都是Series,它可以看成是一维的表格数据。
它可以属于DataFrame的一部分也可以作为一个独立的数据结构存在。
from pandas import Series
mp=['001','002','003','004','005','006']
name=['亚瑟', '后裔','小乔','哪吒' ,'虞姬','王昭君']
se = Series(data=name,index=mp)
# 获取数据的值
print(se.values)
print('-'*20)
# 获取索引的值
print(se.index.tolist())
print('-'*20)
# 获取每队数据与索引的值
print(list(se.items()))
# 输出结果:
['亚瑟' '后裔' '小乔' '哪吒' '虞姬' '王昭君']
--------------------
['001', '002', '003', '004', '005', '006']
--------------------
[('001', '亚瑟'), ('002', '后裔'), ('003', '小乔'), ('004', '哪吒'), ('005', '虞姬'), ('006', '王昭君')]
values、index、items返回的对象分别是List、Index、Zip类型的数据,为了方便我们使用和观察数据,可以使用series.index.tolist()和list(series.items())方法转化成列表类型。
Series就像将索引值暴露在外面的List,其实它们除了外表相似以外,在获取数据方面也非常的相似。我们可以通过索引值来进行单个数据的访问,同样也支持切片选择多个数据。
from pandas import Series
mp=['001','002','003','004','005','006']
name=['亚瑟', '后裔','小乔','哪吒' ,'虞姬','王昭君']
se = Series(data=name,index=mp)
# 使用索引获取单个数值
print(se['002'])
print('-'*20)
# 使用索引获取多个不连续的数值
print('索引下标')
print(se[['001','003','006']])
print('-'*20)
# 使用索引获取多个连续的数值
print('索引切片')
print(se['004':'006'])
# 输出结果:
后裔
--------------------
索引下标
001 亚瑟
003 小乔
006 王昭君
dtype: object
--------------------
索引切片
004 哪吒
005 虞姬
006 王昭君
dtype: object
注意:
- 获取数据格式—对象名[]
- 获取多个不连续数据时是双层括号— 对象名[[]]
- 使用切片时使用的是—对象名[:]
那么, 原来的默认索引去哪里了呢?其实还是存在的,并且可以使用。
我们自定的index值被叫做索引下标,没有设置index值时会有一个默认的值叫做位置下标。
from pandas import Series
mp=['001','002','003','004','005','006']
name=['亚瑟', '后裔','小乔','哪吒' ,'虞姬','王昭君']
se = Series(data=name,index=mp)
# 使用索引获取单个数值
print(se[0])
print('-'*20)
# 使用索引获取多个不连续的数值
print('位置下标')
print(se[[1,3,5]])
print('-'*20)
# 使用索引获取多个连续的数值
print('位置切片')
print(se[3:5])
# 输出结果:
亚瑟
--------------------
位置下标
002 后裔
004 哪吒
006 王昭君
dtype: object
--------------------
位置切片
004 哪吒
005 虞姬
dtype: object
需要注意的是:当使用默认索引进行切片时,不会取最后一个值;而使用自定义索引,则会取到最后一个值。
和Python其它数据结构类似,我们可以很方便的利用循环来遍历Series。
- 我们可以直接遍历Series的值。
# 遍历并拿到data数据
for value in series:
print(value)
- 通过keys(),遍历Series的索引。
# 遍历并拿到index数据
for value in series.keys():
print(value)
- 也可以通过items(),遍历Series的每对索引和数据
# 遍历并拿到每对索引和数据
for value in series.items()
print(value)
# 或者
for key,value in series.items():
print(key,value)
看如下的示例:
from pandas import Series
mp=['001','002','003','004','005','006']
name=['亚瑟', '后裔','小乔','哪吒' ,'虞姬','王昭君']
se = Series(data=name,index=mp)
# 获取数据
for data in se:
print(data)
print('-'*20)
# 获取索引
for value in se.keys():
print(value)
print('-'*20)
# 同时获取数据与索引
for i in se.items():
print(i)
print('~'*20)
for j,k in se.items():
print(j,k)
# 输出结果:
亚瑟
后裔
小乔
哪吒
虞姬
王昭君
--------------------
001
002
003
004
005
006
--------------------
('001', '亚瑟')
('002', '后裔')
('003', '小乔')
('004', '哪吒')
('005', '虞姬')
('006', '王昭君')
~~~~~~~~~~~~~~~~~~~~
001 亚瑟
002 后裔
003 小乔
004 哪吒
005 虞姬
006 王昭君
六. DataFrame数据的获取与遍历
DataFrame里的数据是按照行和列来进行排列,现在我们一起来看下如何对DataFrame的数据按照行或者列进行选择、遍历以及修改。
首先数据的维度是一维还是二维的我们可以使用ndim查看,数据的行数和列数shape,以及行列的索引值index、columns。
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋功力太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 打印DataFrame
print(df)
print('-' * 20)
# 获取数据的维度
print(df.ndim)
print('-' * 20)
# 获取行数和列数
print(df.shape)
print('-' * 20)
# 获取行索引
print(df.index.tolist())
print('-' * 20)
# 获取列索引
print(df.columns.tolist())
# 输出结果:
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
003 乔峰 27 主角 降龙十八掌 小子,看我降龙十八掌
004 段誉 25 主角 六脉神剑 姐姐,我有六脉神剑哦
005 虚竹 26 主角 泡妞大法 梦姑,你在哪里啊?我好想你
006 阿紫 22 配角 毒力无敌 姐夫,我要和你在一起,我要和你困觉
007 逍遥子 98 老配角 眼神就是我的武器 哈哈,你的围棋功力太弱了
--------------------
2
--------------------
(7, 5)
--------------------
['001', '002', '003', '004', '005', '006', '007']
--------------------
['姓名', '年龄', '角色', '绝招', '口号']
需要注意的是,如果我们数据量是10G,像这种数据量比较大并且我们想看数据的具体情况的时候,这些属性就不够用了,如果直接打印df有比较耗时,所以我们可以只获取前几行或者后几行,了解数据的构成即可。
可以使用head()和tail()方法取出前几行或后几行的数据,两个方法都有默认值,默认值是5,如果数据不够5个会将全部数据拿出来。当然也可以自己设置。
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋公里太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 获取前3条数据
print(df.head(3))
print('-'*20)
# 获取最后3条数据
print(df.tail(3))
# 输出结果:
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
003 乔峰 27 主角 降龙十八掌 小子,看我降龙十八掌
--------------------
姓名 年龄 角色 绝招 口号
005 虚竹 26 主角 泡妞大法 梦姑,你在哪里啊?我好想你
006 阿紫 22 配角 毒力无敌 姐夫,我要和你在一起,我要和你困觉
007 逍遥子 98 老配角 眼神就是我的武器 哈哈,你的围棋功力太弱了
获取行数据
了解数据了,我们就可以修炼下一个招式–获取行数据了。
1. 通过位置索引直接获取
# 通过位置索引切片获取一行
print(df[0:1])
# 通过位置索引切片获取多行
print(df[1:3])
# 获取多行里面的某几列
print(df[1:3][['name','age']])
# 获取DataFrame的列
print(df['name'])
# 如果获取多个列
print(df[['name','age']])
看如下示例:
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋功力太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 通过位置索引获取一行数据
print(df[0:1])
print('-'*20)
# 通过位置索引获取多行数据
print(df[0:5])
print('-'*20)
# 获取某几行的某几列数据
print(df[1:3][['姓名','绝招']])
print('-'*20)
# 获取某列数据
print(df['姓名'])
print('~'*20)
print(df[['姓名']])
print('-'*20)
# 获取多列数据
print(df[['姓名','口号']])
# 输出结果:
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
--------------------
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
003 乔峰 27 主角 降龙十八掌 小子,看我降龙十八掌
004 段誉 25 主角 六脉神剑 姐姐,我有六脉神剑哦
005 虚竹 26 主角 泡妞大法 梦姑,你在哪里啊?我好想你
--------------------
姓名 绝招
002 李莫愁 钢铁浮尘
003 乔峰 降龙十八掌
--------------------
001 星宿老怪
002 李莫愁
003 乔峰
004 段誉
005 虚竹
006 阿紫
007 逍遥子
Name: 姓名, dtype: object
~~~~~~~~~~~~~~~~~~~~
姓名
001 星宿老怪
002 李莫愁
003 乔峰
004 段誉
005 虚竹
006 阿紫
007 逍遥子
--------------------
姓名 口号
001 星宿老怪 星宿老仙,法力无边
002 李莫愁 哼,杨过和小龙女不能在一起
003 乔峰 小子,看我降龙十八掌
004 段誉 姐姐,我有六脉神剑哦
005 虚竹 梦姑,你在哪里啊?我好想你
006 阿紫 姐夫,我要和你在一起,我要和你困觉
007 逍遥子 哈哈,你的围棋功力太弱了
- df[]不支持直接输入标签索引获取行数据,例如:df[‘001’],只能通过df[0:1]这种方式
- 这种方式可以获取一列数据,列如:df[‘name’]或者df[[‘name’]]
- 如果想获取多行里面的某几列可写成:df[行][列],例如:df[1:3][[‘name’,‘age’]],将行索引值放到同一个列表中,再将列表放到第二个方括号中
- 这种方式只能获取连续多行的数据,不能间隔获取行数据
2. 通过行位置索引筛选iloc[]
# 取一行
print(df.iloc[1])
# 取连续多行
print(df.iloc[0:2])
# 取间断的多行
print(df.iloc[[0,2],:])
# 取某一列
print(df.iloc[:,1])
# 某一个值
print(df.iloc[1,0])
看如下示例:
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋功力太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 获取一行数据
print(df.iloc[[1]])
print('-'*20)
# 获取连续多行的数据
print(df.iloc[0:3])
print('-'*20)
# 获取间断的多行数据
print(df.iloc[[1,3,4]])
print('-'*20)
# 获取某一列的数据
print(df.iloc[:,[2]])
print('-'*20)
# 获取连续多列的数据
print(df.iloc[:,1:3])
print("-"*20)
# 获取间隔多列的数据
print(df.iloc[:,[1,3,4]])
print("-"*20)
# 获取间隔的多行多列的数据
print(df.iloc[[0,2,3],[1,3,4]])
print('-'*20)
# 获取某个数值
print(df.iloc[[1],[0]])
# 输出结果:
姓名 年龄 角色 绝招 口号
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
--------------------
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
003 乔峰 27 主角 降龙十八掌 小子,看我降龙十八掌
--------------------
姓名 年龄 角色 绝招 口号
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
004 段誉 25 主角 六脉神剑 姐姐,我有六脉神剑哦
005 虚竹 26 主角 泡妞大法 梦姑,你在哪里啊?我好想你
--------------------
角色
001 配角
002 配角
003 主角
004 主角
005 主角
006 配角
007 老配角
--------------------
年龄 角色
001 80 配角
002 36 配角
003 27 主角
004 25 主角
005 26 主角
006 22 配角
007 98 老配角
--------------------
年龄 绝招 口号
001 80 化功大法 星宿老仙,法力无边
002 36 钢铁浮尘 哼,杨过和小龙女不能在一起
003 27 降龙十八掌 小子,看我降龙十八掌
004 25 六脉神剑 姐姐,我有六脉神剑哦
005 26 泡妞大法 梦姑,你在哪里啊?我好想你
006 22 毒力无敌 姐夫,我要和你在一起,我要和你困觉
007 98 眼神就是我的武器 哈哈,你的围棋功力太弱了
--------------------
年龄 绝招 口号
001 80 化功大法 星宿老仙,法力无边
003 27 降龙十八掌 小子,看我降龙十八掌
004 25 六脉神剑 姐姐,我有六脉神剑哦
--------------------
姓名
002 李莫愁
3. 通过行标签索引筛选loc[]
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋功力太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 获取某一行的数据
print(df.loc[['001']])
print('-'*20)
# 获取某一行某一列的数据
print(df.loc[['001'],['姓名']])
print('-'*20)
# 获取某一行多列的数据
print(df.loc[['001'],['姓名','绝招']])
print('-'*20)
# 获取间隔的多行多列的数据
print(df.loc[['001','003'],['姓名','绝招','口号']])
print('-'*20)
# 获取连续多行多列的数据
print(df.loc['001':'003','姓名':'口号'])
# 输出结果:
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
--------------------
姓名
001 星宿老怪
--------------------
姓名 绝招
001 星宿老怪 化功大法
--------------------
姓名 绝招 口号
001 星宿老怪 化功大法 星宿老仙,法力无边
003 乔峰 降龙十八掌 小子,看我降龙十八掌
--------------------
姓名 年龄 角色 绝招 口号
001 星宿老怪 80 配角 化功大法 星宿老仙,法力无边
002 李莫愁 36 配角 钢铁浮尘 哼,杨过和小龙女不能在一起
003 乔峰 27 主角 降龙十八掌 小子,看我降龙十八掌
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋功力太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 获取某一行所有列的数据
print(df.loc['001',:])
print('-'*20)
# # 获取某一行某一列的数据
print(df.loc['001','姓名'])
print('-'*20)
# # 获取某一行多列的数据
print(df.loc['001',['姓名','绝招']])
# 输出结果:
姓名 星宿老怪
年龄 80
角色 配角
绝招 化功大法
口号 星宿老仙,法力无边
Name: 001, dtype: object
--------------------
星宿老怪
--------------------
姓名 星宿老怪
绝招 化功大法
Name: 001, dtype: object
注意:
- df.loc[] 通过标签索引获取行数据,它的语法结构是这样的:df.loc[[行],[列]],方括号中用逗号分隔,左侧是行、右侧是列
- 如果行或者列使用切片的时候,要把方括号去掉,列df.loc[‘001’:‘003’,‘姓名’:‘绝招’]。
需要注意的是:loc和iloc的切片操作在是否包含切片终点的数据有差异。
- loc[‘001’:‘003’]的结果中包含行索引003对应的行。
- iloc[0:2] 结果中不包含序号为2的数据,切片终点对应的数据不在筛选结果中。
遍历DataFrame
- iterrows(): 按行遍历。将DataFrame的每一行转化为(index, Series)对。index为行索引值,Series为该行对应的数据
for index,row_data in df.iterrows():
print(index,row_data)
- iteritems():按列遍历,将DataFrame的每一列转化为(column, Series)对。column为列索引的值,Series为该列对应的数据。
for col,col_data in df.iteritems():
print(col)
示例如下:
import pandas as pd
# 创建字典存储数据
dic = {'姓名': ['星宿老怪', '李莫愁', '乔峰', '段誉', '虚竹', '阿紫', '逍遥子'],
'年龄': ['80', '36', '27', '25', '26', '22', '98'],
'角色': ['配角', '配角', '主角', '主角', '主角', '配角', '老配角'],
'绝招': ['化功大法', '钢铁浮尘', '降龙十八掌', '六脉神剑', '泡妞大法', '毒力无敌', '眼神就是我的武器'],
'口号': ['星宿老仙,法力无边', '哼,杨过和小龙女不能在一起', '小子,看我降龙十八掌', '姐姐,我有六脉神剑哦', '梦姑,你在哪里啊?我好想你', '姐夫,我要和你在一起,我要和你困觉',
'哈哈,你的围棋功力太弱了']}
# 索引列表
index_list = ['001', '002', '003', '004', '005', '006', '007']
# 创建DataFrame
df = pd.DataFrame(data=dic, index=index_list)
# 按行遍历
for index,row_data in df.iterrows():
print(index,row_data)
print('-'*20)
# 按列遍历
for co,col_data in df.iteritems():
print(co,col_data)
# 输出结果:
001 姓名 星宿老怪
年龄 80
角色 配角
绝招 化功大法
口号 星宿老仙,法力无边
Name: 001, dtype: object
002 姓名 李莫愁
年龄 36
角色 配角
绝招 钢铁浮尘
口号 哼,杨过和小龙女不能在一起
Name: 002, dtype: object
003 姓名 乔峰
年龄 27
角色 主角
绝招 降龙十八掌
口号 小子,看我降龙十八掌
Name: 003, dtype: object
004 姓名 段誉
年龄 25
角色 主角
绝招 六脉神剑
口号 姐姐,我有六脉神剑哦
Name: 004, dtype: object
005 姓名 虚竹
年龄 26
角色 主角
绝招 泡妞大法
口号 梦姑,你在哪里啊?我好想你
Name: 005, dtype: object
006 姓名 阿紫
年龄 22
角色 配角
绝招 毒力无敌
口号 姐夫,我要和你在一起,我要和你困觉
Name: 006, dtype: object
007 姓名 逍遥子
年龄 98
角色 老配角
绝招 眼神就是我的武器
口号 哈哈,你的围棋功力太弱了
Name: 007, dtype: object
--------------------
姓名 001 星宿老怪
002 李莫愁
003 乔峰
004 段誉
005 虚竹
006 阿紫
007 逍遥子
Name: 姓名, dtype: object
年龄 001 80
002 36
003 27
004 25
005 26
006 22
007 98
Name: 年龄, dtype: object
角色 001 配角
002 配角
003 主角
004 主角
005 主角
006 配角
007 老配角
Name: 角色, dtype: object
绝招 001 化功大法
002 钢铁浮尘
003 降龙十八掌
004 六脉神剑
005 泡妞大法
006 毒力无敌
007 眼神就是我的武器
Name: 绝招, dtype: object
口号 001 星宿老仙,法力无边
002 哼,杨过和小龙女不能在一起
003 小子,看我降龙十八掌
004 姐姐,我有六脉神剑哦
005 梦姑,你在哪里啊?我好想你
006 姐夫,我要和你在一起,我要和你困觉
007 哈哈,你的围棋功力太弱了
Name: 口号, dtype: object
六. 总结
Series常用属性和方法:
- 获取数据的值values
- 获取数据的索引index
- 获取每对索引和值items()
- 索引下标:自定义的Index
- 位置下标:默认的Index
- 切片:连续se['001:'004];不连续se[[‘001’,‘004’]]
- 数据遍历:使用for…in values、keys()、items()获取数据、索引和每对索引、数据
DataFrame的数据获取与遍历:
- 获取数据的行数和列数shape
- 获取数据的前几行head()和后几行tail()
- df[]不能直接输入标签索引获取数据
- 获取多行里面的某几列:df[[行][列]]
- df.loc[]标签索引获取行数据
- df.iloc[]位置索引获取行数据
- 数据遍历:for…in iterrows()按行遍历;for…in iteritems按列遍历
五. 练习
- 复仇者联盟
from pandas import Series,DataFrame
# 第一种方法,字典存储天团信息
dic = {'姓名':['小罗伯特·唐尼','克里斯·埃文斯','斯嘉丽·约翰逊','克里斯·海姆斯沃斯'],
'角色':['钢铁侠','美国队长','黑寡妇','雷神'],
'武器':['钢铁战衣','盾牌','寡妇蛰','雷神之锤'],
'语录':['和平,我热爱和平','最好的武器是重新开始','嘿,大兄弟,太阳下山了','要用知识打败无知']}
# 创建dataframe
df = DataFrame(data=dic)
print(df)
# 第二种方法,使用列表存储天团信息
list = [['小罗伯特·唐尼', '钢铁侠', '钢铁战衣', '和平,我热爱和平'],
['克里斯·埃文斯', '美国队长', '盾牌', '最好的武器是重新开始'],
['斯嘉丽·约翰逊', '黑寡妇', '寡妇蛰', '嘿,大兄弟,太阳下山了'],
['克里斯·海姆斯沃斯', '雷神', '雷神之锤', '要用知识打败无知']]
# 创建dataframe
df = DataFrame(data=list,index=[0,1,2,3],columns=['姓名','角色','武器','语录'])
print(df)
# 输出结果:
姓名 角色 武器 语录
0 小罗伯特·唐尼 钢铁侠 钢铁战衣 和平,我热爱和平
1 克里斯·埃文斯 美国队长 盾牌 最好的武器是重新开始
2 斯嘉丽·约翰逊 黑寡妇 寡妇蛰 嘿,大兄弟,太阳下山了
3 克里斯·海姆斯沃斯 雷神 雷神之锤 要用知识打败无知
- 记录备忘录信息
from pandas import Series,DataFrame
# 创建索引
index_list = ['NO1','NO2','NO3']
# 创建字典
dic = {'姓名':Series(['娜娜','小红','依依'],index=index_list),
'类型':Series(['可爱单纯','风骚火辣','性感高冷'],index=index_list),
'爱好':Series(['逛街、电影、爱吃甜','喝酒、蹦迪、爱吃辣','看书、烘焙、爱吃酸'],index=index_list),
'时间':Series(['2019-2-14去蹦迪','2019-2-16去吃饭','2019-2-18去死的时候'],index=index_list)}
df = DataFrame(dic)
print(df)
# 第二种方法,创建列表,存储信息
se1 = ['娜娜','可爱单纯','逛街、电影、爱吃甜','2019-2-14去蹦迪']
se2 = ['小红','风骚火辣','喝酒、蹦迪、爱吃辣','2019-2-16去吃饭']
se3 = ['依依','性感高冷','看书、烘焙、爱吃酸','2019-2-18去死的时候']
series_list = [se1,se2,se3]
# 创建Dataframe
df = DataFrame(data=series_list,index=['NO1','NO2','NO3'],columns=['姓名','类型','爱好','时间'])
print(df)
# 输出结果:
姓名 类型 爱好 时间
NO1 娜娜 可爱单纯 逛街、电影、爱吃甜 2019-2-14去蹦迪
NO2 小红 风骚火辣 喝酒、蹦迪、爱吃辣 2019-2-16去吃饭
NO3 依依 性感高冷 看书、烘焙、爱吃酸 2019-2-18去死的时候
- 根据公司的员工信息登记表数据,获取相关信息:
- 获取工号为003~007的所有员工信息;
- 获取所有员工的年龄和工资信息;
- 查看一个你感兴趣员工的婚姻状况。
from pandas import Series,DataFrame
index_list = ['001','002','003','004','005','006','007','008','009','010']
name_list = ['李白','王昭君','诸葛亮','狄仁杰','孙尚香','妲己','周瑜','张飞','王昭君','大乔']
age_list = [25,28,27,25,30,29,25,32,28,26]
salary_list = ['10k','12.5','20k','14k','12k','17k','18k','21k','22k','21.5k']
marital_list = ['NO','NO','YES','YES','NO','NO','NO','YES','NO','YES']
dic={
'姓名': Series(data=name_list,index=index_list),
'年龄': Series(data=age_list,index=index_list),
'薪资': Series(data=salary_list,index=index_list),
'婚姻状况': Series(data=marital_list,index=index_list)
}
df = DataFrame(data=dic,index=index_list)
# 获取工号003-007的所有员工信息
print(df.loc['003':'007'])
print('-'*20)
# 获取所有员工的年龄和工资信息
print(df.loc[:,['年龄','薪资']])
print('-'*20)
# 随意查看某个感兴趣的员工的婚姻状况
print(df.loc[['002'],['姓名','婚姻状况']])
# 输出结果:
姓名 年龄 薪资 婚姻状况
003 诸葛亮 27 20k YES
004 狄仁杰 25 14k YES
005 孙尚香 30 12k NO
006 妲己 29 17k NO
007 周瑜 25 18k NO
--------------------
年龄 薪资
001 25 10k
002 28 12.5
003 27 20k
004 25 14k
005 30 12k
006 29 17k
007 25 18k
008 32 21k
009 28 22k
010 26 21.5k
--------------------
姓名 婚姻状况
002 王昭君 NO
- 根据练习3的信息,用三种方法遍历获取所有员工的薪资信息;获取最高薪水值
from pandas import Series,DataFrame
index_list = ['001','002','003','004','005','006','007','008','009','010']
name_list = ['李白','王昭君','诸葛亮','狄仁杰','孙尚香','妲己','周瑜','张飞','王昭君','大乔']
age_list = [25,28,27,25,30,29,25,32,28,26]
salary_list = ['10k','12.5','20k','14k','12k','17k','18k','21k','22k','21.5k']
marital_list = ['NO','NO','YES','YES','NO','NO','NO','YES','NO','YES']
dic={
'姓名': Series(data=name_list,index=index_list),
'年龄': Series(data=age_list,index=index_list),
'薪资': Series(data=salary_list,index=index_list),
'婚姻状况': Series(data=marital_list,index=index_list)
}
df=DataFrame(data=dic,index=index_list)
# 第一种方法,df[]
list2 = []
for value in df['薪资']:
print(value)
# 获取最大值
list2.append(value)
print(max(list2))
print('-'*20)
# 第二种方法,标签索引
for value in df.loc[:,'薪资']:
print(value)
print('-'*20)
# 第三种方法,位置索引
for value in df.iloc[:,2]:
print(value)
print('-'*20)
# 第四种方法,遍历行
for index,row_data in df.iterrows():
print(row_data['薪资'])
print('-'*20)
# 第五种方法,遍历列
for co,col_data in df.iteritems():
if co == '薪资':
print(col_data)
print('-'*20)
# 获取最大值
list1 = []
for co,col_data in df.iteritems():
if co =='薪资':
for salary in col_data:
list1.append(salary)
print(max(list1))
# 输出结果:
10k
12.5
20k
14k
12k
17k
18k
21k
22k
21.5k
22k
--------------------
10k
12.5
20k
14k
12k
17k
18k
21k
22k
21.5k
--------------------
10k
12.5
20k
14k
12k
17k
18k
21k
22k
21.5k
--------------------
10k
12.5
20k
14k
12k
17k
18k
21k
22k
21.5k
--------------------
001 10k
002 12.5
003 20k
004 14k
005 12k
006 17k
007 18k
008 21k
009 22k
010 21.5k
Name: 薪资, dtype: object
--------------------
22k
