前言
代价函数决定着模型训练的方向,而优化方法也是建立在代价函数的基础上的。而不同的问题往往有不同的代价函数,这里最一些比较常见的代价函数进行总结,也供模型设计的时候予以参考。
在这之前首先做一个区分:
损失函数(Loss Function):是定义在单个样本上的,是指一个样本的误差。
代价函数(Cost Function):是定义在整个训练集上的,是所有样本误差的平均,也就是所有损失函数值的平均。
目标函数(Object Function):是指最终需要优化的函数,一般来说是经验风险+结构风险,也就是(代价函数+正则化项)。
一、常见的代价函数
下面主要是PyTorch中的一些loss函数,能够反映各种类型的代价函数。
L1 Loss
计算 output 和 target 之差的绝对值,可以通过参数调整 mean 或 sum.
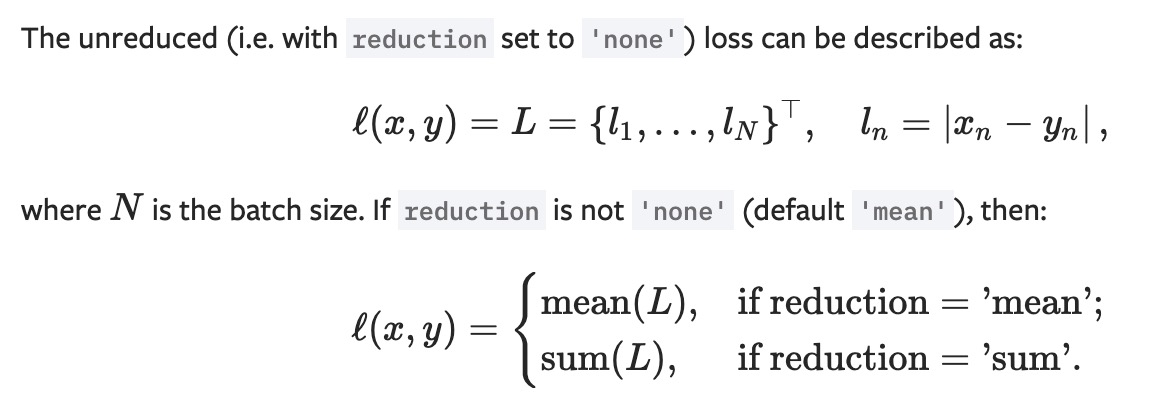
MSELoss
计算 output 和 target 之差的平方, 可以通过参数调整 mean 或 sum.
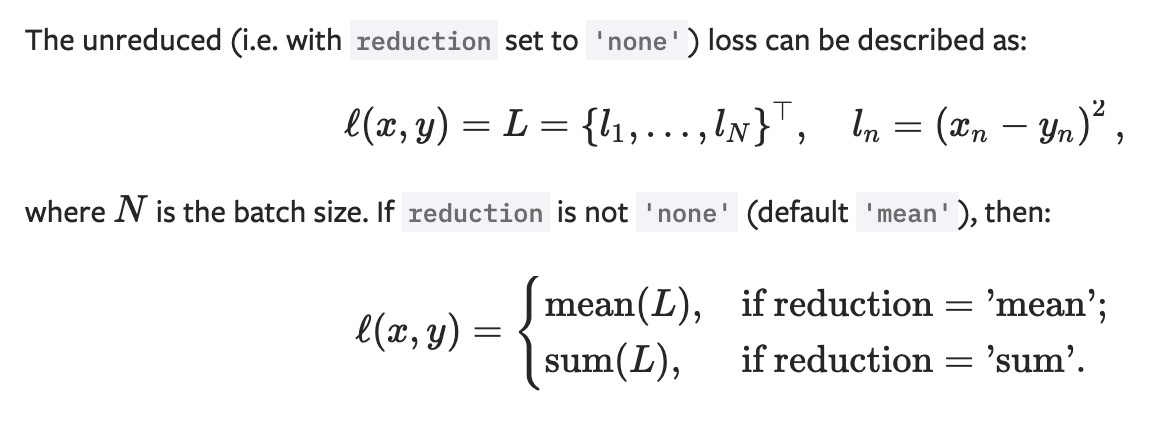
CrossEntropyLoss
将输入经过 softmax 激活函数之后,再计算其与 target 的交叉熵损失。即该方法将 nn.LogSoftmax() 和 nn.NLLLoss() 进行了结合。严格意义上的交叉熵损失函数应该是 nn.NLLLoss()
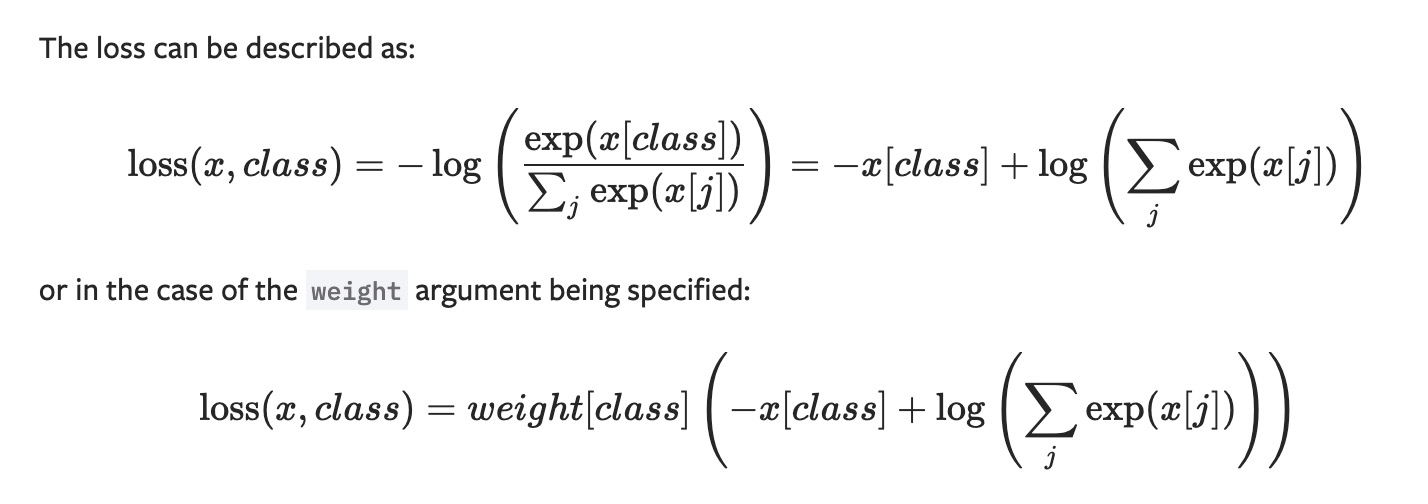
交叉熵损失 (cross-entropy Loss) 又称为对数似然损失 (Log-likelihood Loss)、对数损失;二分类时还可称之为逻辑斯谛回归损失 (Logistic Loss)。交叉熵损失函数表达式为 L = – sigama(y_i * log(x_i))。pytroch 这里不是严格意义上的交叉熵损失函数,而是先将 input 经过 softmax 激活函数,将向量“归一化”成概率形式,然后再与 target 计算严格意义上交叉熵损失。
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax 激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
NLLLoss
常用于多分类任务,但是 input 在输入 NLLLoss() 之前,需要对 input 进行 log_softmax 函数激活,即将 input 转换成概率分布的形式,并且取对数。其实这些步骤在 CrossEntropyLoss 中就有,如果不想让网络的最后一层是log_softmax层的话,就可以采用 CrossEntropyLoss 完全代替此函数。

KLDivLoss
KL散度( Kullback–Leibler divergence) 又称为相对熵 (Relative Entropy),用于描述两个概率分布之间的差异。计算公式(离散时):其中 p 表示真实分布,q 表示 p 的拟合分布, D(P||Q) 表示当用概率分布q来拟合真实分布 p 时,产生的信息损耗。这里的信息损耗,可以理解为损失,损失越低,拟合分布q越接近真实分布 p。同时也可以从另外一个角度上观察这个公式,即计算的是 p 与 q 之间的对数差在 p 上的期望值。 特别注意,D(p||q) ≠ D(q||p), 其不具有对称性,因此不能称为K-L距离。

二、代价函数选择的建议
这里主要介绍了最常用的几个代价函数。一般来说回归问题使用均方误差,或者均方根、绝对值等等,而分类问题使用交叉熵。对于交叉熵例如在PyTorch中等价于 nn.LogSoftmax() + nn.NLLLoss()。另外, 二分类的sigmoid可以理解为一种特殊的softmax。
参考资料
https://www.cnblogs.com/lliuye/p/9549881.html
https://www.jianshu.com/p/3dc80877bb6b
