跟着尚硅谷视频重新开始学习复习,做个笔记+自我总结
注释语法:
单行注释# 或者--加空格(空格必须有)
多行注释/* */
查询
基础查询
/* select 查询列表 from 表名 可以查表中字段/常量值/表达式/函数 查询结果是虚拟表格。并不真实存在 */ # 查询一个字段 SELECT last_name FROM employees; # 查询多个字段 SELECT last_name, salary, email FROM employees; # 查询所有字段 SELECT * FROM employees; # 查询常量值 SELECT 100; SELECT 'john'; SELECT 100%98; # 查询函数 SELECT VERSION(); # 起别名 /* 优点:便于理解;帮助区分重名字段 */ #方式一 SELECT 100%98 AS 结果; SELECT last_name AS 姓, first_name AS 名 FROM `employees`; #方式二 SELECT `last_name` 姓, `first_name` 名 FROM `employees`; #别名有空格或特殊字符加双引号 SELECT `salary` AS "out put" FROM `employees`; # 去重:加关键字distinct SELECT DISTINCT `department_id` FROM `employees`; # +号作用:只是运算符 # 要想拼接字段,用concat函数 SELECT CONCAT(`last_name`, `first_name`) AS 姓名 FROM `employees`; # 显示数据库结构 DESC `departments`;
条件查询
# 条件表达式筛选:< > = != <> <= >=
#工资>12000的员工信息
SELECT
*
FROM
`employees`
WHERE
salary>12000;
# 按逻辑运算符查询: and or not
#查询工资在10000到20000之间的员工名、工资及奖金
SELECT `last_name`, `salary`, `commission_pct`
FROM `employees`
WHERE salary>=10000 AND salary<=20000;
# 模糊查询:
/*
like 和通配符搭配。%任意多个字符,_任意单个字符
between and 包含临界值,顺序不能换
in
is null
*/
#员工名包含字符’a'的员工信息
SELECT *
FROM `employees`
WHERE `last_name` LIKE '%a%';
#查询员工编号在100到200间的员工信息
SELECT *
FROM `employees`
WHERE `employee_id` BETWEEN 100 AND 200;
#查询员工工种编号是PU_CLERK,ST_MAN,ST_CLERK中一个的员工名和工种编号
SELECT `last_name`, `job_id`
FROM `employees`
WHERE job_id IN ('PU_CLERK', 'ST_MAN', 'ST_CLERK');
#查询没有奖金的员工名和奖金率
SELECT `last_name`, `commission_pct`
FROM `employees`
WHERE `commission_pct` IS NULL;
#安全等于<=>
#查询没有奖金的员工名和奖金率
SELECT `last_name`, `commission_pct`
FROM `employees`
WHERE `commission_pct` <=> NULL;
排序查询
/* 语法:order by 排序列表 [asc(升序)|decs(降序)] 默认升序 */ #查询员工信息,工资由高到低排序 SELECT * FROM `employees` ORDER BY salary DESC; #按表达式查询:按年薪高低显示员工信息和年薪 SELECT *, salary*12*(1+IFNULL(`commission_pct`,0)) 年薪 FROM `employees` ORDER BY 年薪 DESC; #查询员工信息,先按工资排序再按员工编号排序 SELECT * FROM `employees` ORDER BY salary ASC, `employee_id` DESC;
常见函数
字符函数
#length 获取参数值的字节个数
SELECT LENGTH('john');
#cancat 拼接字符串
SELECT CONCAT(`last_name`, '_', `first_name`) 姓名 FROM `employees`;
#upper lower 改变字符串大小写
SELECT CONCAT(UPPER(`last_name`), LOWER(`first_name`)) 姓名
FROM `employees`;
#substr/substring 截取字符串 注:索引从1开始,截取从指定索引处指定字符长度的字符
SELECT SUBSTR("今天天气可真好", 1, 2);
#instr 返回子串第一次出现索引,不存在返回0
#trim 去除前后空格,或前后指定字符
SELECT TRIM('a' FROM 'aaaaaaaa刘诗诗aaaaaaaaaaaaa');
#lpad 用指定字符实现左填充指定长度
SELECT LPAD('刘诗诗', 10, '*') AS out_put;
#rpad 用指定字符实现右填充指定长度
#repalce 替换
数学函数
#round 四舍五入 select round(1.55); #2 select round(1.567, 2); #1.57小数点后保留两位
#roll 向上取整:返回大于等于参数的最小整数
#floor 向下取整
#truncate 截断 select truncate(1.68,1) #mod 取余
日期函数
#now 返回当前系统日期时间
#curdate 返回当前系统日期,不包含时间
#curtime 返回当前系统时间,不包含日期
#可以获取指定部分,年、月、日、小时、分钟、秒 SELECT YEAR(NOW()); SELECT MONTH(NOW()); SELECT MONTHNAME(NOW());
#str_to_date 将日期格式字符转换成指定格式
#date_format 将日期转换成字符
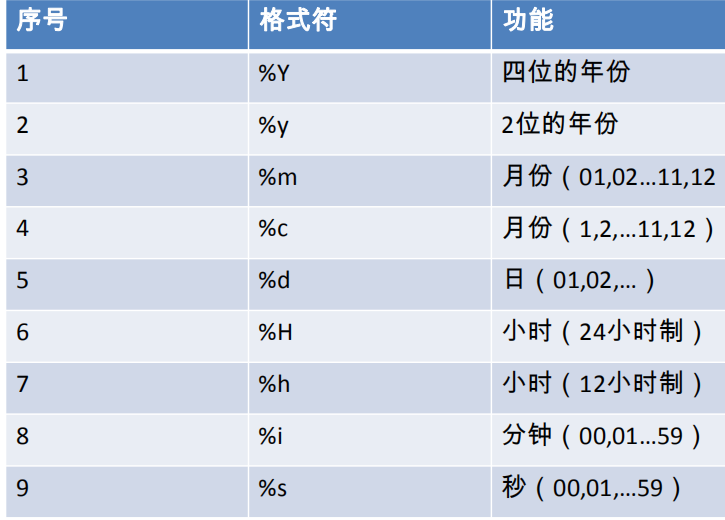
补充:日期格式
流程控制函数
#if函数 SELECT IF(10>5, '大', '小'); #case函数 #作用1,switch case效果 SELECT salary, `department_id`, CASE `department_id` WHEN 30 THEN salary*1.1 WHEN 40 THEN salary*1.2 WHEN 50 THEN salary*1.3 ELSE salary END AS 新工资 FROM `employees`; #作用2,类似多重if SELECT salary, CASE WHEN salary>20000 THEN 'A' WHEN salary>15000 THEN 'B' WHEN salary>10000 THEN 'C' ELSE 'D' END AS 工资级别 FROM `employees`;
分组函数
/* 用于统计实用,也称为聚合函数 sum求和,avg平均值,max最大值,min最小值,count计算个数 */ #简单使用 SELECT SUM(salary) FROM `employees`; #参数支持类型:sum,avg数值类型;max,min,count任何类型 #都忽略null #可以和distinct搭配使用 SELECT SUM(DISTINCT salary) FROM `employees`; #count使用 SELECT COUNT(*) FROM `employees`;#查询总行数 SELECT COUNT(1) FROM `employees`;#添加一列全是1后查询此列1个数也就是查询总行数 #和分组函数一同查询字段有限制,要求是group by后字段
分组查询
/*
语法:
select 分组函数,列(要求出现在group by的后面)
from 表
【where 筛选条件】
group by 分组的列表
【order by 子句】
【having 复杂条件】
*/
# 简单分组
#查询每个工种最高工资
SELECT MAX(salary), job_id
FROM `employees`
GROUP BY `job_id`;
#查询每个位置上的部门个数
SELECT COUNT(*), `location_id`
FROM `departments`
GROUP BY `location_id`;
# 添加筛选条件
#查询邮箱中包含字符a的每个部门的平均工资
SELECT AVG(salary), `department_id`
FROM `employees`
WHERE email LIKE ('%a%')
GROUP BY `department_id`;
# 添加复杂筛选条件
#查询哪个部门员工个数大于2
SELECT COUNT(*),`department_id`
FROM `employees`
GROUP BY `department_id`
HAVING COUNT(*)>2;
# 按表达式分组
#按员工姓名的长度分组,查看每一组员工个数,筛选员工个数大于5的
SELECT COUNT(*),LENGTH(`last_name`)
FROM `employees`
GROUP BY LENGTH(`last_name`)
HAVING COUNT(*)>5;
# 按多个字段分组
#查询每个部门每个工种的员工平均工资
SELECT AVG(salary), `department_id`, `job_id`
FROM `employees`
GROUP BY `department_id`, `job_id`