1 IO流相关概念
1.1 什么是IO流?
IO流用来处理设备之间的数据传输
Java对数据的操作是通过流的方式
Java用于操作流的类都在IO包中
1.2 IO流分类
按流向来分
输入流InputStream Reader(读取数据)
输出流OutStream Writer(写数据)
按操作类型分
字节流 : 字节流可以操作任何数据,因为在计算机中任何数据都是以字节的形式存储的
字符流 : 字符流只能操作纯字符数据
1.3 Java中常用IO流的类
字节流的抽象父类:
InputStream 输入流
OutputStream 输出流
字符流的抽象父类:
Reader 字符读取流
Writer 字符写入流
2 InputStream
InputStream是抽象类,表示字节输入流,用于读数据。
直接已知子类:
AudioInputStream
ByteArrayInputStream
FileInputStream(学习文件输入流)
FilterInputStream
ObjectInputStream
PipedInputStream
SequenceInputStream
StringBufferInputStream
InputStream之FileInputStream

概述:
FileInputStream 从文件系统中的某个文件中获得输入字节。FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader
构造方法
FileInputStream(File file)
FileInputStream(String name)
方法
Int read() 读取一个字节 会一个字节一个字节的读取,并将byte 转成 int 返回
Int read(byte[]) 读取一个字节数组 返回字节数组中元素个数
read()方法读取的是一个字节,为什么返回是int,而不是byte ?
假如使用FileInputStream读取图片的时候
* 图片中间有一段数据刚好是 11111111,如果用byte接收,这八个一表示的-1
* java程序如果读取的是-1,后面的数据就不读取
* 如果把8个1转成int,那就是00000000 00000000 00000000 11111111,这个表示255,就不是-1,归避后面数据没有读取问题
为什么11111111是表示-1?
* 因为计算机是以补码的方式计算
* 补码: 11111111 (-1)
* 反码: 11111110
* 原码: 10000001
3OutputStream
概述
OutputStream译为输出流
OutputStream是一个抽象类,它用于往文件里写入内容
子类

OutputStream之FileOutputStream
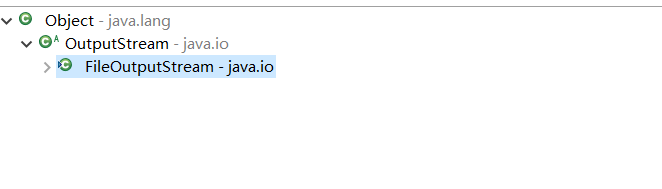
概述
表示文件输出流,用于往文件写内容
构造方法
FileOutputStream(String name)
FileOutputStream(File file)
方法
write(int b);//每次写一个字节
write(byte[] b) ;//一次写多个字节
多种读写数据操作
一个字节一个字节读写数据
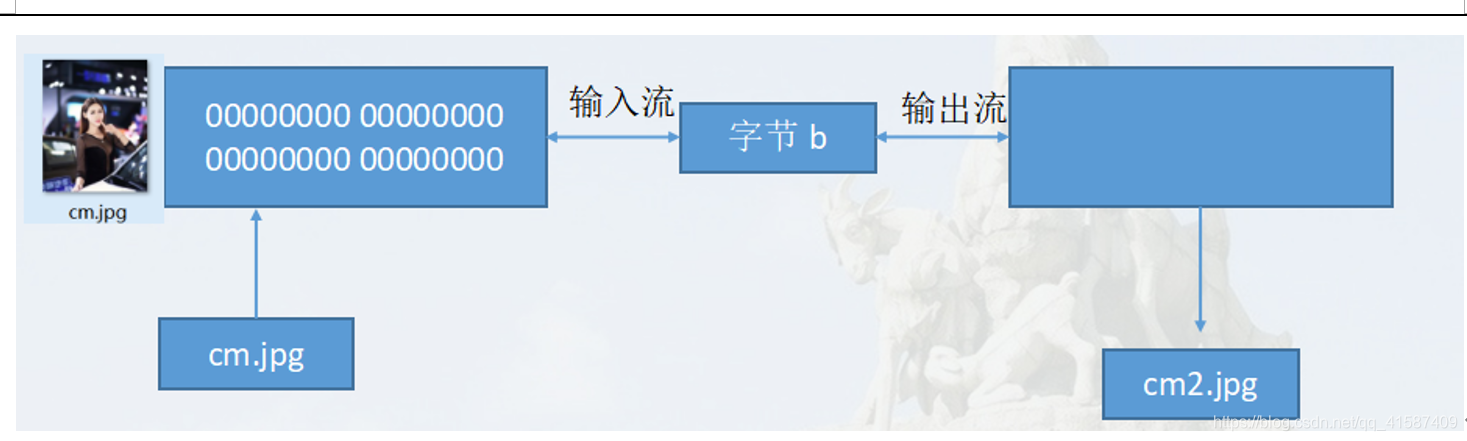 这样性能太低了。
这样性能太低了。
// 会从项目目录下找
// InputStream inputStream = new FileInputStream("a.txt");
// 会从项目目录下找
final File file = new File("a.txt");
final File file2 = new File("b.txt");
final InputStream inputStream = new FileInputStream(file);
// 如果文件不存在会自动创建
final OutputStream outputStream = new FileOutputStream(file2);
// read()方法会一个字节一个字节的读取,并将byte 转成 int 返回
// 如果返回-1 则说明文件读取完了
// System.out.println(inputStream.read());
// System.out.println(inputStream.read());
// System.out.println(inputStream.read());
// System.out.println(inputStream.read());
int length = 0;
int i = 0;// 读取文件次数
// 只要length不是-1 就继续从文件中读取数据 length:读取到的数据
while ((length = inputStream.read()) != -1) {
i++;
// 一字节一字节写入
outputStream.write(length);
}
System.out.println("文件读取次数: " + i);
// 释放资源
inputStream.close();
outputStream.close();
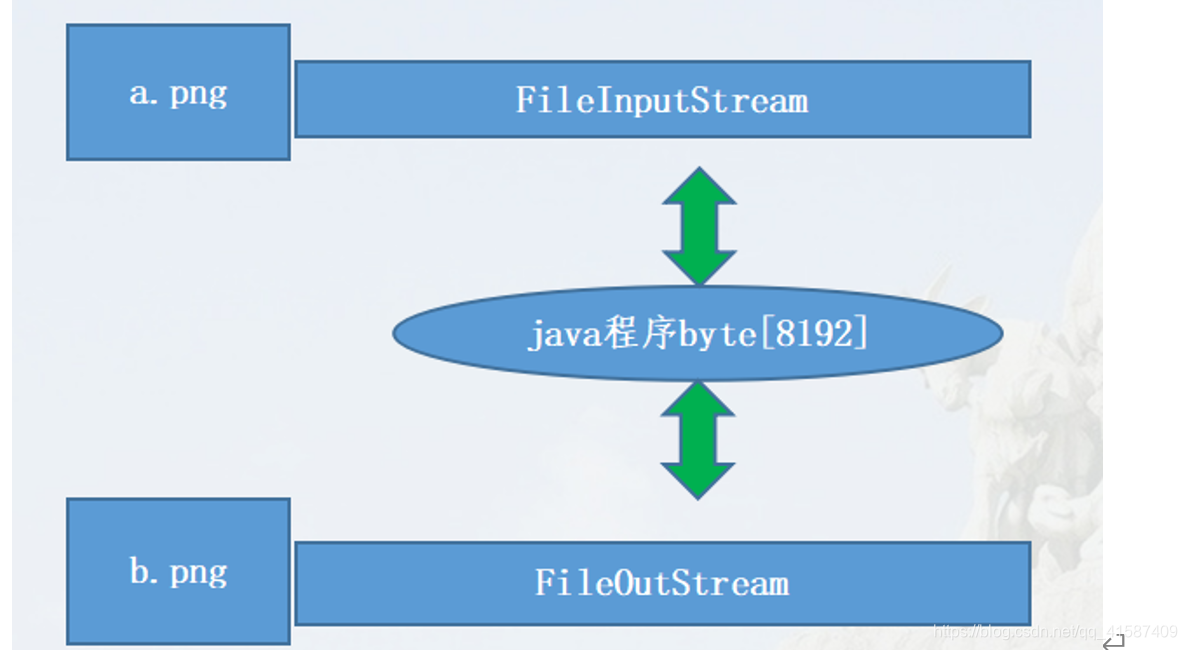
自己声明一个缓冲区来读写数据
// 会从项目目录下找
// InputStream inputStream = new FileInputStream("a.txt");
// 会从项目目录下找
final File file = new File("a.jpg");
final File file2 = new File("b.jpg");
final InputStream inputStream = new FileInputStream(file);
// 如果文件不存在会自动创建
final OutputStream outputStream = new FileOutputStream(file2);
// 如果返回-1 则说明文件读取完了
// 声明一个缓冲区
byte[] buf = new byte[1024 * 8];
int length = 0;
int i = 0;// 读取文件次数
// 只要length不是-1 就继续从文件中读取数据 length:字节数组中元素个数
while ((length = inputStream.read(buf)) != -1) {
//
i++;
System.out.println(length);
// 写入数据 注意一下:这里用的数组和读取数据的数组是同一数组
// 写入时 要用write(buf,0,length)
// 否则数组其他数据也会被写入
outputStream.write(buf, 0, length);
}
System.out.println("文件读取次数: " + i);
// 释放资源
inputStream.close();
outputStream.close();
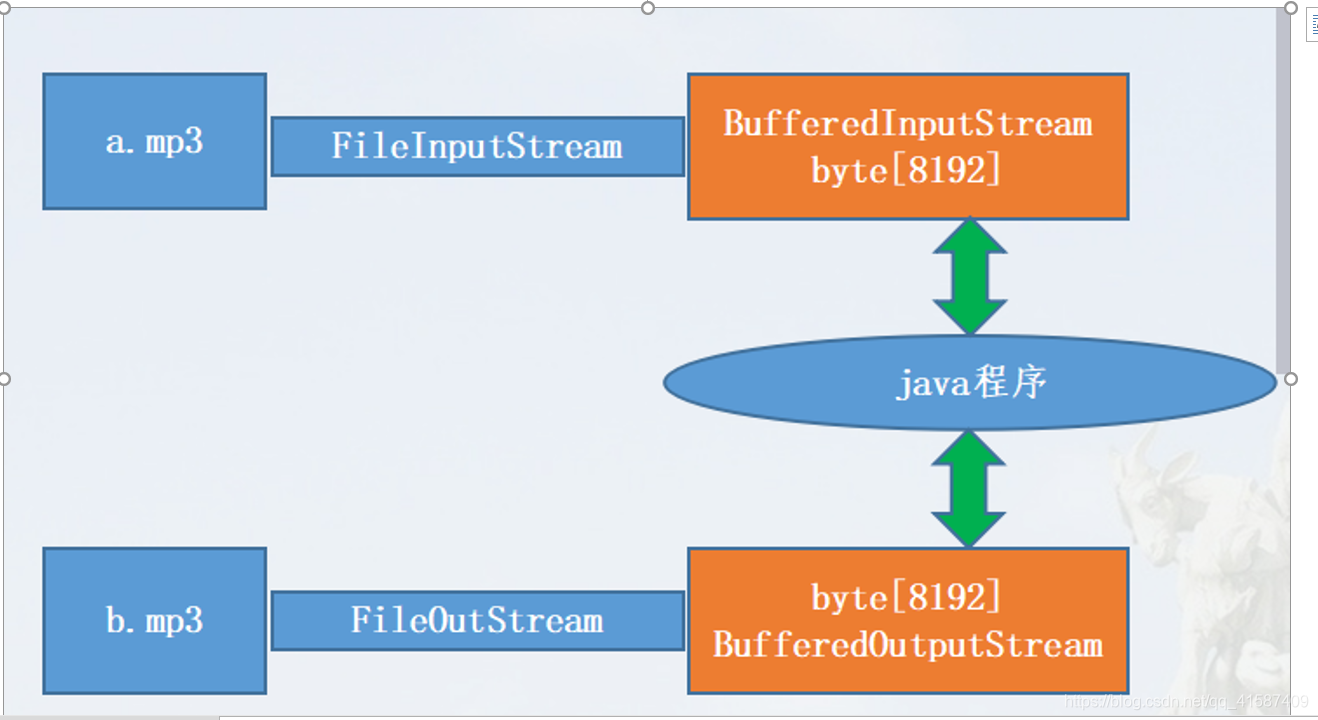
使用官方带缓冲的字节输入输出流来读写数据
BufferedInputStream:
BufferedInputStream内置了一个缓冲区(数组)
当使用BufferedInputStream读取一个字节时,BufferedInputStream会一次性从文件中读取8192个(8Kb), 存在缓冲区中,直到缓冲区装满了, 才重新从文件中读取下一个8192个字节数组
BufferedOutputStream:
BufferedOutputStream也内置了一个缓冲区(数组)
向流中写入字节时, 不会直接写到文件, 先写到缓冲区中直到缓冲区写满, BufferedOutputStream才会把缓冲区中的数据一次性写到文件里
// 会从项目目录下找
// InputStream inputStream = new FileInputStream("a.txt");
// 会从项目目录下找
final File file = new File("C:\\Users\\Administrator\\Desktop\\ghsy.mp3");
final File file2 = new File("C:\\Users\\Administrator\\Desktop\\a\\ghsy.mp3");
final InputStream inputStream = new FileInputStream(file);
// 如果文件不存在会自动创建
final OutputStream outputStream = new FileOutputStream(file2);
BufferedInputStream bis = new BufferedInputStream(inputStream);
BufferedOutputStream bos = new BufferedOutputStream(outputStream);
int length;
// 只要length不是-1 就继续从文件中读取数据 length:字节数组中元素个数
// bis.read()方法,内部会读8kb数据
while ((length = bis.read()) != -1) {
// 内部会写8kb数据
bos.write(length);
}
// 释放资源
bis.close();
bos.close();
带Buffered的流和自己写的字节数组缓冲对比
自己写数组会略胜一筹,因为读和写操作的是同一个数组,而Buffered操作的是两个数组
Buffered流处理:
 自己缓冲处理:
自己缓冲处理:
BufferedOutputStream的flush和close方法的区别
flush()方法
1.用来刷新缓冲区的,把内部buf[] 变量的数据写入文件,刷新后可以再次写入数据
close()方法
1.用来关闭流释放资源的
2.如果是带缓冲区的流对象的close()方法,不但会关闭流,还会再关闭流之前刷新缓冲区,关闭后不能再写出
字节流中文乱码问题
在utf-8 编码中 中文占三个字节 英文占一个字节
在gbk 编码中 中文占两个字节
数据出现中文乱码:在两数据流都相同时 出现乱码是编码机制导致的
如果不同 则可能是数据流缺失导致的
ps:经测试 OutputStream outputStream = new FileOutputStream(file)
在一开始是先确定是存在该文件 如果不存在就会创建文件
如果存在就会将文件变成空
不同jdk版本下流的标准处理异常方式
jdk1.6下
读写的操作放在try里面
关闭流的操作放finally
InputStream inputStream = new FileInputStream("a.txt");
OutputStream outputStream = new FileOutputStream("b.txt");
try {
int length;
while ((length = inputStream.read()) != -1) {
outputStream.write(length);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// //关闭资源(一)
// try {
// inputStream.close();
// } catch (Exception e) {
// e.printStackTrace();
// }
//
// try {
// outputStream.close();
// } catch (Exception e) {
// e.printStackTrace();
// }
// 关闭资源(二)
try {
inputStream.close();
} finally {
outputStream.close();
}
}
jdk1.7下
1.把流对象的声明放在try() 括号里面
2.操作流【读写数据】的代码放在花括号里面
3.这样写不用关闭流,java自动关闭流
4.在try的括号里的对象,必须是实现AutoCloseable的接口
// 1.把流对象的声明放在try() 括号里面
// 2.操作流【读写数据】的代码放在花括号里面
// 3.这样写不用关闭流,java自动关闭流
// 4.在try的括号里的对象,必须是实现AutoCloseable的接口
try (InputStream inputStream = new FileInputStream("a.txt");
OutputStream outputStream = new FileOutputStream("c.txt");) {
int length;
while ((length = inputStream.read()) != -1) {
outputStream.write(length);
}
} catch (Exception e) {
e.printStackTrace();
}
