1.结构体
#include <stdio.h>
#include<string.h>
#include<stdlib.h>
struct student
{
char name[100];
int age;
};//注意这里有;
int main()
{
struct student st;//定义了一个student类型的结构体变量,名字叫st
st.age=20;
strcpy(st.name,"刘某");
printf("name=%s,age=%d\n",st.name,st.age);
return 0;
}
初始化方法
#include <stdio.h>
#include<string.h>
#include<stdlib.h>
struct student
{
char name[100];
int age;
};//注意这里有;
int main()
{
//struct student st={"王某",50};//定义结构变量的时候,同时初始化成员变量的值,很像数组
//struct student st={"王某"};//定义结构变量的时候,同时初始化成员变量的值,如果没输入,默认零
//struct student st={0};//定义结构变量的时候,同时初始化成员变量的值,字符串空,年龄是0
//struct student st={.age=30, .name="孙某"};//定义结构变量的时候,同时初始化成员变量的值,可以用这种方式打乱顺序
printf("name=%s,age=%d\n",st.name,st.age);
return 0;
}1.1结构体的对齐
一个结构体变量成员总是以最大的那个元素作为对齐单位
#include <stdio.h>
#include<string.h>
#include<stdlib.h>
struct A
{
char a1;
char a2;//如果不考虑a3,增加一个成员,下面输出a占用的内存增加一个字节
int a3;//这里a占用的内存为八字节,因为要以int对齐,总是以int为单位来变化
};//注意这里有;
struct B
{
char a1;
short a2;
char a4;//在这里放char的时候,short已经把内存占了,没地方放char了,所以结构体B占用总为12个字节。
int a3;//上边两个加起来没一个int大,所以,为八个字节,但是不知道short的位置
};
int main()
struct A a;
struct B b={1,2,3};
printf("%u\n",sizeof(a));//输出a占用的内存为一个字节
printf("%p\n",&a);//在这里做一个断点,然后单步调试,选择调试,内存,查看内存内容
return 0;图形说明上述程序:
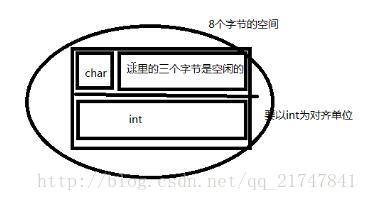
对于structB
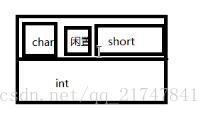
加了char a4的情况为:
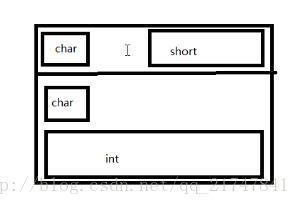
此时,非常简单的优化方法是把a4和a3换个位置,减少内存浪费。
#include <stdio.h>
#include<string.h>
#include<stdlib.h>
struct D
{
char a[10];
int b;//此时输出d的占用内存大小为16,可以肯定它没有按照char a[10]对齐,否则应该是十的倍数,其实它还是按照int对齐的,是4的倍数,如果结构体成员出现数组,那么是以数组的具体每个成员作为对齐标准。
//如果int b改成char b,那么这个结构体中的成员都是一种类型,那么这个结构变量在内存中就基本和一个数组类似。可以用char *s=&d;结构体本身是个变量,不能直接当数组名用,所以要取地址。甚至可以写成s[0]=1;s[10]=2;
};//注意这里有;
struct E
{
char a1;
short a2;//有一个字节被浪费了
int a3;
};
struct F
{
char a1;
short a2;
int a3;
short a4;
char a5;//此时,a1a2a3a4的内存位置都已知,a5是处于紧挨着short后面的下一个地址还是填充最后一个字节呢?结果是紧挨着的那个地址,最后一个字节是空的。
};
int main()
{
struct D d;
printf("%u\n",sizeof(d));
return 0;
printf("%p,%p\n",&d,d.a);//d.a是一个数组名,这里要弄清楚,这俩地址是一样的,结构体变量的地址,就是这个结构体首元素的地址
struct E e={1,2,3};
s=&e;
s[1]=10;//可以通过指针,变相的访问那个被浪费的字节。
}1.2结构体的位字段
#include<stdio.h>
struct A
{
char a : 2;//a只有两个比特(一个char是八个)
char b : 4;//b是四个比特
};
struct B
{
unsigned char a1 : 1;
unsigned char a2 : 1;
unsigned char a3 : 1;
unsigned char a4 : 1;
unsigned char a5 : 1;
unsigned char a6 : 1;
unsigned char a7 : 1;
unsigned char a8 : 1;//LED灯控制,按位控制,分别给每一位赋值0、1,此时b占用内存为一字节
};
struct C
{
char a1 : 1;
int a2 : 1;//虽然只占了两个比特,但是这个结构占8个字节
};
int main()
{
struct A a;
a.a=5;//此时输出的a.a为1,因为只有两位
printf("%x\n",a.a)
return 0;
}1.3结构体数组
#include <stdio.h>
#include <string.h>
#pragma warning (disable:4996)
struct student
{
char name [20];
unsigned char age;
int sex;//cpu处理int的效率是最高的,int比char要多占内存而已
};
int main()
{ int i;
//struct student st[3]={{"abc",30,1}{"cxe",20,0}{"asfka",50,0}};//定义一个结构体数组,有三个成员,每个成员都是struct student
struct student st[]={{}{}{}{}{}};//对于这种情况,要使用sizeof(st)/sizeof(st[0])来构造循环
//for(i=0;i<3;i++)
//{
//scanf("%s\n",st[i].name);
//scanf("%d\n",&st[i].age);
//scanf("%d\n",&st[i].sex);
//}
for(i=0;i<3;i++)
printf("%s,%d,%d\n",st[i].name,st[i].age,st[i].sex);
}那么对于一个结构数组,如何对其按年龄排序呢?
这里假设有五个成员的结构数组
void swap_str (char *a,char *b)
{
char temp[20]={0};
strcpy(tmp,a);
strcpy(a,b);
strcpy(b,tmp)
}
void swap_int (int *a,int *b)
{
int temp=*a;
*a=*b;
*b=temp
}
for(i=0;i<5;i++){
for (j=1;j<5-i;j++){
if(st[j].age<st[j-1].age){
swap_str(st[j].name,st[j-1].name);
swap_int(st[j].age,st[j-1].age);
swap_str(st[j].sex,st[j-1].sex);}}}
1.4结构体嵌套
#include <stdio.h>
struct A
{
char a1;
};
struct B
{
struct A a;
int a1;
}
//struct D
{};//这种不行,至少要有一个成员,这个语法在C++是合法的。
struct A1
{
int a1;
char a2;
}
struct A2
{
struct A1 a1;//这里是一个结构体的嵌套
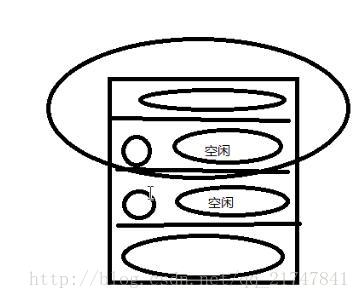
char a2;//上面结构体变量作为一个整体存在,不可能把a2补到a1的后面去,所以a2一定是一个单独的对齐单位。具体在内存中的分布见下图。
int a3;
}
int main()
{
struct B b;
printf("%u\n",sizeof(b));//和一个结构体类似,以int对齐,把A当一个char来用了
b.a.a1=0;//通过这种方法使用A的成员
return 0;
}
注意结构体变量的赋值
简单的用伪代码表示:
struct student st1={"abc",30};
struct student st2;
st2=st1;//可以通过这种方式给结构体变量赋值,赋值就是内存拷贝
//mencpy(&st2,&st1,sizeof(st1));//由于赋值是内存拷贝,所以可以用这个1.5指向结构体的指针
->操作符
(*p).a等同于p->a
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#pragma warning(disable:4996)
struct student
{
char name[20];
int age;
};
int main()
{
struct student st1 = {"abc", 30};
struct student st2;
st2 = st1;//结构体变量的赋值,赋值就是内存拷贝
//memcpy(&st2, &st1, sizeof(st1));
printf("%s, %d\n", st2.name, st2.age);
struct student *p;
p = &st1;
//strcpy((*p).name, "hello");//加括号是因为.的优先级比*高,所以要加括号
//(*p).age = 50;
strcpy(p->name, "hello");
p->age = 50;
printf("%s, %d\n", st1.name, st1.age);
return 0;
}
结构体指针和数组的关系
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#pragma warning(disable:4996)
struct student
{
char name[20];
int age;
};
struct man
{
char *name;
int age;
};
int main()
{
struct student st[3]={{"张三",34}{"李四",}{"王二",}}
struct student *p=st;
p->age=100;//修改的是张三的年龄
p++;
p->age=50;//此时p不再指向张三了,所以输出会错,所以要p--;
p--;
int i;
for (i=0;i<3;i++)
{
printf("%s,%d",p[i].name,p[i].age)
}
}结构中的数组成员和指针成员
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#pragma warning(disable:4996)
struct student
{
char name[20];
int age;
};
struct man
{
char *name;
int age;
};
int main()
{
struct student st = { 0 };
struct student st1 = { 0 };
strcpy(st.name, "刘德华");
st.age = 30;
st1 = st;//结构体变量赋值
printf("%s, %d\n", st1.name, st1.age);
struct man m = { 0 };//m里面的name是什么?是空指针,指向一个无效地址,那么后面的strcpy无法操作
struct man m1 = { 0 };
m.name = calloc(20, sizeof(char));//用堆内存,避免上面的问题
strcpy(m.name, "张学友");
m.age = 40;
//m1 = m;//浅拷贝
//free(m.name);//此时后面输出的m1就会出现乱码,原因见下图
m1.name = calloc(20, sizeof(char));
memcpy(m1.name, m.name, 20);//深拷贝
m1.age = m.age;
free(m.name);
printf("%s, %d\n", m1.name, m1.age);
free(m1.name);
return 0;
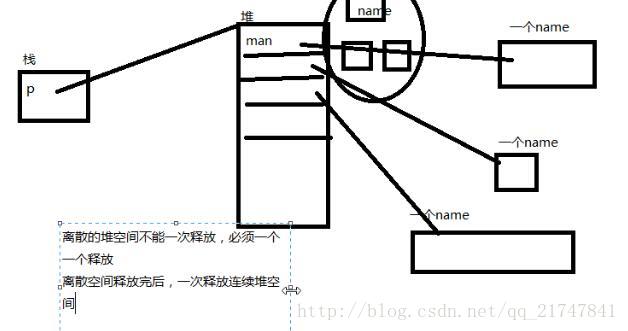
}赋值后,都指向了同一个堆空间,但是堆空间被free了,m1就指向一个无效的空间了,m1就成为了野指针。
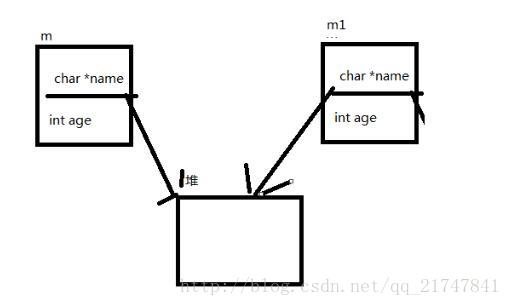
堆中创建结构体变量
```
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#pragma warning(disable:4996)
struct student
{
char name[20];
int age;
};
struct man
{
char *name;
int age;
};
int main()
{
struct student st;//请问st.name在堆里面还是在栈里面(在栈里)
struct student *p = malloc(sizeof(struct student));//请问p->name在堆里面,还是在栈里面(在堆里)
free(p);
struct man *p1 = malloc(sizeof(struct man));//申请一个堆空间,p1->name在哪里?在堆里,但是是一个野指针,也就是这个堆里第一个成员是个char* 是个野指针
p1->name = malloc(20);
strcpy(p1->name, "苍老师");
p1->age = 20;
free(p1->name);
free(p1);
//free(p1->name);//name在堆中已经被释放了
return 0;
}函数的参数为结构体变量
#include<stdio.h>
#include<string.h>
struct student
{
char name[20];
int age;
};
void print_student(struct student st)//在调用函数的时候,在栈里有个浅拷贝的过程st=s
{
printf("%s,%d\n",st.name,st.age);
}
void print_student_new(struct student *st)//st=&s;地址编号赋值,其效率远远高于上一个操作。要保护的话,可以加const struct
{
printf("%s,%d\n",st->name,st->age);
}
void set_student1(struct student *st)
{
strcpy(st->name,"123456");
st->age=0;
}
void set_student(struct student st)
{
strcpy(st.name,"123456");
st.age=0;
}
int main ()
{
struct student s={"abc",40};
//set_student(&s);//s的值在函数调用后不会改变,st是形参
set_student1;//这样才会改变
print_student(&s);
return 0;
}2.联合体
联合union是一个能在同一个存储空间存储不同类型数据的类型。
联合体所占的内存长度等于其最长成员的长度,也有叫做共用体。
联合体虽然可以有多个成员,但同一时间只能存放其中一种。
#include<stdio>
union A
{
int a1;
short a2;
char a3;
char *p;
};
int main()
{
union A a;
a.a1=1;
printf("%u\n",sizeof(a));//此时输出4
a.a3=10;
a.a1=0;
printf("%d\n",a.a3);//此时输出0,也就是三个成员互相影响,他们共用一个内存,输出a1,a2,a3的地址是相同的。
a.a1=0x12345678;
a.a3=0;//此时输出a1的值为0x12345600因为a3只占一个字节,只能影响a1的最后一个字节。
a.a2=0;//此时输出0x12340000
a.p=malloc(10);//假设这块堆内存的编号为0x12345
a.a1=0;//此时导致p的值也成了0了。内存泄露了
free(a.p);
return 0;
}3.枚举
可以使用枚举(enumerated type)声明代表整数常量的符号名称,关键字enum创建一个新的枚举类型。
实际上,enum常量是int类型的。
增加代码可读性。
#include<stdio>
struct man
{
char *name;
int age;
int sex;
};
enum spectrum {red,yellow,green,blue,white,black};
//enum spectrum {red=100,yellow,green,blue,white,black};//可以改变默认值,此时为100,101,102...
//enum spectrum {red=100,yellow=10,green,blue,white,black};//后面顺着10顺延。
enum sex{man,woman};
int main()
{
struct man m;
strcpy(m.name,"tom");
m.age=20;
//enum sex s;
//s=man;
//m.sex=man;
m.sex=man;在c语言中可以直接这样用,因为man women是整形的常量,常量不能取地址。
int *p=&red;//错误,和下面的100一样,100是系统内由CPU产生的立即数
int *p=100;
int a=100;//CPU生成一个立即数100,在栈中分配4个BYTE的空间,然后把这个空间设置为100。
const char *p="hello";//"hello"在内存的常量区里面
//red=5;//错误。常量不能做左值。
//m.sex=1;//可能会导致忘记0/1的意义,可以用#define MAN 1 那么可以改成m.sex=MAN;但是如果量不止0/1就会很麻烦,就需要用到枚举。
enum spectrum color;
color=red;
}4 typedef
typedef是一种高级数据特性,它能使某一类型创建自己的名字
1与#define不同,typedef仅限于数据类型,而不是能是表达式或具体的值
2typedef是编译器处理的,而不是预编译指令
3typedef比#define更灵活
直接看typedef好像没什么用处,使用BYTE定义一个unsigned char。使用typedef可以增加程序的可移植性。
#include<stdio.h>
typedef unsigned char BYTE;//多了一种数据类型叫BYTE
struct man
{
char name [20];
//unsigned char age;
BYTE age;
};
typedef struct man M;//M就类似于int,就是一种数据类型了。
int main()
{
//struct man m;
M m;
m.age=20;
BYTE a=0;
return 0;
}假设一种情况,定义了许多short
short a1;
short a2;
short a3;
short a4;
short a5;
short a6;
假如需要把short改成int就很麻烦。
那么可以用 typedef short SHORT 增加程序的可维护性
另外,微软常用的做法是用typedef定义所有的类型,这样的话,如果不同的语言之间可以进行移植。
例如:
#define UNICODE
#ifdef UNICODE//是否define了UNICODE ,是宽码操作系统,在宽码操作系统内部处理字符串的时候一般用wchar_t
typeof wchar_t TCHAR;
#else
typeof char TCHAR;
#endif5.习题
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
struct man
{
//char name[20];//不好确定名字长度。通过堆解决此问题
char *name;
int age;
int classid;
};
int main()
{
//struct man *p=calloc(10,sizeof(struct man));//在堆中分配了10个man,如果输入的数目也不确定,该如何修改呢?
struct man *p=NULL;
int i = 1;
//for (i=0;i<10;i++)//把这个改成while
while(1)
{
printf("please input name:");
char tmp[1024]={0};
//如果用户的名字等于exit,我们就退出循环
int len=strlen(tmp);
if(strcmp(tmp,"exit")==0);
break;
p=realloc(p,sizeof(struct man)*i);
p[i-1].name=malloc(len+1);
strcpy(p[i-1].name,tmp);
printf("please input age");
scanf("%d",&p[i-1].age);
printf("please input classid");
scanf("%d",&p[i-1].classid);
i++;
}
int a ;
for (a=0;a<i;a++)
{
printf("%s,%d,%d\n",p[a].name,p[a].age,p[a].classid);
}
for (a=0;a<i;a++)
{
free(p[a].name);//分别释放离散堆空间
}
free(p);//释放堆中连续的空间,就是堆中的数组
return 0;
}这种用指针的方法相对于数组的优点在于,直接在数组中添加删除元素代价非常大,而指针可以非常迅速的处理。