Hadoop的官方案例都在mapreduce.jar文件夹中,提供了mapreduce的基本功能,可用于计算,eg:pi值,计算文档中的字数等 官方案例都在 hadoop-mapreduce-examples-2.7.3.jar 这个jar包中。
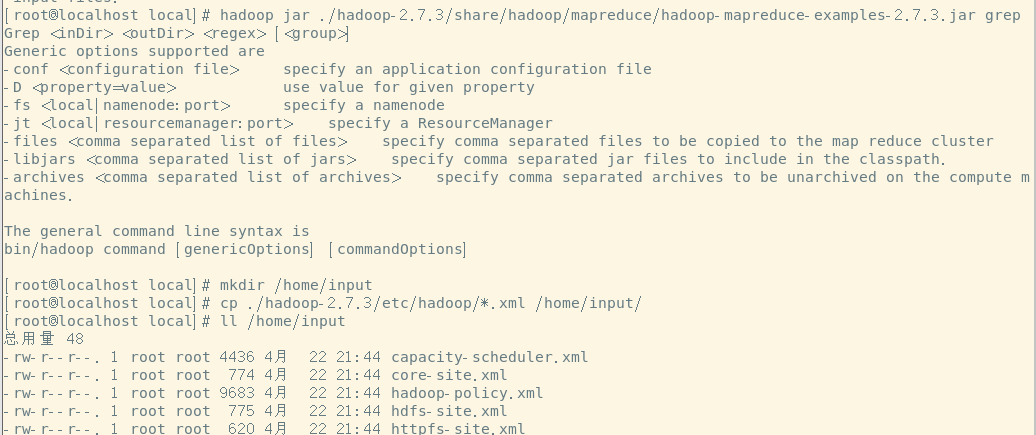
命令:hadoop jar ./hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar

运行grep案例(参考ApatchHadoop官网关于grep的案例的运行 grep:值得是文件内字符串查找,即在一堆文字中查找与正则匹配的单词出现的次数)
命令:hadoop jar ./hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep
Grep <inDir> <outDir> <regex> [<group>] //grep 输入路径 输出路径 正则表达式 【可选:分组】
在home目录下中创建input目录 命令:mkdir /home/input
拷贝etc/hadoop目录底下所有的.xml配置文件到刚才创建的input目录中 命令:cp ./hadoop-2.7.1/etc/hadoop/*.xml /home/input/
查看input目录:有多个后缀为.xml的配置文件 命令:ll /home/input
使用hadoop jar命令执行本次任务
tips:grep后/home/input是输入路径,/home/output是输出路径,'dfs[a-z.]+'是正则表达式
命令:hadoop jar ./hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-
examples-2.7.3.jar grep /home/input /home/output 'dfs[a-z,]+

查看home目录底下多了个output目录 命令:ls /home
查看output文件内容 命令:ll /home/output

查看运行结果 命令:cat /home/output/part-r-00000

tips:
1,output目录不能自己提前创建,否则会出错。这是为了保证目录不掺杂其他结果,output应该是hadoop新自动
创建的文件。
2,‘dfs[a-z,]+’指的是grep的正则匹配。即把刚才input目录中所有.xml文档都过滤了一遍找到以dfs开头的单词
有多少个。在这里dfsadmin出现了一次。
3,运行该案例成功则说明hadoop安装成功
运行wordcount案例
wordcount:单词统计。即在一堆文本文件中统计每个单词出现的次数。
命令: hadoop jar ./hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-



examples-2.7.1.jar wordcount
在home目录中创建input2目录 命令:[root@localhost local]# mkdir /home/input2
进入到刚刚创建的目录中 命令:[root@localhost local]# cd /home/input2
在其中创建一个wordcount.txt文件 命令:[root@localhost intput2]# vi wordcount.txt
然后在txt文件中随便敲一些单词。
然后回到hadoop目录下 命令:[root@localhost input2]# cd /usr/local/hadoop-2.7.3/
运行wordcount案例 命令:[root@localhost hadoop-2.7.3]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-
2.7.3jar wordcount /home/intput2/ /home/output2
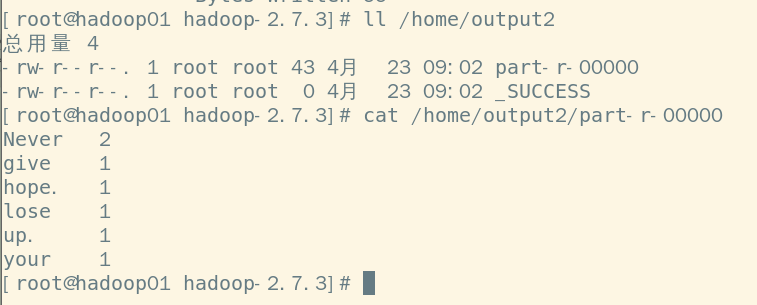
查看自动创建的output2目录 命令:[root@localhost hadoop-2.7.3]# ll /home/output2
查看结果可以看到txt文件中每个单词出现的次数 命令:[root@localhost hadoop-2.7.3]# cat /home/output2/part-r-00000