摘要
为了适应水下声呐传感器的数据,本文提出了一种最先进的视觉-惯性状态估计方案(OKVIS)的扩展。水下领域在可用视觉数据的质量方面提出了独特的挑战;因此,利用声呐数据增强外传感器能改善水下结构的重建。水下沉船、水下洞穴和水下巴士的实验结果证明了该方法的有效性。
1. INTRODUCTION
本文提出了一种基于水下结构的SLAM算法。这个算法结合双目摄像机的视觉数据、IMU的角速度和线性加速度数据以及机械扫描声纳传感器的距离数据。
在水下建筑物周围导航和绘图是非常具有挑战性的。除了水下视觉的限制,例如光线和颜色的衰减,洞穴环境还缺乏自然光照。使用机器人技术来绘制洞穴地图将会降低潜水员的认知负荷,目前潜水员需要手工测量。大多数用于定位的水下传感器都是基于声学传感器,如超短基线(USBL)和多普勒测速仪(DVL)。然而,这种传感器通常很昂贵,可能会干扰潜水员或环境。此外,这种传感器不能提供有关环境结构的信息。
近年来,许多基于视觉的状态估计算法被开发出来,这些算法使用单目、立体或多摄像机系统,适用于室内、室外和水下环境。这样的算法可以得到低成本的状态估计解决方案。当没有环路闭合时,基于视觉的系统可以被描述为增量式,称为视觉里程计(VO),以及完全基于视觉的SLAM系统。
在水下领域使用现有的基于视觉的状态估计方法并不容易,因为有很多挑战。特别是,模糊和光衰减导致的特征不像水面上那样清晰。因此,不同的基于视觉的状态估计方法会导致大量的异常值或完全的跟踪丢失。在这样一个具有挑战性的环境中,我们的初步工作是利用视觉数据和视频灯绘制水下洞穴,并且成功地重建了一个250米长的洞穴段。
在水下区域,视觉可以与IMU等传感器相结合,对姿态进行改进估计。开源方法OKVIS使用了vision和IMU,显示了优越的性能。本文提出了一种结合IMU数据、双目视觉数据和声纳测距数据的鲁棒状态估计算法,用于水下环境。
本文采用紧耦合非线性优化方法,将IMU测量值与立体视觉和声纳数据相结合;如图1所示,为保证VIO方法的良好性能,在摄像机内参和外参的标定过程中使用的水下传感器套件。

这篇论文的想法是,声呐数据虽然稀疏,但有更精确的比例尺估算,同时还提供了关于障碍物存在的可靠信息,而障碍物是视觉特征所在的地方。为了将声纳数据融合到传统的VIO框架中,我们提出了一种新的方法,即在每个声纳点周围使用一个视觉patch,并利用声纳点到patch的距离在姿态图中引入额外的约束。该方法假设基于视觉特征的patch足够小,且与声纳点近似共面。所得到的姿态图由视觉特征和声纳特征组成。此外,我们还采用了基于关键帧的方法来保持图的稀疏性,以实现实时优化。一个特殊的挑战来自于这样一个事实:由于传感器套件的配置,某个区域的声纳特征在一段时间后从视觉特征中被感知。实验数据收集自巴巴多斯岛的一艘人造沉船,佛罗里达州High Springs的洞穴;北卡罗莱纳州的一辆水下巴士。在所有的实验中,都使用了一个定制的传感器套件,该套件使用了一个双目摄像机、一个机械扫描剖面声纳和一个IMU。
2. 相关工作
与GPS的水下视觉里程计技术相比,水下洞穴环境的视觉测程是一个具有挑战性的问题,因为除了水下视觉约束(光和颜色衰减)之外,还缺乏自然光照明和动态障碍物。水下洞穴的测绘和定位工作不多。Gary等人使用激光雷达和有DVL、IMU和用于水下导航的深度传感器的DEPTHX 潜水器(DEPTHX, DEep Phreatic THermal eXplorer)收集的声纳数据,提出了水下洞穴的三维模型。大多数水下导航算法是基于声传感器的,如DVL、USBL和声纳。然而,在潜水时使用DVL、声纳和USBL收集数据是昂贵的,有时不适合在洞穴环境中。在这种情况下,基于视觉的状态估计可以被使用,因为它更便宜,更容易部署;然而,由于其基于增量运动的特性,它会随着时间累积漂移。Corke等人对水下定位的声学方法和视觉方法进行了比较,表明了在某些场景下使用视觉方法的可行性。
由于SLAM技术的高度非结构化特性,使得其在水下环境下的开发成为一项艰巨的任务。为了避免单目系统的尺度模糊,采用了立体相机对。Salvi等人实现了一种实时EKF-SLAM,采用稀疏分布的鲁棒特征选择和仅使用校准过的立体相机的6自由度姿态估计。Johnson等人提出了一种利用立体图像生成海底三维模型的思想。Beall等人通过对所有相机和特征子集进行BA,而不是使用传统的滤波技术,在大规模水下数据集上实现了精确的三维重建。在[25]中提出了一种用于自主水下航行器定位的立体SLAM框架——选择性SLAM (SSLAM)。
Hogue等人[31]采用stereo和IMU进行水下重建。[32]和[33]的VO分别采用Stereo和IMU。Saez等人提出了一种6自由度熵最小化SLAM,利用稠密的三维立体视觉系统和IMU来创建水下环境的稠密三维可视化地图;这是一个离线的方法。Shkurti等人提出了一种基于多状态约束卡尔曼滤波[35]的水下机器人状态估计算法,该算法结合了单目摄像机、IMU和压力传感器的信息。
也有大量的工作在水下使用低成本的声纳。Folkesson等人使用一种发光的阵列声纳进行实时特征跟踪。在[37]中描述了一个具有低成本声纳和导航传感器的特征捕获系统。
与其他工作不同的是,如下一节所述,我们提出的系统,在一个新的配置包括声纳以改善水下结构的重建,该配置以洞穴为重点。为此,我们提出了一种新的数据集成方法。
3. SYSTEM OVERVIEW
用于水下结构重建的传感器套件是一个定制的立体设备,如图2所示。当前的系统由以下组件组成:
•两个IDS UI-3251LE摄像头,
•IMAGENEX 831L声纳,
•微应变3DM-GX4-15 IMU,
•Bluerobotics Bar30压力传感器,
•英特尔NUC。
这两个摄像头通过类似arduino的电路板进行同步,它们能够以每秒15帧的速度拍摄,分辨率为1600×1200像素。
声纳能提供6米最大距离的数据,在360度以上的平面上扫描,角度分辨率0.9。一个6米的完整扫描大约需要4秒。注意,声纳为每个测量(波束)提供255个强度值,也就是说,在6米的最大范围内,6/255米是每个返回强度值之间的距离。显然,更高的响应意味着更有可能存在障碍。地板上的沉积物、多孔材料和多次反射导致强度的多模态分布。IMU在三个轴上以100赫兹的频率产生线性加速度和角速度。深度传感器产生15赫兹的深度测量。后者没有被使用,因为数据是从相同深度收集的。
硬件设计以洞穴测绘为目标应用。因此,声呐扫描平面与图像平面平行。起初,传感器套件是由潜水员携带的。作为未来的设计,我们计划将其安装在自主水下航行器(AUV)上。特别是所使用的硬件与Aqua AUV兼容,并通过在机器人上安装扫描声纳提供相同的感知能力。为了方便数据处理,ROS被用来记录数据。
4. PROPOSED METHOD

来自不同传感器的数据被组合起来产生一个传感器组件的状态的精确估计。更具体地,该方法通过最小化重投影误差、IMU误差项和声纳测距误差的联合估计来估计机器人R的状态
。摄像机、IMU、sonar、world的坐标系分别记为C、I、S、W。状态向量:
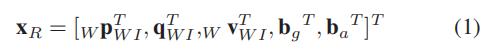
包含机器人的位置: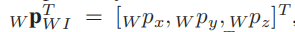
由四元数表示机器人姿态: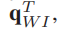
线速度: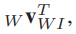
以上均以世界坐标表示
陀螺仪偏置
和加速度计偏置
。
当扰动发生在切空间时,误差状态向量在极小坐标系中定义:

表示状态向量的每个分量在切空间和极小坐标系之间转换的误差。
A. Cost Function
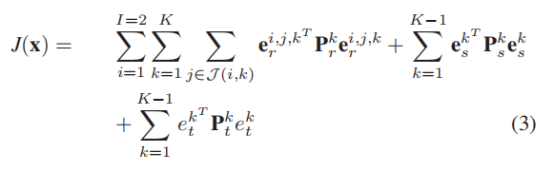
联合非线性优化损失函数J(x) 包括重投影误差
,IMU误差
,声呐误差
组成。是在okvis损失函数的基础上增加声呐误差。
分别表示第k帧的视觉路标、IMU和声纳测距的信息矩阵。
【补充】:OKVIS的损失函数:

B. Error Terms Formulation
重投影误差和IMU误差遵循OKVIS:
(1)重投影误差:
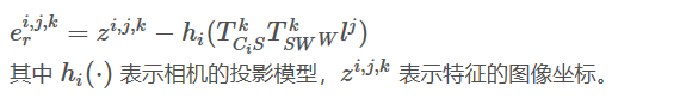
(2)IMU误差:
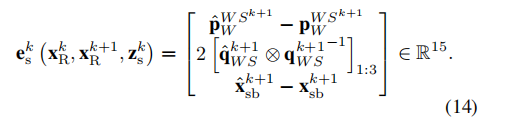
每个IMU误差项通过连续摄像机测量之间的IMU预积分将所有加速度计和陀螺仪测量合并,并表示基于先前状态和实际状态的预测之间的机器人姿态、速度和偏差误差。
在该系统中,声纳测量结果被用来修正机器人的姿态估计,以及优化来自视觉和声纳的路标。由于水下环境能见度低,在很难找到视觉特征的情况下,声纳为特征提供了准确的尺度。一个特别的挑战是视觉和声纳这两个传感器之间的时间位移。图4说明了问题的结构:在时间k时,立体相机检测到一些特征;声纳需要一段时间(直到k+i)通过这些视觉特征并获得相关测量。为了解决上述问题,将在声纳回波附近检测到的视觉特征组合在一起,并用于构建图像块patch。声纳和图像块patch之间的距离用作附加约束。

图像4:声纳测量值与立体相机特征之间的关系。在k时刻探测到的视觉特征,声纳在k + i时刻探测到(有延迟),i取决于传感器组移动的速度。
为了提高计算效率,只有在姿态图中加入新的相机帧时,才进行声纳距离校正。由于声纳比相机具有更快的测量速度,因此在给定的距离和头部位置下,仅使用距离机器人姿态最近的时间戳来计算声纳地标周围视觉地标的小块。算法1说明了在给定时刻k下的机器人位置 和声纳测量 的情况下,如何计算距离误差 。
声纳返回距离r和头部位置θ(声呐路标到声呐传感器的朝向),被用于通过世界坐标中的简单几何变换来获得每个声纳路标
:
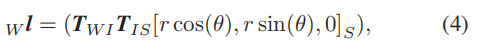
其中
分别是用于将声纳测量从声纳坐标转换为世界坐标的变换矩阵。更具体地说,T表示一个标准仿射变换矩阵(旋转和平移)。
表示从声呐坐标系转换到IMU坐标系,
表示从惯性(IMU)坐标系到世界坐标系的转换,因此,利用算法1的第2-9行进行声纳距离预测:

声纳测距误差:
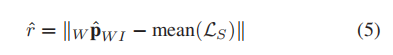
其中 是声纳路标周围的视觉路标子集。如上所述,计算距离误差背后的概念是,如果声纳探测到某一距离的任何障碍物,则更有可能将视觉特征定位在该障碍物的表面,因此声呐测量特征和视觉特征将在大约相同的距离。因此,误差项就是视觉特征估计与测量的距离之差。请注意,我们使用形心(平均值(LS))近似视觉patch,以滤除视觉地标上的噪声。
因此,声纳误差
可以看作是机器人状态
的函数,可以用正态条件概率密度函数
和条件协方差
来近似,随着新传感器测量值的整合而迭代更新:
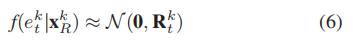
信息矩阵为:
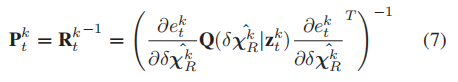
通过对机器人姿态的期望距离测量r (Eq.(5))进行微分,可以得到雅可比矩阵:
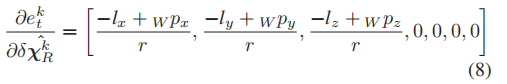
在非线性优化框架(Ceres[42])中加入估计误差项,其方法与IMU和立体声重投影误差类似。
V. EXPERIMENTS
该方法已经在许多具有挑战性的环境中进行了测试。下面给出了三个典型场景的实验结果。对于每个数据集,都提供了一个描述和所提出的状态估计方法的结果。此外,还简要讨论了在实地试验中遇到的挑战。
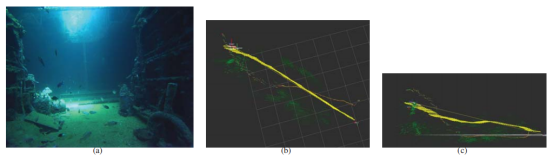
第一批数据集之一是在一艘人工沉船上收集的;参见图5(a)。声纳传感器的最初部署受到一种结构的影响,在这种结构中,数据以非常慢的速度收集,最大距离为一米。然而,即使有了这种配置,沉船的底部仍然是可见的,这意味着即使在结构不那么复杂的环境中,比如珊瑚礁区域,也可以使用传感器套件。图5(b)显示了轨道的俯视图以及声纳和视觉特征。图5©为侧视图,在图5(a)的左侧可以看到图5(a)背面的垂线。请注意,图5©显示的是相机轻微向上的轨迹,尽管图5(a)的图像帧显示的是水平的地板。沉船带着倾斜度停在海底,IMU通过计算重力矢量捕捉到了这一事实。
我们还从一个山洞里采集了一小段数据。这些镜头提供了来自水下洞穴环境的初步数据;参见图6 (a)。使用的视频光只在部分场景提供照明。图6(b)、图6©展示了轨迹的两个视图,以及视觉和声纳特征。重建显示了视觉路标和声纳点,让潜水员在周围游泳时对洞穴有了感觉。在这个实验中,声纳被配置在更高的速率和最大距离6米。然而,由于光线和环境的特点,现场照明不均匀,视觉特征稀疏。

最后,在一辆沉没的公共汽车的内部收集的数据;参见图7 (a)。由于水中有许多微粒,图像质量很差。俯视图如图7(b)所示,其中传感器进入并穿过公共汽车的轨迹是清晰的。图7©显示了相同结果的侧视图。声纳数据上的缝隙在巴士窗户所在的区域是可见的。

在所有的环境中,图像都含有大量的模糊,其模糊程度随着距离的增加而增加。此外,动态障碍,如鱼类,更重要的是漂浮粒子反射回来的高强度,存在于所有的数据集;请参见图8。
在这样具有挑战性的环境中,很难获得ground truth。但是,所经过的路线和距离与潜水员所经过的路线和距离很相似。此外,声纳路标被用来校正姿态估计,允许优化收敛和保持误差非常低。与仅使用立体图像和IMU测量的OKVIS相比,数据集中的所有结果都显示出更多的特征映射,例如,洞穴中的几个环,这表明水下结构的映射得到了改进。
VI. CONCLUSIONS
随着基于视觉的状态估计技术的成熟,越来越多的传感器被集成。我们引入了一种新的传感器,一种机械扫描声纳,它基于声学信息返回距离测量值。虽然我们工作的主要动机是绘制水下洞穴图,但这项技术在不同的环境中进行了测试,包括巴巴多斯清澈水域的沉船、卡罗莱纳湖的人工沉船和洞穴。提出了一种新的声纳点与视觉特征融合的方法,用于扩展全局非线性优化生成的位姿图。
在不同的实验中,很明显,为了基本的性能,需要在可视化数据中保持最低的可见性和清晰度;但是,所使用的数据降级到了用于测试VO或VIO方法的典型数据集中不常看到的程度。此外,在洞穴环境中使用强光时,需要仔细校准其位置,以免使相机饱和。此外,不同的表面导致了声波信号的不同反射特性;我们目前正在分析不同材料上的声纳数据,以提高质量。
未来的工作除了收集更多的数据外,还将包括在数据收集过程中使用强光视频获得的立体特征。Weidner等人的工作中介绍了洞穴环境中人工光引入的特征的鲁棒性。初步工作已经证明,即使是低水平的环境光也会抵消人工光的影响,使这种方法只能在洞穴内可行。此外,深度传感器的数据将被添加到提议的框架中,以考虑垂直运动。目前,所收集的大多数数据来自同一深度,因此减少了这种传感器的影响。此外,还将研究提高图像质量的技术。
多个传感器的集成除了可以提高重建的密度外,还可以提高估计的质量。水下考古和洞穴学将是众多领域的主要研究领域。由此产生的技术将集成到现有的auv和rov中,以提高它们的自主能力。
