自己学习总结一下,如有错误,不忘指正谢谢。
背景
本文可能用到的术语解释:
AF Assured Forwarding 确保转发
BE Best Effort 尽力转发
EF Expedited Forwarding 加速转发
CAR Committed Access Rate 约定访问速度
GTS Generic Traffic Shaping 通用流量整形
CBWFQ Class Based Weighted Fair Queuing 基于类的加权公平队列
DSCP Differentiated Services Codepoint 区分服务编码点
FIFO First in First out 先进先出
PQ Priority Queuing 优先队列
ToS Type of Service 服务类型
WFQ Weighted Fair Queuing 加权公平队列
WRED Weighted Random Early Detection 加权随机早期检测
- 网络的普及,业务的多样化,使互联网流量激增,产生网络拥塞,转发时延增加,严重时还会产生丢包,导致业务质量下降甚至不可用。所以,要在IP网络上开展这些实时性业务,就必须解决网络拥塞问题。
- 解决网络拥塞的最好的办法是增加网络的带宽。但从运营、维护的成本考虑,这是不现实的,最有效的解决方案就是应用一个“有保证”的策略对网络拥塞进行管理。
- QoS技术就是在这种背景下发展起来的。QoS是Quality of Service(服务质量)的简称,其目的是针对各种业务的不同需求,为其提供端到端的服务质量保证。
- QoS技术在当今的互联网中应用越来越多,其作用越来越重要。如果没有QoS技术,业务的服务质量就无法保证。

上述的分类和标记是实现差分服务的前提和基础;流量监管、流量整形、拥塞管理和拥塞避免从不同方面对网络流量及其分配的资源实施控制,是提供差分服务的具体体现。
四个QoS组件在网络设备上有着一定的处理顺序,如下所示:

业务原理
1、度量指标
带宽/吞吐量
带宽(bandwidth)也称为吞吐量(throughput),是指在一个固定的时间内(1秒),从网络一端流到另一端的最大数据位数,也可以理解为网络的两个节点之间特定数据流的平均速率。带宽的单位是比特/秒(bit/s,简写为bps)。
时延
时延(Latency)是指一个报文或分组从一个网络的一端传送到另一端所需要的时间。
延迟关注个体感受,吞吐衡量总体效率。
时延变化(抖动)
时延变化是指同一业务流中不同分组所呈现的时延不同。时延变化也称为抖动(Jitter)。抖动主要是由于业务流中相继分组的排队等候时间不同引起的,是对服务质量影响最大的一个问题。某些业务类型,特别是话音和视像等实时业务是极不容忍抖动的。分组到达时间的差异将在话音或视像中造成断续。
丢包率
少量的丢包(Loss)对业务的影响并不大,例如,在语音传输中,丢失一个比特或一个分组的信息,通话双方往往注意不到。在视像广播期间,丢失一个比特或一个分组可能造成在屏幕上瞬间的波形干扰,但视像很快恢复正常。即使用传输控制协议(TCP)传送数据也能处理少量的丢包,因为传输控制协议允许丢失的信息重发。但大量的丢包会影响传输效率。所以,QoS更关注的是丢包的统计数据——丢包率。丢包率是指在网络传输过程中丢失报文占传输报文的百分比。
2、流分类与流动作
流分类是对进入DiffServ域的业务进行分类,以便在网络中得到相应的适当处理。流分类主要目的是让其他处理此报文的应用系统或设备知道该报文的类别,并根据这种类别对报文进行一些事先约定了的处理。

3、令牌桶
令牌桶(Token-Bucket)是目前最常采用的一种流量测量方法,用来评估流量速率是否超过了规定值。
令牌桶可以看作是一个存放令牌的容器,预先设定一定的容量。系统按给定的速度向桶中放置令牌,当桶中令牌满时,多余的令牌溢出。
令牌桶只是一种流量测量方法,并不能对流量进行过滤或采取某种措施,比如说丢弃数据包等,这些操作由其他功能完成,如CAR、GTS等。
当数据流到达设备时首先会根据数据的大小从令牌桶中取出与数据大小相当的令牌数量用来传输数据。也就是说要使数据被传输必须保证令牌桶里有足够多的令牌,如果令牌数量不够,则数据会被丢弃或缓存。这就可以限制报文的流量只能小于等于令牌生成的速度,达到限制流量的目的。


单速率双桶令牌桶
RFC定义了两种令牌桶算法——单速率三色标记算法和双速率三色标记算法,使用红、黄、绿三色来标记评估结果。这两种算法都允许流量在一定程度上突发,但单速率三色标记关注报文尺寸的突发,而双速率三色标记则关注速率上的突发。单速率较双速率实现简单,成为目前业界比较常用的流量评估方式。
两种令牌桶算法都有两种工作模式——色盲模式(Color-Blind)与非色盲模式(Color-Aware),其中色盲模式是较常用的,也是默认的模式。
单速率双桶令牌桶主要由如下三个参数构成:
当报文到来后,直接与桶中的令牌数相比较,如果有足够的令牌就转发,如果没有足够的令牌则丢弃或缓存。为方便用Tc和Te表示桶中的令牌数量,Tc和Te初始化等于CBS和EBS。在色盲模式下,在对到达报文(假设报文大小为B)进行评估时,遵循以下规则:
- 如果报文长度不超过C桶中的令牌数Tc,则报文被标记为绿色,且Tc=Tc-B,
- 如果报文长度超过C桶中的令牌数Tc但不超过E桶中的令牌数Te,则报文被标记为黄色,且Te=Te-B,
- 如果报文长度超过E桶中的令牌数Te,报文被标记为红色,但Tc和Te不变
令牌桶业界实现
实际中比较常见的有两种实现方式:
- 周期性的添加,添加的时间间隔就是令牌桶的容量与添加速率的比值:△t=CBS/CIR,每次添加的令牌数为 CBS 个。
- 一次性添加,添加令牌的数量是△t×CIR(△t 是当前时间与上次添加令牌的时间之差),且是一次添加完毕,并不是按照一定速率添加。
当前业界都采用的第二种方式,第一种方式涉及定时器精度不太好控制。
由于报文转发过令牌桶的时候我们很容易能获取到的是报文长度和当前的cycle,为了提高性能,我们可以让令牌和报文长度都转化cycle,使用cycle来过桶。
我们为报文长度和cycle分别取单位为:1个字节和1个cycle,然后我们使用这两个单位来展开令牌桶实现的换算:
1秒时间单位内有CIR个字节,而1秒的时间单位有HZ * 1个cycle,利用这层关系我们假设:CIR * 1个字节 = HZ * 1个cycle,换算后我们可以得到两个公式:

两种实现方式的基本思想是一直的,我们看下第一种方式:
当CIR太大的时候,1个字节计算出来的cycle数会为小数,为了解决这个问题,我们引入扩大因子,扩大因子越大,分辨率越高,同时需要考虑HZ和最大支持的CIR的关系和溢出的风险,扩大因子又不能太大,那么公式就变成如下:
以此为依据我们看下过单速率双桶的过桶过程的整个过程:

4、流量监管(CAR)
流量监管采用承诺访问速率CAR(Committed Access Rate)来对流量进行控制。CAR利用令牌桶来衡量每个数据报文是超过还是遵守所规定的报文速率。
CAR主要有两个功能:
- 流量速率限制:通过使用令牌桶对流经端口的报文进行度量,使得在特定时间内只有得到令牌的流量通过,从而实现限速功能。
- 流分类:通过令牌桶算法对流量进行测量,根据测量结果给报文打上不同的流分类内部标记(包括服务等级与丢弃优先级)。

- 当报文处理,首先检查CAR的匹配规则,如果匹配上了,则报文进入令牌桶中进行流量速率评估。
- 令牌桶评估后,报文被标记为红、黄、绿三种颜色。红色表示报文速率过大,不符合规定;黄色表示虽然不符合规定但允许临时的突发,绿色表示符合规定。
- 当报文被分类后,根据配置的CAR规则进行处理,如丢弃、重标记、转发等处理
5、流量整形(GTS)
- 流量整形是对输出报文的速率进行控制,使报文以均匀的速率发送出去。
- 流量整形通常是为了使报文速率与下游设备相匹配。当从高速链路向低速链路传输数据,或发生突发流量时,带宽会在低速链路出口处出现瓶颈,导致数据丢失严重。这种情况下,需要在进入高速链路的设备出口处进行流量整形
流量整形通常使用缓冲区和令牌桶来完成,当报文的发送速度过快时,首先在缓冲区进行缓存,在令牌桶的控制下再均匀地发送这些被缓冲的报文。


6、拥塞管理 -- FIFO

FIFO不对报文进行分类。FIFO按报文到达接口的先后顺序让报文进入队列,在队列的出口让报文按进队的顺序出队,先进的报文将先出队,后进的报文将后出队。
7、拥塞管理 -- PQ

在报文出队的时候,首先让高优先队列中的报文出队并发送,直到高优先队列中的报文发送完,然后发送中优先队列中的报文,直到发送完,接着是低优先队列。在调度低优先级队列时,如果高优先级队列又有报文到来,则会优先调度高优先级队列。这样,较高优先级队列的报文将会得到优先发送,而较低优先级的报文后发送。
8、拥塞管理 – WFQ/FQ

WFQ按照一定的规则给每个队列分配权重,使用的是WRR的调度方式,在轮询的时候,WRR每个队列享受的调度机会和该队列的权重成比例。
WRR的实现方法是为每个队列设置一个权重值,根据权重进行初始化。每次轮询到一个队列时,该队列输出一个报文且权重减一。当权重为0时停止调度该队列,但继续调度其它权重不为0的队列。当所有队列的权重都为0时,所有的队列重新根据权重初始化,开始新一轮调度。在一个循环中,权重大的队列被多次调度。
FQ 可以理解为所有的队列权重值相等的特殊的WFQ队列。
WRR的升级版是加权差分轮询WDRR(Weighted Deficit Round Robin)调度主要解决WRR不能设置权重的不足。
WDRR为每个队列设置一个计数器Deficit,Deficit初始化为Weight*MTU。每次轮询到一个队列时,该队列输出一个报文且计数器Deficit减去报文长度。当计数器为0时停止调度该队列,但继续调度其他计数器不为0的队列。当所有队列的计数器都为0时,所有计数器的Deficit都加上Weight*MTU,开始新一轮调度。
9、拥塞管理 – CBWFQ

基于类的加权公平队列(以后简称CBWFQ)首先根据TOS、DSCP、IP报文的五元组等规则来对报文进行分类;对于MPLS网络主要是根据EXP域值进行分类,然后让不同类别的报文进入不同的队列。对于不匹配任何类别的报文,报文被送入系统定义的缺省类。
CBWFQ分为三类队列: EF队列、 AF队列、 BE队列,下面分别进行介绍。
EF 队列
EF队列是一个具有高优先级的队列,一个或多个类的报文可以被设定,进入EF队列
不同类别的报文可设定占用不同的带宽。在调度出队的时候,若EF队列中有报文,则总是优先发送EF队列中的报文,直到EF队列中没有报文时,或者超过为EF队列配置的最大预留带宽时才调度发送其他队列中的报文。
进入EF队列的报文,在接口没有发生拥塞时(此时所有队列中都没有报文)都可以被发送;在接口发生拥塞时(队列中有报文时)会被限速,超出规定流量的报文将被丢弃。这样,属于EF队列的报文既可以获得空闲的带宽,又不会占用超出规定的带宽,保护了其他报文的应得带宽。
AF 队列
AF队列优先级比EF低,在系统调度报文出队的时候,按用户为各类报文设定的带宽将报文出队发送。这种队列技术应用了先进的队列调度算法,可以实现各个类的队列的公平调度(WRR)。当接口中某些类别的报文没有时, AF队列的报文还可以公平地得到空闲的带宽,同时,在接口拥塞的时候,仍然能保证各类报文得到用户设定的最小带宽。
BE 队列
当报文不匹配用户设定的所有类别时,报文被送入系统定义的缺省类。虽然允许为缺省类配置带宽,BE队列使用WFQ调度,使所有进入缺省类的报文进行基于流的队列调度。
综上所述:
低时延队列(EF 队列)用来支撑 EF 类业务,被绝对优先发送,保证时延;
带宽保证队列(AF 队列)用来支撑 AF 类业务,可以保证每一个队列的带宽及可控的时延;缺省队列(BE 队列)对应 BE 业务,使用接口剩余带宽进行发送。
其实CBWFQ就是WFQ的升级版,是PQ + WRR调度的组合版本,不同优先级使用PQ调度,相同优先级使用WRR调度。
10、拥塞避免 – WRED
拥塞避免是指通过监视网络资源(如队列或内存缓冲区)的使用情况,在拥塞有加剧趋势时,主动丢弃报文,通过调整网络的流量来解除网络过载的一种流控机制。
当前两种丢弃策略:
加权随机早期检测 WRED(Weighted Random Early Detection)是在队列拥塞前进行报文丢弃的一种拥塞避免机制。 WRED 通过随机丢弃报文避免了 TCP 的全局同步现象, 当某个TCP连接的报文被丢弃,开始减速发送的时候,其他的TCP连接仍然有较高的发送速度。这样,无论何时总有 TCP 连接在进行较快的发送,提高了线路带宽的利用率。
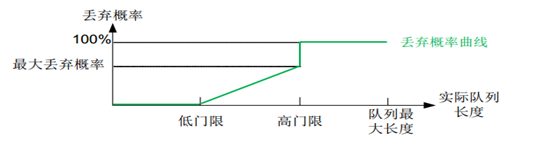
WRED 为每个队列都设定一对低门限和高门限值,并规定:
- 当队列长度小于低限时,不丢弃报文,丢弃概率为 0%。
- 当队列长度超过高限时,丢弃所有新到来的报文,即进行尾丢弃,丢弃概率为 100%。
- 当队列长度在低限和高限之间时,开始随机丢弃新到来的报文,且设定了一个最大丢弃概率,队列越长,丢弃概率越大。如果以报文长度为横坐标,丢弃概率为纵坐标,则丢弃概率曲线如图所示。
直接采用队列的长度和上限、下限比较并进行丢弃,将会对突发性的数据流造成不公正的待遇,不利于数据流的传输。 RED类算法采用平均队列长度和设置的队列上限、下限比较来确定丢弃的概率。计算队列平均长度的公式为:
平均队列长度=(以前的平均队列长度×(1-1/(2的n次方)))+(当前队列长度×(1/(2的n次方))),其中n可以通过命令配置。队列平均长度既反映了队列的变化趋势,又对队列长度的突发变化不敏感,避免了对突发性数据流的不公正待遇。
WRED算法在RED算法的基础上引入了优先权,它引入IP优先级、 DSCP和MPLS EXP区别丢弃策略,考虑了高优先权报文的利益,使其被丢弃的概率相对较小。如果对于所有优先权配置相同的丢弃策略,那么WRED就变成了RED
11、HQOS
HQoS即层次化QoS(Hierarchical Quality of Service),是一种通过多级队列调度机制,解决Diffserv模型下多用户多业务带宽保证的技术。
- 传统的QoS采用一级调度,单个端口只能区分业务优先级,无法区分用户。只要属于同一优先级的流量,使用同一个端口队列,不同用户的流量彼此之间竞争同一个队列资源,无法对端口上单个用户的单个流量进行区分服务。
- HQoS采用多级调度的方式,可以精细区分不同用户和不同业务的流量,提供区分的带宽管理。
为了实现分层调度,HQoS采用树状结构的层次化调度模型

调度器可以对多个队列进行调度,也可以对多个调度器进行调度。其中,调度器可以看成父节点,被调度的队列/调度器看成子节点。父节点是多个子节点的流量汇聚点。
每个节点可以指定分类规则和控制参数,对流量进行一次分类和控制。不同层次的节点,其分类规则可以面向不同的分类需求(如用户、业务类型等),并且在不同的节点上可以对流量做不同的控制动作,从而实现了对流量进行多层次、多用户、多业务的管理。


