为什么要重写hashCode和equals方法
1 复习一下Hash算法
先复习一下数据结构里的一个知识点:在一个长度为 n(假设是 10000)的线性表(假设是ArrayList)里,存放着无序的数字;如果我们要找一个指定的数字,就不得不通过从头到尾依次遍历来查找。
我们再来观察Hash表(这里的Hash表纯粹是数据结构上的概念,和Java无关)。它的平均查找次数接近于 1,代价相当小,关键是在Hash表里,存放在其中的数据和它的存储位置是用Hash函数关联的。
我们假设一个Hash函数是 x*x%5。当然实际情况里不可能用这么简单的Hash函数,这里纯粹为了说明方便,而Hash表是一个长度是 11的线性表。如果我们要把 6放入其中,那么我们首先会对 6用Hash函数计算一下,结果是 1,所以我们就把 6放入到索引号是 1这个位置。同样如果我们要放数字 7,经过Hash函数计算, 7的结果是 4,那么它将被放入索引是4的这个位置。这个效果如下图所示。
这样做的好处非常明显。比如我们要从中找 6这个元素,我们可以先通过Hash函数计算 6的索引位置,然后直接从 1号索引里找到它了。
不过我们会遇到“Hash值冲突”这个问题。比如经过Hash函数计算后, 7和 8会有相同的Hash值,对此Java的HashMap对象采用的是**“链地址法”**的解决方案。效果如下图所示
具体的做法是,为所有Hash值是 i的对象建立一个同义词链表。假设我们在放入 8的时候,发现 4号位置已经被占,那么就会新建一个链表结点放入 8。同样,如果我们要找 8,那么发现 4号索引里不是 8,那会沿着链表依次查找。
虽然我们还是无法彻底避免Hash值冲突的问题,但是Hash函数设计合理,仍能保证同义词链表的长度被控制在一个合理的范围里。这里讲的理论知识并非无的放矢,大家能在后文里清晰地了解到重写hashCode方法的重要性。
2 复习Object类的hashCode和equals方法
class User{
String username;
String pwd;
public User(String username, String pwd) {
super();
this.username = username;
this.pwd = pwd;
}
}
public class Test {
public static void main(String[] args) {
User user1=new User("admin","123");
User user2=new User("admin","123");
System.out.println(user1.hashCode());
System.out.println(user2.hashCode());
System.out.println(user1.equals(user2));
}
}
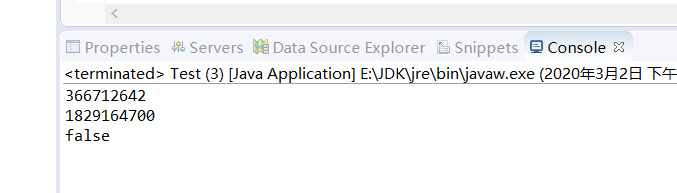
Object类的hashCode方法返回了对象的内存地址
Object类的equals方法比较了对象的内存地址
我们看到user1和user2的内存地址不同 即是我们在创建对象的时候给了一样的username和pwd 但因为调用的是Object类的方法 所以返回了false
3 重写hashCode方法和equals方法
我们先来看一下正常情况下的代码和结果
class User{
int id;
String name;
public User(int id, String name) {
super();
this.id = id;
this.name = name;
}
@Override
public int hashCode() {
return this.id;
}
@Override
public boolean equals(Object obj) {
User u=(User)obj;
return this.id==u.id;
}
}
class Test{
public static void main(String[] args) {
User u1=new User(1,"小明");
User u2=new User(1,"明明");
HashMap<User,String> hm=new HashMap<User, String>();
hm.put(u1,"他喜欢打篮球");
System.out.println(hm.get(u2));
}
}

在正常情况下 我们自定义了User对象 以id作为他的唯一表示 这里我们使用了HashMap进行存储
我门创建了两个对象u1和u2 但他们实际是一个人 因为他们的id相同 小明和明明分别是一个人的大名和小名
在重写了hashCode和equals方法之后 那么我们将u1存进去之后 通过get方法拿出的也应该是"他喜欢打篮球"这句话 结果正常
下面我们看一下将hashCode和equals注释的情况
class User{
int id;
String name;
public User(int id, String name) {
super();
this.id = id;
this.name = name;
}
/*
@Override
public int hashCode() {
return this.id;
}
@Override
public boolean equals(Object obj) {
User u=(User)obj;
return this.id==u.id;
}*/
}
class Test{
public static void main(String[] args) {
User u1=new User(1,"小明");
User u2=new User(1,"明明");
HashMap<User,String> hm=new HashMap<User, String>();
hm.put(u1,"他喜欢打篮球");
System.out.println(hm.get(u2));
}
}

当我们往HashMap里放u1时,首先会调用 User这个类的 hashCode方法计算它的 hash值,随后把 k1放入hash值所指引的内存位置。
关键是我们没有在User里定义 hashCode方法。这里调用的仍是 Object类的 hashCode方法(所有的类都是Object的子类),而 Object类的 hashCode方法返回的 hash值其实是 u1对象的 内存地址(假设是1000)
如果我们随后是调用 hm.get(u1),那么我们会再次调用 hashCode方法(还是返回 u1的地址 1000),随后根据得到的 hash值,能很快地找到 u1
但我们这里的代码是 hm.get(u2),当我们调用 Object类的 hashCode方法(因为 User里没定义)计算 u2的 hash值时,其实得到的是 u2的内存地址(假设是 2000)。由于 u1和 u2是两个不同的对象,所以它们的内存地址一定不会相同,也就是说它们的 hash值一定不同,这就是我们无法用 u2的 hash值去拿 u1的原因
当我们把User类的hashCode方法的注释去掉后,会发现它是返回 id属性的 hashCode值,这里 u1和 u2的 id都是1,所以它们的 hash值是相等的
我们再来更正一下存 u1和取 u2的动作。存 u1时,是根据它 id的 hash值,假设这里是 100,把 u1对象放入到对应的位置。而取 u2时,是先计算它的 hash值(由于 u2的 id也是 1,这个值也是 100),随后到这个位置去找。
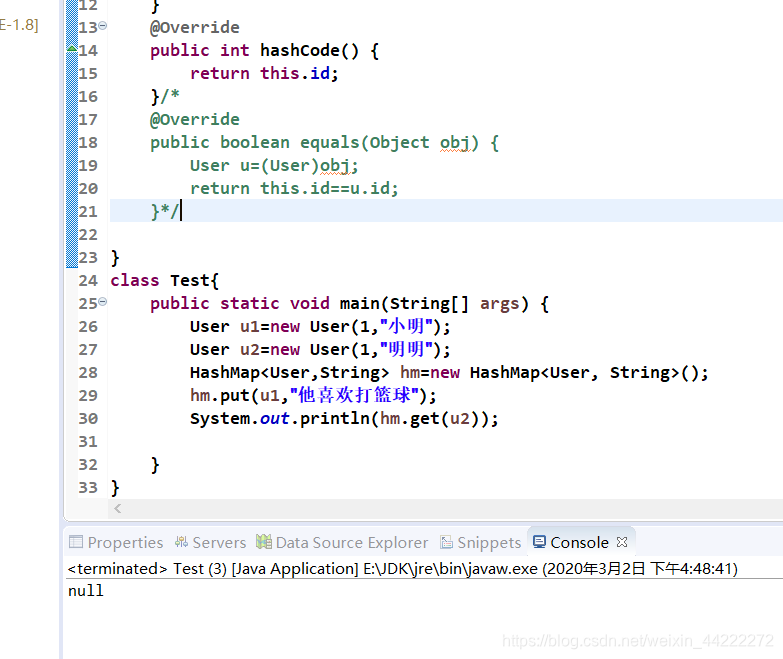
但结果会出乎我们意料:明明 100号位置已经有 u1 但输出结果依然是 null。其原因就是没有重写 User对象的 equals方法
HashMap是用链地址法来处理冲突,也就是说,在 100号位置上,有可能存在着多个用链表形式存储的对象。它们通过 hashCode方法返回的 hash值都是100。
当我们通过 u2的 hashCode到 100号位置查找时,确实会得到 u1。但 u1有可能仅仅是和 u2具有相同的 hash值,但未必和 u2相等 这个时候 就需要调用 User对象的 equals方法来判断两者是否相等了。
由于我们在 User对象里没有定义 equals方法,系统就不得不调用 Object类的 equals方法。由于 Object的固有方法是根据两个对象的内存地址来判断,所以 u1和 u2一定不会相等,这就是为什么依然通过 hm.get(u2)依然得到 null的原因
为了解决这个问题,我们需要打开User类里的equals方法的注释 在这个方法里 只要两个对象都是 User类型,而且它们的 id相等,它们就相等
