操作系统发展史
参考博客即可:https://www.cnblogs.com/Dominic-Ji/articles/10929381.html
多道技术
单核实现并发的效果
必备知识点
-
并发
看起来像同时运行的就可以称之为并发
-
并行
真正意义上的同时执行
ps:
- 并行肯定算并发
- 单核的计算机肯定不能实现并行,但是可以实现并发!!!
补充:我们直接假设单核就是一个核,干活的就一个人,不要考虑cpu里面的内核数
多道技术图解
节省多个程序运行的总耗时
参考群内截图
多道技术重点知识
空间上的服用与时间上的服用

-
空间上的复用
多个程序公用一套计算机硬件
-
时间上的复用
例子:洗衣服30s,做饭50s,烧水30s
单道需要110s,多道只需要任务做长的那一个 切换节省时间
例子:边吃饭边玩游戏 保存状态
切换+保存状态
"""
切换(CPU)分为两种情况
1.当一个程序遇到IO操作的时候,操作系统会剥夺该程序的CPU执行权限
作用:提高了CPU的利用率 并且也不影响程序的执行效率
2.当一个程序长时间占用CPU的时候,操作吸引也会剥夺该程序的CPU执行权限
弊端:降低了程序的执行效率(原本时间+切换时间)
"""
手工操作 —— 穿孔卡片
1946年第一台计算机诞生--20世纪50年代中期,计算机工作还在采用手工操作方式。此时还没有操作系统的概念。


程序员将对应于程序和数据的已穿孔的纸带(或卡片)装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;计算完毕,打印机输出计算结果;用户取走结果并卸下纸带(或卡片)后,才让下一个用户上机。
手工操作方式两个特点:
(1)用户独占全机。不会出现因资源已被其他用户占用而等待的现象,但资源的利用率低。
(2)CPU 等待手工操作。CPU的利用不充分。
20世纪50年代后期,出现人机矛盾:手工操作的慢速度和计算机的高速度之间形成了尖锐矛盾,手工操作方式已严重损害了系统资源的利用率(使资源利用率降为百分之几,甚至更低),不能容忍。唯一的解决办法:只有摆脱人的手工操作,实现作业的自动过渡。这样就出现了成批处理。
批处理 —— 磁带存储
批处理系统:加载在计算机上的一个系统软件,在它的控制下,计算机能够自动地、成批地处理一个或多个用户的作业(这作业包括程序、数据和命令)。
联机批处理系统
首先出现的是联机批处理系统,即作业的输入/输出由CPU来处理。

主机与输入机之间增加一个存储设备——磁带,在运行于主机上的监督程序的自动控制下,计算机可自动完成:成批地把输入机上的用户作业读入磁带,依次把磁带上的用户作业读入主机内存并执行并把计算结果向输出机输出。完成了上一批作业后,监督程序又从输入机上输入另一批作业,保存在磁带上,并按上述步骤重复处理。
监督程序不停地处理各个作业,从而实现了作业到作业的自动转接,减少了作业建立时间和手工操作时间,有效克服了人机矛盾,提高了计算机的利用率。
但是,在作业输入和结果输出时,主机的高速CPU仍处于空闲状态,等待慢速的输入/输出设备完成工作: 主机处于“忙等”状态。
脱机批处理系统
为克服与缓解:高速主机与慢速外设的矛盾,提高CPU的利用率,又引入了脱机批处理系统,即输入/输出脱离主机控制。


进程理论
必备知识点
程序与进程的区别
"""
程序就是一堆躺在硬盘上的代码,是“死”的
进程则表示程序正在执行的过程,是“活”的
"""
进程调度
-
先来先服务调度算法
"""对长作业有利,对短作业无益""" -
短作业优先调度算法
"""对短作业有利,多长作业无益""" -
时间片轮转法+多级反馈队列
进程运行的三状态图
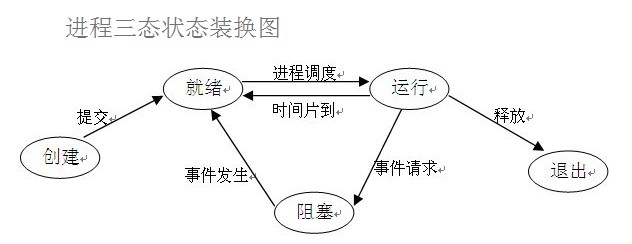
两对重要概念
-
同步和异步
"""描述的是任务的提交方式""" 同步:任务提交之后,原地等待任务的返回结果,等待的过程中不做任何事(干等) 程序层面上表现出来的感觉就是卡住了 异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情 我提交的任务结果如何获取? 任务的返回结果会有一个异步回调机制自动处理 -
阻塞非阻塞
"""描述的程序的运行状态""" 阻塞:阻塞态 非阻塞:就绪态、运行态 理想状态:我们应该让我们的写的代码永远处于就绪态和运行态之间切换
上述概念的组合:最高效的一种组合就是异步非阻塞
多道程序系统
多道程序设计技术
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。

在A程序计算时,I/O空闲, A程序I/O操作时,CPU空闲(B程序也是同样);必须A工作完成后,B才能进入内存中开始工作,两者是串行的,全部完成共需时间=T1+T2。

将A、B两道程序同时存放在内存中,它们在系统的控制下,可相互穿插、交替地在CPU上运行:当A程序因请求I/O操作而放弃CPU时,B程序就可占用CPU运行,这样 CPU不再空闲,而正进行A I/O操作的I/O设备也不空闲,显然,CPU和I/O设备都处于“忙”状态,大大提高了资源的利用率,从而也提高了系统的效率,A、B全部完成所需时间<<T1+T2。
多道程序设计技术不仅使CPU得到充分利用,同时改善I/O设备和内存的利用率,从而提高了整个系统的资源利用率和系统吞吐量(单位时间内处理作业(程序)的个数),最终提高了整个系统的效率。
单处理机系统中多道程序运行时的特点:
(1)多道:计算机内存中同时存放几道相互独立的程序;
(2)宏观上并行:同时进入系统的几道程序都处于运行过程中,即它们先后开始了各自的运行,但都未运行完毕;
(3)微观上串行:实际上,各道程序轮流地用CPU,并交替运行。
多道程序系统的出现,标志着操作系统渐趋成熟的阶段,先后出现了作业调度管理、处理机管理、存储器管理、外部设备管理、文件系统管理等功能。
由于多个程序同时在计算机中运行,开始有了空间隔离的概念,只有内存空间的隔离,才能让数据更加安全、稳定。
出了空间隔离之外,多道技术还第一次体现了时空复用的特点,遇到IO操作就切换程序,使得cpu的利用率提高了,计算机的工作效率也随之提高。
开启进程的两种方式
定心丸:代码开启进程和线程的方式,代码书写基本是一样的,你学会了如何开启进程就学会了如何开启线程
from multiprocessing import Process
import time
def task(name):
print('%s is running'%name)
time.sleep(3)
print('%s is over'%name)
if __name__ == '__main__':
# 1 创建一个对象
p = Process(target=task, args=('jason',))
# 容器类型哪怕里面只有1个元素 建议要用逗号隔开
# 2 开启进程
p.start() # 告诉操作系统帮你创建一个进程 异步
print('主')
# 第二种方式 类的继承
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print('hello bf girl')
time.sleep(1)
print('get out!')
if __name__ == '__main__':
p = MyProcess()
p.start()
print('主')
总结
"""
创建进程就是在内存中申请一块内存空间将需要运行的代码丢进去
一个进程对应在内存中就是一块独立的内存空间
多个进程对应在内存中就是多块独立的内存空间
进程与进程之间数据默认情况下是无法直接交互,如果想交互可以借助于第三方工具、模块
"""
join方法
join是让主进程等待子进程代码运行结束之后,再继续运行。不影响其他子进程的执行
from multiprocessing import Process
import time
def task(name, n):
print('%s is running'%name)
time.sleep(n)
print('%s is over'%name)
if __name__ == '__main__':
# p1 = Process(target=task, args=('jason', 1))
# p2 = Process(target=task, args=('egon', 2))
# p3 = Process(target=task, args=('tank', 3))
# start_time = time.time()
# p1.start()
# p2.start()
# p3.start() # 仅仅是告诉操作系统要创建进程
# # time.sleep(50000000000000000000)
# # p.join() # 主进程等待子进程p运行结束之后再继续往后执行
# p1.join()
# p2.join()
# p3.join()
start_time = time.time()
p_list = []
for i in range(1, 4):
p = Process(target=task, args=('子进程%s'%i, i))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('主', time.time() - start_time)
进程之间数据相互隔离
from multiprocessing import Process
money = 100
def task():
global money # 局部修改全局
money = 666
print('子',money)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print(money)
两对重要概念
同步和异步:
描述的是 任务的提交方式
同步:任务提交之后,原地等待任务的返回结果,等待的结果中不做任何事(干等着)
程序层面上 表现出来的感觉 就是卡住了
异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情,等待任务的返回结果自动提交给调用者
我提交的任务结果如何获取?
任务的返回结果 会有一个异步回调机制自动处理
同步例子:
import time
def func():
time.sleep(3)
print('Hello World')
if __name__ == '__main__':
res = func() # 同步调用
res
print('hahah')
阻塞和非阻塞:
描述的是 程序的运行状态
阻塞:阻塞态
非阻塞:就绪态、运行态
理想状态:我们应该让我们写的代码 永远处于 就绪态 和 运行态 之间切换