如今,深度学习可以在图像合成和处理领域产生惊人的效果。我们已经看到了这样一些例子:使想象中的人产生幻觉的网站,展示名人说从未说过的话的视频,以及使人们跳舞的工具。这些例子都足够的真实可以愚弄我们大多数人。其中一个新颖的壮举是FaceShifter[1],这是一个深度学习模型,它可以在优于最新技术的图像中交换人脸。在本文中,我们将了解它是如何工作的。
问题陈述
我们有一个源人脸图像Xₛ和一个目标人脸图像Xₜ,我们希望生成一个新的人脸图像Yₛ,它具有Xₜ(姿势、照明、眼镜等)的属性,但具有Xₛ中的人的身份。图1总结了这个问题陈述。现在,我们继续解释模型。

图1。换脸的问题陈述。显示的结果来自于FaceShifter模型。改编自[1]。
FaceShifter模型
FaceShifter由两个网络组成,称为AEI网和HEAR网。AEI网络生成一个初步的面部交换结果,HEAR网络对该输出进行优化。让我们将两者分开进行分析。
AEI网络
AEI网是“自适应嵌入集成网络”的缩写。这是因为AEI网络由3个子网络组成:
- 身份编码器:一种将Xₛ嵌入到描述图像中人脸身份的空间的编码器。
- 多级属性编码器:一种将Xₜ嵌入到一个空间中的编码器,该空间描述了交换面时要保留的属性。
- AAD生成器:将前两个子网的输出集成起来,生成Xₜ中的面孔与Xₛ的标识交换的生成器。
AEI网络如图2所示。让我们把它的细节具体化。

图2。AEI网的体系结构。改编自[1]。
身份编码器
该子网络将源图像Xₛ投影到低维特征空间。输出只是一个向量,我们称之为zᵢ,如图3所示。这个向量在Xₛ中编码面部的身份,这意味着它应该提取我们人类用来区分不同人面部的特征,比如眼睛的形状、眼睛和嘴的距离、嘴的弯曲度等等。
作者使用预先训练过的编码器。他们使用了一个经过训练的人脸识别网络。这有望满足我们的要求,因为区分人脸的网络必须提取与身份相关的特征。

图3。身份编码器。改编自[1]。
多级属性编码器
该子网络对目标图像X进行编码。它产生多个向量,每个向量以不同的空间分辨率描述Xₜ的属性,一般有8个特征向量,称为zₐ。这里的属性是指目标图像中的面部结构,如面部的姿势、轮廓、面部表情、发型、肤色、背景、场景照明等。如图4所示,它是一个具有U型网络结构的ConvNet,其中,输出向量仅仅是上尺度/解码部分中的每一级的特征映射。请注意,此子网络未预先训练。

图4。多级属性编码器体系结构。改编自[1]。
将Xₜ表示为多个嵌入是必要的,因为在单个空间分辨率下使用一个嵌入将导致生成交换面的所需输出图像的信息丢失(即,我们希望从Xₜ保留太多精细细节,这使得压缩图像不可行)。这一点在作者所做的消融研究中很明显,他们试图仅使用前3个zₐ嵌入而不是8个zₐ嵌入来表示Xₜ,这导致图5中的输出更加模糊。

图5。使用多个嵌入来表示目标的效果。如果使用前3个zₐ嵌入,则输出为压缩的;如果使用所有8个嵌入,则输出为AEI Net。改编自[1]。
AAD生成器
AAD生成器是“自适应注意非规范化生成器”的缩写。它综合了前两个子网的输出以提高空间分辨率,从而产生AEI网的最终输出。它通过叠加一个新的块AAD Resblock来实现,如图6所示。

图6。左图中的AAD生成器体系结构,右图中的AAD Resblock。改编自[1]。
这个块的新部分是AAD层。我们把它分成3部分,如图7所示。从较高的层次上讲,第1部分告诉我们如何编辑输入特征映射hᵢ,使其在属性方面更像Xₜ。具体地说,它输出两个张量,其大小与hᵢₙ的大小相同,一个张量包含与hᵢₙ中的每个单元格相乘的缩放值,另一个张量包含移位值。第1部分图层的输入是属性向量之一。同样,第2部分将告诉我们如何编辑特征地图hᵢ,使其更像Xₛ。

图7。AAD层的体系结构。改编自[1]。
第3部分的任务是选择我们应该在每个单元格/像素处关注的部分(2或3)。例如,在与嘴相关的单元/像素处,该网络将告诉我们更多地关注第2部分,因为嘴与身份更相关。这是通过图8所示的一个实验进行的经验证明。

图8。显示AAD层第3部分所学内容的实验。右边的图像显示了整个AAD生成器中不同步数/空间分辨率的第3部分的输出。亮区表示我们应该关注同一性的单元格(即第2部分),黑色区域表示关注第1部分。注意,在高空间分辨率下,我们主要关注的是第1部分。
如此,AAD生成器将能够一步一步地构建最终图像,在每个步骤中,它将确定给定身份和属性编码的当前特征映射的最佳放大方式。
现在,我们有了一个网络,AEI网络,它可以嵌入Xₛ&Xₜ,并以实现我们目标的方式集成它们。我们将AEI Net的输出称为Yₛₜ*。
训练损失函数
一般来说,损失是我们希望网络所达到目的的数学公式。训练AEI网有4个损失:
- 我们希望它输出一个真实的人的脸,所以我们将有一个对抗性的损失,就像任何对抗网络。
- 我们希望生成的人脸具有Xₛ的身份。我们唯一能代表同一性的数学对象是zᵢ。因此,这个目标可以用以下损失来表示:
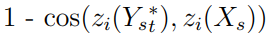
- 我们希望输出具有Xₜ的属性。损失是:
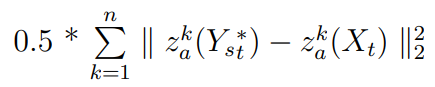
- 作者根据网络应该输出Xₜ(如果Xₜ和Xₛ实际上是相同的图像)的观点,又增加了一个损失:

我相信这最后的损失是必要的,以驱动zₐ实际编码属性,因为它不是像zᵢ预先训练。如果没有它,AEI网可以忽略Xₜ,使zₐ只产生0。
我们的总损失只是以前损失的加权和。
Hear网络
AEI网络是一个不光能够进行面部交换完整的网络。然而,它在保持一致方面还不够好。具体地说,每当目标图像中的某项事物遮挡了最终输出中应该出现的部分面部(如眼镜、帽子、头发或手),AEI 网络就会将其移除。这些事物应该仍然存在,因为它与将要更改的标识无关。因此,作者实现了一个称为“启发式错误确认细化网络”的附加网络,该网络具有恢复这种遮挡的单一任务。
他们注意到,当他们将AEI网络(即Xₛ&Xₜ)的输入设为相同的图像时,它仍然没有像图9那样保留遮挡。

图9。当我们输入与Xₛ&Xₜ相同的图像时AEI Net的输出。注意头巾上的链子是如何在输出中丢失的。改编自[1]。
因此,他们没有将Yₛₜ*和Xₜ做为HEAR网络的输入,而是将其设为Yₛₜ*&(Xₜ-Yₜₜ*),其中Yₜₜ*是当Xₛₜ和Xₜ是相同图像时AEI网络的输出。这将把HEAR网络指向遮挡未保留的像素。如图10所示。

图10。HEAR网络的结构。改编自[1]。
训练损失函数
HEAR网络的损失函数为:
- 因保留身份而蒙受的损失:

- 不大幅度改变Yₛₜ*的损失:
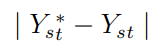
- 如果Xₛ&Xₜ是相同的图像,那么HEAR 网络的输出应该是Xₜ:
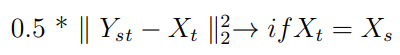
总损失是这些损失的总和。
结果
换脸器的效果是惊人的。在图11中,您可以找到它在设计它所依赖的数据集之外的图像上的泛化性能的一些示例(即来自更宽泛的数据集)。注意它是如何在不同和困难的条件下正确工作的。

图11。结果表明,该变换器具有良好的性能。改编自[1]。
作者:Ahmed Maher
翻译人:tensor-zhang
