Python 3.X:爬虫库urllib几个问题处理
1、安装问题
urllib在Python 3.X是urllib3,可以在pycharm里安装,或用pip install安装。
2、urllib模块问题
urllib包里面有四个模块
urllib.request
urllib.error
urllib.parse
urllib.robotparser
urllib.request模块最重要,它主要包含对服务器请求的发出、跳转、代理和安全等各个方面的功能实现。urllib.request模块提供了最基本的构造HTTP请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理授权验证(authenticaton)、重定向(redirection)、浏览器Cookies以及其他内容。
例1:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
运行后出现下图,表明访问成功。
在urlopen()方法中传入字符串格式的url地址,则此方法会访问目标网址,然后返回访问的结果。
访问的结果会是一个http.client.HTTPResponse对象,使用此对象的read()方法,则可以获取访问网页获得的数据。但是要注意的是,获得的数据会是bytes的二进制格式,所以需要decode()一下,转换成字符串格式。
例2,不能访问问题
import urllib.request
response = urllib.request.urlopen('https://movie.douban.com/')
print(response.read().decode('utf-8'))
运行后出现下图,表明访问不成功。

“418”表明访问网站被禁止。
import urllib.request
response = urllib.request.urlopen('https://movie.douban.com/')
print(response.read().decode('utf-8'))
3、使用请求头
在例2中,不能访问网站,我们加请求头,可以解决问题。
# 导入urllib
import urllib.request
url = 'https://movie.douban.com/'
# 自定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive'}
# 设置request的请求头
req = urllib.request.Request(url, headers=headers)
# 使用urlopen打开req
html = urllib.request.urlopen(req).read().decode('utf-8')
# 写入文件
f = open('code2.txt', 'w', encoding='utf8')
f.write(html)
f.close()
4.添加Cookie
为了在请求时能带上Cookie信息,我们需要重新构造一个opener。
使用request.build_opener方法来进行构造opener,将我们想要传递的cookie配置到opener中,然后使用这个opener的open方法来发起请求。
from http import cookiejar
from urllib import request
url = 'https://www.baidu.com'
# 创建一个cookiejar对象
cookie = cookiejar.CookieJar()
# 使用HTTPCookieProcessor创建cookie处理器
cookies = request.HTTPCookieProcessor(cookie)
# 并以它为参数创建Opener对象
opener = request.build_opener(cookies)
# 使用这个opener来发起请求
resp = opener.open(url)
# 查看之前的cookie对象,则可以看到访问百度获得的cookie
for i in cookie:
print(i)
5.代理IP
urllib.request.ProxyHandler()方法可动态设置代理IP池,代理IP主要以字典格式写入。
import urllib.request
url = 'https://movie.douban.com/'
# 设置代理IP
proxy_handler = urllib.request.ProxyHandler({
'http': '218.56.132.157:8080',
'https': '183.30.197.29:9797'})
# 必须使用build_opener()函数来创建带有代理IP功能的opener对象
opener = urllib.request.build_opener(proxy_handler)
response = opener.open(url)
html = response.read().decode('utf-8')
f = open('code3.txt', 'w', encoding='utf8')
f.write(html)
f.close()
urllib.error.URLError: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
出现上述错误,可以更换代理IP。
6.证书验证
遇到一些特殊网站,在浏览器上会显示连接不是私密连接而导致无法流量网页,如12306首页提示下载安装根证书。遇到此问题,最简单的方法是直接关闭证书验证。
import urllib.request
import ssl
# 关闭证书验证
ssl._create_default_https_context = ssl._create_unverified_context
url = 'https://kyfw.12306.cn/otn/leftTicket/init'
response = urllib.request.urlopen(url)
# 输出状态码
print(response.getcode())
7.数据处理
url.parse :定义了url的标准接口,实现url的各种抽取
parse模块的使用:url的解析,合并,编码,解码
使用时需导入
from urllib import parse
import urllib.parse as parse
url = 'https://www.baidu.com/s?ie=utf-8&tn=baidu&wd=%E7%BE%8E%E5%A5%B3#a'
result = parse.urlparse(url)
print(result)
print(result.scheme)
urlencode():将字典形式的参数序列化为url的编码格式k1=v1&k2=v2
data = {
'name':'liwenhao',
'password':'123456'
}
data = parse.urlencode(data).encode('UTF-8')
print(data)
unquote()可以将中文转换为URL编码格式
import urllib.parse
url = '%2523%25E7%25BC%2596%25E7%25A8%258B%2523'
# 第一次解码
first = urllib.parse.unquote(url)
print(first)
# 输出:'%23%E7%BC%96%E7%A8%8B%23'
# 第二次解码
second = urllib.parse.unquote(first)
print(second)
# 输出:'#编程#'
quote()对URL上的中文等特殊符号编码处理
from urllib import parse
word = '新冠肺炎'
url = 'http://www.baidu.com/s?wd='+parse.quote(word)
print(parse.quote(word))
print(url)
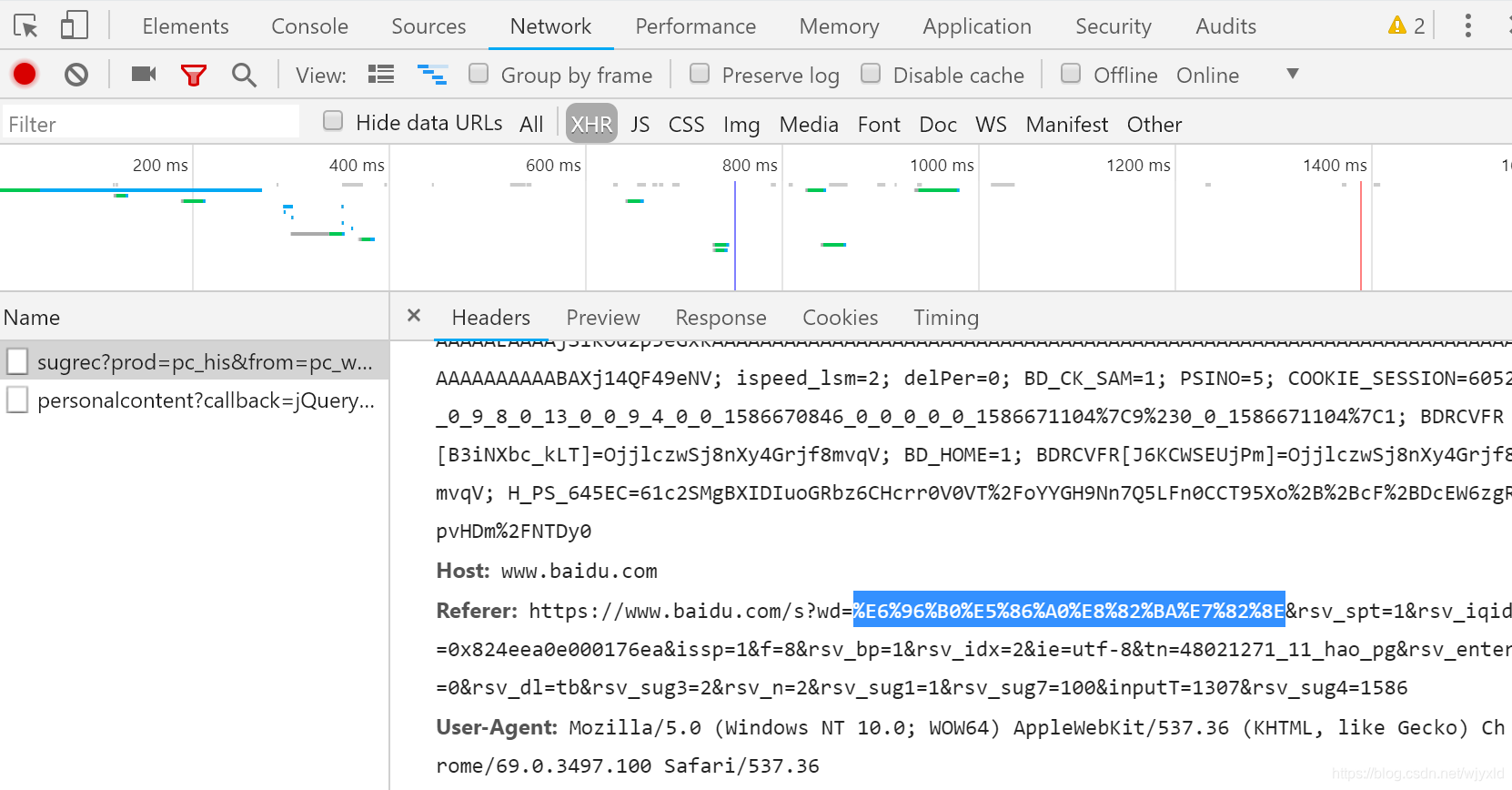
"""
%E6%96%B0%E5%86%A0%E8%82%BA%E7%82%8E #使用开发者工具network查找
http://www.baidu.com/s?wd=%E6%96%B0%E5%86%A0%E8%82%BA%E7%82%8E
"""
# unquote:可以将URL编码进行解码
url = 'http://www.baidu.com/s?wd=%E6%96%B0%E5%86%A0%E8%82%BA%E7%82%8E'
print(parse.unquote(url))
"""
http://www.baidu.com/s?wd=新冠肺炎
"""
"""
输出结果
%E4%B8%AD%E5%9B%BD%E6%A2%A6
http://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD%E6%A2%A6
http://www.baidu.com/s?wd=中国梦