下面介绍爬虫的一个基本库,urllib
从代码看起(本文所有代码依赖于第一篇代码中前三行导入的库和模块)
一:
下面的代码介绍最基本方法及其作用,注释在代码块中
import urllib
from urllib import request
from urllib import parse
response = urllib.request.urlopen('http://www.python.org')
print(response.read().decode('utf-8'))#打印抓取网页
print(response.status)#打印状态码
print(response.getheaders())#获取头信息
print(response.getheader('Server'))#获取服务器搭建信息状态码为200表示正常,其他数值则爬取错误,需检查代码是否有误
二:
下面代码演示向服务器传参,用到urlopen方法,涉及常用的请求方法之post,测试网站
http://httpbin.org/post该网站自我学习的那天开始就极不稳定,大概率无法访问
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf-8')#将参数word传值为hello,转化为bytes类型并指定编码
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())三:
下面是一个常用方法 urlretrieve
urllib.request.urlretrieve('http://www.baidu.com/','baidu.html')上述代码中,请求百度首页并将其存为html页面保存在本地,urlretrieve在urllib库的request模块中,使用前需import,该方法常用于爬取网站上的图片并下载到本地
四:
urlencode编码与parse_qs解码
下述代码演示向百度传关键词搜索
data = {'wd':'张三'}
url = "http://www.baidu.com/s"
result = parse.urlencode(data)#编码
url = url + "?" + result
print(url)
url = parse.parse_qs(url)#解码
print(url)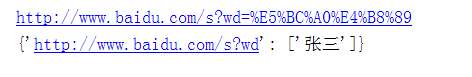
我们可以看见编码后和解码后的结果,大家也可以拿第一个url去搜索是不是张三
五
urlparse和urlsplit url分割方法
url = 'http://www.baidu.com/s?wd=pathon&username=abc#1'
result1 = parse.urlparse(url)#该函数分割的url多一个函数为params,不常用
result2 = parse.urlsplit(url)
print(result1)
print(result2)
ParseResult(scheme='http', netloc='www.baidu.com', path='/s', params='', query='wd=pathon&username=abc', fragment='1')
SplitResult(scheme='http', netloc='www.baidu.com', path='/s', query='wd=pathon&username=abc', fragment='1')
这是两种分割方法的运行结果,其区别在代码中有注释,分割的关键字可百度自行理解
urllib库到此告一段落