 map和reducer,数据是进行交互的,map数据处理结果以后要发送给reducer,reducer的启动时间是可以自己定义的,当用户提交作业的时候,启动map和reducer其实并没有严格意义上的时间规定,一般mapper任务结束,reducer才能启动,mapper可以把中间处理的结果都发给reducer,启动的晚的话,mapper生成的结果有可能需要现在本地保存起来
map和reducer,数据是进行交互的,map数据处理结果以后要发送给reducer,reducer的启动时间是可以自己定义的,当用户提交作业的时候,启动map和reducer其实并没有严格意义上的时间规定,一般mapper任务结束,reducer才能启动,mapper可以把中间处理的结果都发给reducer,启动的晚的话,mapper生成的结果有可能需要现在本地保存起来
reducer可以跟mapper一起启动
mapper处理生成的中间结果需要将同一个key的都发给同一个reducer,各个服务器都有交叉的话,需要结合mapreducer框架来实现哪个key发给哪个reducer,大部分是由程序员确定的,启动几个reducer可以由mapreducer的程序员来定义的
hadoop能实现任务并行处理,什么时候运行什么任务需要取决于你有什么数据,其次要找mapreducer或者hadoop的开发人员,这个mapreducer把程序提交给jobtracker,开始执行shuffle and sort
mapper和reducer运行什么任务都是程序员来定义的,hadoop的开发人员都是用来做这个事情,一次任务中的mapper是什么,取决于你程序员开发的程序
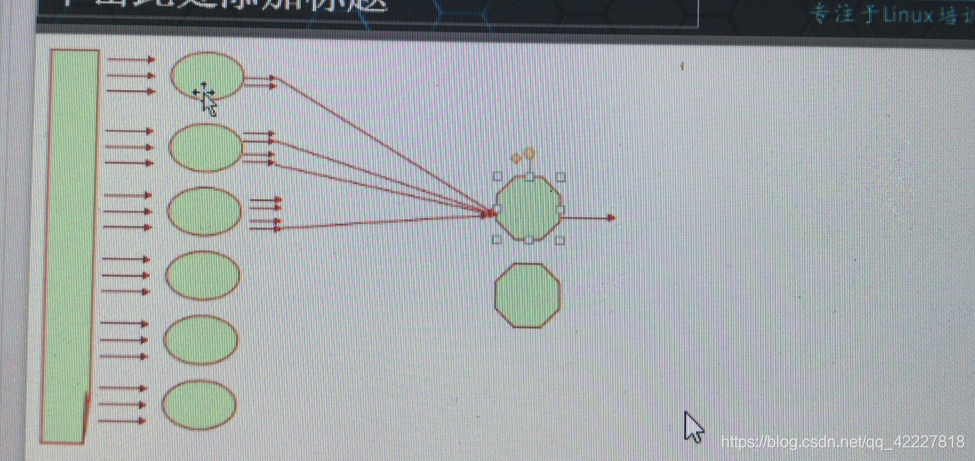
每一个数据先作为键值再由mapper处理,键值如何处理,需要程序员写mapper之前写一段代码定义,原始数据如何抽取KV,reducer可能在别的节点上运行,如何决定在哪个节点上运行,kv数据发送给哪个reducer也需要程序员来定义,
定义一个程序在每一个mapper上形成一个partitioner(分区器,)把生成的键值结果,如何执行发送,由partitioner来定义
ik1第一个键发给第一个reducer,ik3发给第三个reducer,partitioner就是负责把应该发送给哪个reducer的key执行通过shuffle and sort的过程发送给对应的reducer,而partitioner是程序员写的
mapper读取键值对并生成键值对的,这个结果发送给reducer再次折叠,得出唯一结果,mapper输入的键可能有多个,
所有的mapper同一个键必须传给同一个reducer需要一个程序负责完成,partitioner(负责把某一个key发送给某一个reducer),所有的ik1都到第一个reducer
combiner能合并就合并,不然就分散发送
比如第四个combiner 3+6 ik2=9 发送,combiner依然是mapreducer的程序员写的
mapper的读入键和输出键可以不同,reducer的读入键和输出键可以不同。combiner虽然可以做处理,但是读入和输入的键必须一致,只能有简单的合并功能
prititioner 指定的key发往指定的reducer
有多个reducers就有多个输出流,每个reducer输出的结果只是结果的一部分
大数据本来数据就存放在HDFS的不同节点上的,三个mapper启动的任务在3个分片上,剩下的只能复制了,第一个节点假如有分片,第二个节点也有分片,但是mapper启动的任务只在第一个节点上,这个数据的分片需要复制到那个节点上,
mapper读入kv输出kv,经过shuffle and sort,每个mapper在本地完成排序,sort,sort完以后开始copy,复制的方式传递给每个reducer,同一个key传给一个reducer,mapper形成同一个数据流由reducer进行折叠,组成一部分数据
reducer的处理结果放到了HDFS上,一旦存储在HDF上,每个数据都应该有分片有副本
这是hadoop1中的mapreducer
client提交请求,叫job,hadoop mapreduce master 就叫做jobtracker,把提交的作业,(map是一个java进程,应该在一个jvm运行,reduce也是如此)map实例负责从input的data中读取数据开始生成键值数据,
reduce的job parts负责生成reduce实例,reduce实例从map接收kv数据,折叠以后生成outputdata存回HDFS
master要把client的任务分成两部分,map,reduce
map启动几个,运行在哪个节点上是由jobtracker决定的,reduce启动几个是由程序员决定,也可以由jobtracker自行决定,
hadoop mapreduce master 应该追踪hadoop中的 job history作业历史
active jobs 活动作业historical job 历史job
活动作业分为map task,reduce task
任何的task tracker运行的数量是有限的(假如4个任务槽),就认为task 3 跑满了,再提交任何作业都不跑了
job tracker 2个作用,负责分发作业,很容易成为性能瓶颈
到了hadoop 2

MR mapreduce
MRv1 (Hadoop2) --> MRv2(Hadoop2)
MRv1: Cluster resource manager, 集群资源管理 Data processing 数据处理
(在mapreduce可以跑程序,pig,hive,其他)
MRv2:
YARN:Cluster resourse manager
MRv2: Data processing 只保留数据处理功能
MR: batch 只是实行批处理作业的(成为跟PIG,HIVE同等的作业方式)
Tez:execution engine 负责 执行引擎
RT STREAM GRAPH 实时的流式处理
1版本的mapreduce到了2版本被切割成了多个功能,切割出来的都称为公共功能框架
RM: Resource Manager
NM: Node Manager
AM: Application Master
container:mr任务;

mapreduce依赖于tez来完成,也可以不依赖tez(执行引擎),高性能内存 spark,高性能计算 openmpi
hadoop的作业任务如何运行 RM: Resource Manager资源管理器,(启动的任务,每个任务自己有AM,负责管理自己内部的各task任务)
RM: Resource Manager资源管理器,(启动的任务,每个任务自己有AM,负责管理自己内部的各task任务)
NM: Node Manager 节点管理,管理当前节点
node status 报告node当前信息
1 AM: Application Master 应用程序主节点,决定负责启动几个mapper,几个reducer
container:mr任务;作业都在容器运行,(cgroups可以向namespace来配置可以使用的资源量)每个container可能里面有map或者reduce,称为container中的任务
container执行的监控与否不断发给app master,启动几个container是由app master决定
jobtracker和tasktracker完成的任务被切割成了多部分,作业管理(Resource Manager)和资源分配,被组成两个不同的组件
NM: Node Manager 周期性向 Resource Manager报告节点相关信息,
资源管理和程序任务运行二者任务分割开来,程序运行由app master
资源 resource manager
resource manager询问节点是否有空余的容器来运行程序,找到节点的主控app master,剩下的该怎么运行由 app master分配,需要启动再哪个节点上的container,app master向 resource manager申请,resource manager找到节点把对方所请求的container给分配好,分配好后告诉app master,app master 就可以使用这个container来运行作业了,node manager运行好了,报告给 rm ,rm 报告app 收回资源 在
在
这就是hdoop2的实现框架
版本变化
natch蜘蛛程序抓到放到lucene上
2006hadoop项目诞生
2008 数据压力测试成功,声名大振
2009 0.20.0诞生
hadoop1已经不维护了 http://hadoop.apache.org
http://hadoop.apache.org
hadoop2上可以跑批处理程序,交互式接口,Hbase,流式数据处理,内存计算,高性能计算
hadoop的接口是mapreduce,要使用hadoop,就写mapreduce程序(redis-cli,mongodb也是如此)
hive是由facebook研发的,运行在yarn的tez之上,让用户能sql语句的方式完成数据处理,写的sql语句需要由mapreduce来进行处理转换调用mapreduce的作业
mapreduce就是批处理系统,运行起来很慢 ,hive的叫HQL与sql类似,但也需要自己去学习,hive是让用户以sql语句的方式来让用户运行任务的,mysql这种关系型数据库的接口是sql接口
linux操作系统的接口是shell
hive小蜜蜂pig二师兄,想简单实用mapreduce可以使用pig或者hive,pig是一个脚本编程语言接口
HDFS存储是流式数据,仅支持追加或者新建文件
HBASE是大表,在sql流派中,属于列式存储,sql是行式存储,hbase是按列存储,有行和列组成,每个列存储为一个单元,多个列,为列组column group ,找行数据还需要遍历,这么存的数据,是不考虑按行来访问的,访问的时候可能只访问分属列组的几个数据
cell 这个存储可以多版本并存,能够实现cell中的multi 并存,历史版本都可以留存,任何需要某个版本都可以指明,hbase有时光机器
每个cell对每个列都是属于键值存储,
hbase最终是工作在hdfs之上的,hbase任何数据都要表现为存储为hdfs 上,trunk,一旦需要用到数据块上要划出来,在列式的上面新增数据然后写到数据块上
hbase有接口,非sql也有增删改查的接口,hbase要另起一套集群,为了避免脑裂需要zookeeper,确保集群运行正常,hdfs本身就有冗余能力
这就是hadoop
非常著名的是三个插件
如果想把关系型数据库mysql导出来以mr的方式处理,需要一个数据抽取导入工具,
data exchange 工作在hadoop之外帮你在其他关系型数据库中抽取数据并导入到hadoop之上的,也能将hadoop上的数据抽取结构化导入到关系型数据库中,叫做sqoop
flume =log collector,日志收集器类似logstash,收集好日志以流式的方式导入到hbase中,是一个独立的日志收集系统,日志可以放到文件,也可以放到HDFS
除了pig,hive。hbase还有一个OOzie=work flow 工作流工具,(怎么把你的mapreduce任务编排起来,形成工作流)
Rconnectors R是著名的编程语言,R语言是统计学上用来实现数学统计的语言
Mahout】=machine learning 机器学习,下一步就是deep learning 深度学习,实现人工智能
生态圈很大https://hadoop.apache.org/old/
Avro™:数据序列化系统
Cassandra™: A scalable multi-master database with no single points of failure.可扩展的多种数据库,无中心节点的nosql
 、
、
日志收集工具
快速通用的实时计算引擎,计算分布式,在内存中完成,spark的接口是一个编程语言

RT stream graph 实时流式数据处理

zookeeper =coordination 协调工具
**hadoop最好不要运行在虚拟机上,io要求非常大,尤其HDFS,linux上,把hadoop每一个组件做成docker镜像
Ambari是一个hadoop 全生命周期管理工具,也是分布式
安装管理监控 **

Hadoop Distribution:分发版
Cloudera: CDH Cloudera distribution hadoop
Hortonworks: HDP Hortonworks distribution platform
Intel:IDH intel distribution hadoop
MapR
单机模式 伪分布式模式,,分布式模式
