文章目录
索引
排好序
索引是帮助Mysql高效获取数据的排好序的数据结构。
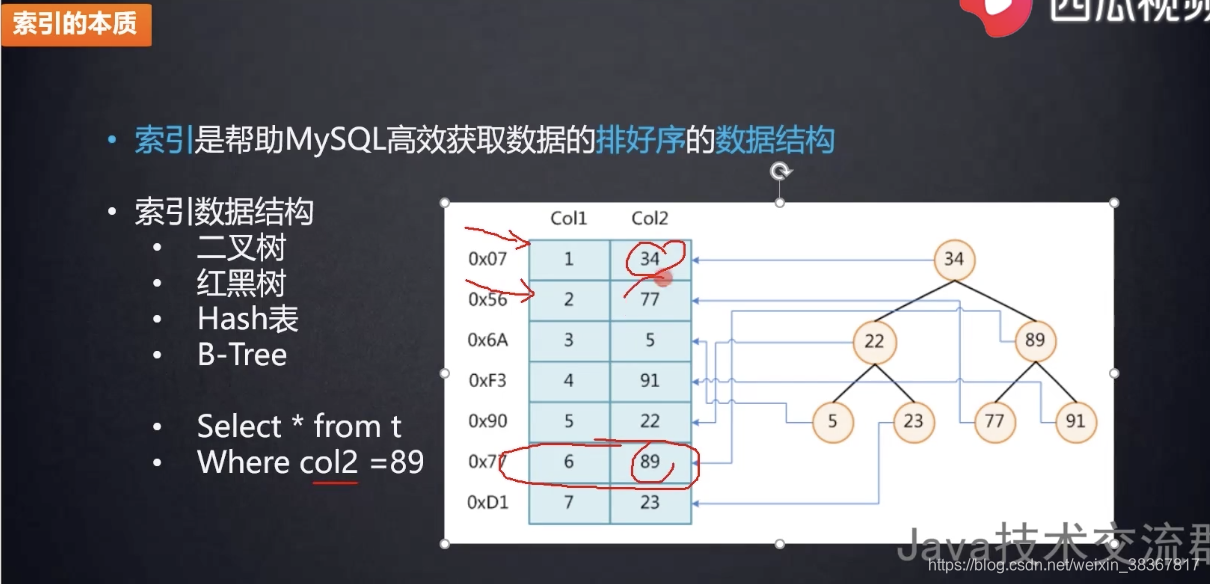
为什么不使用红黑树作为索引?
硬盘基础知识
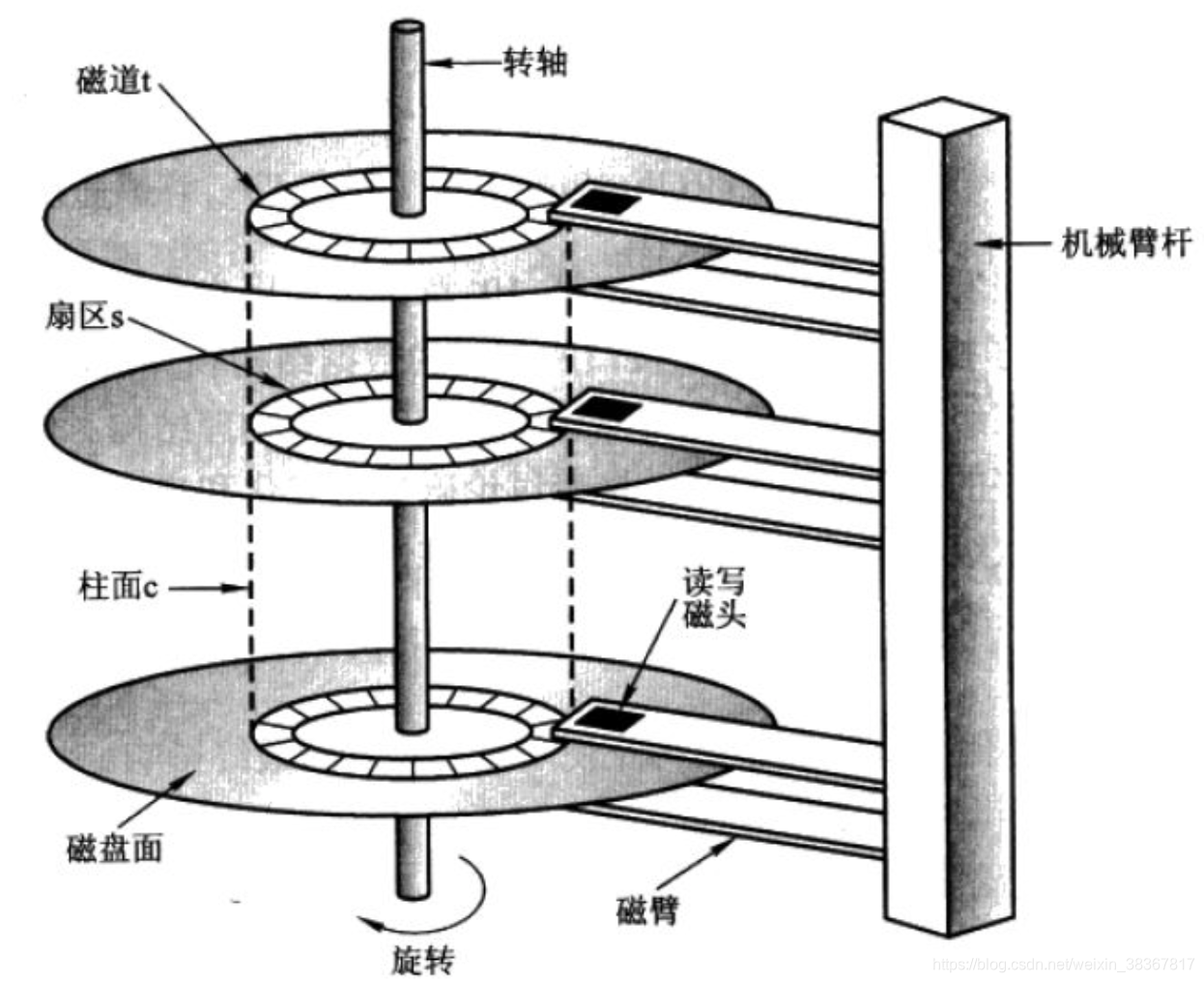
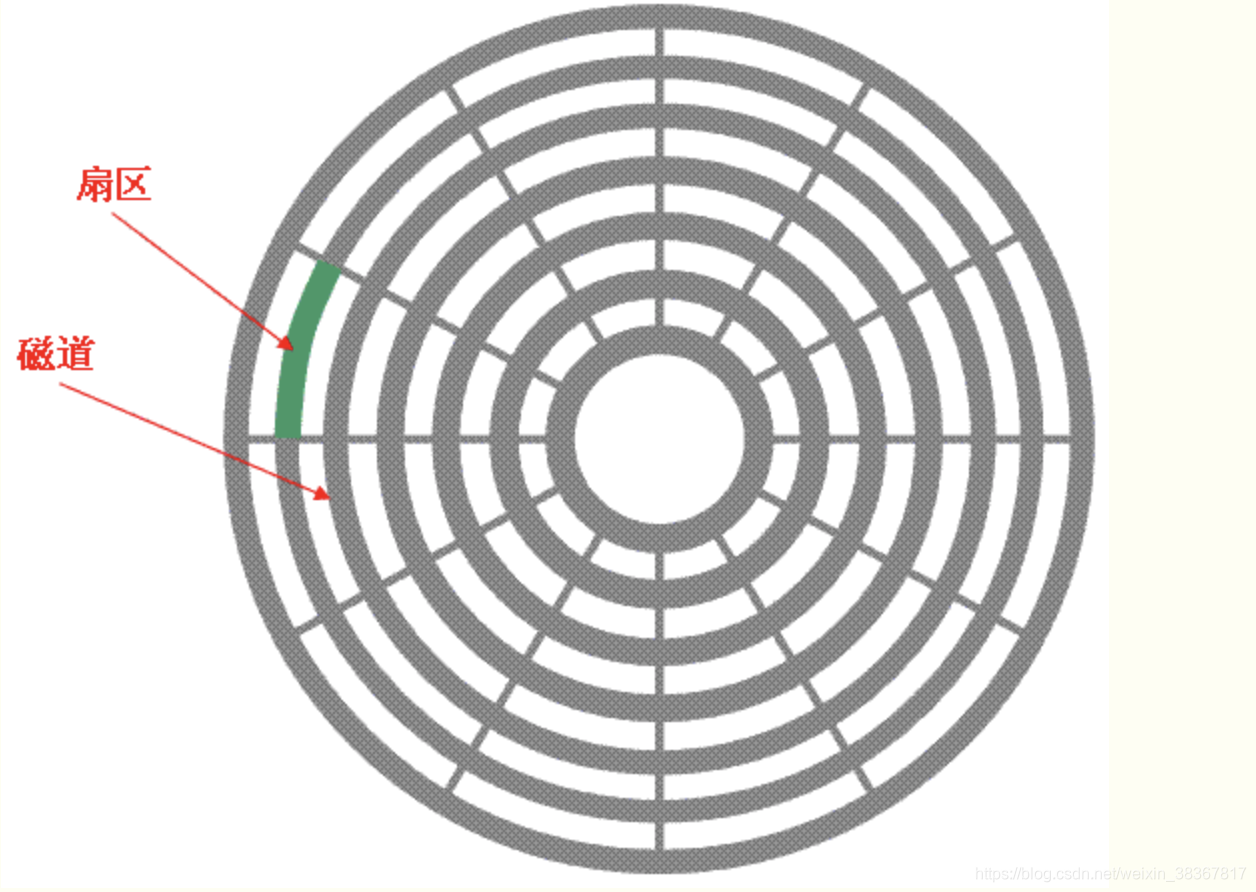
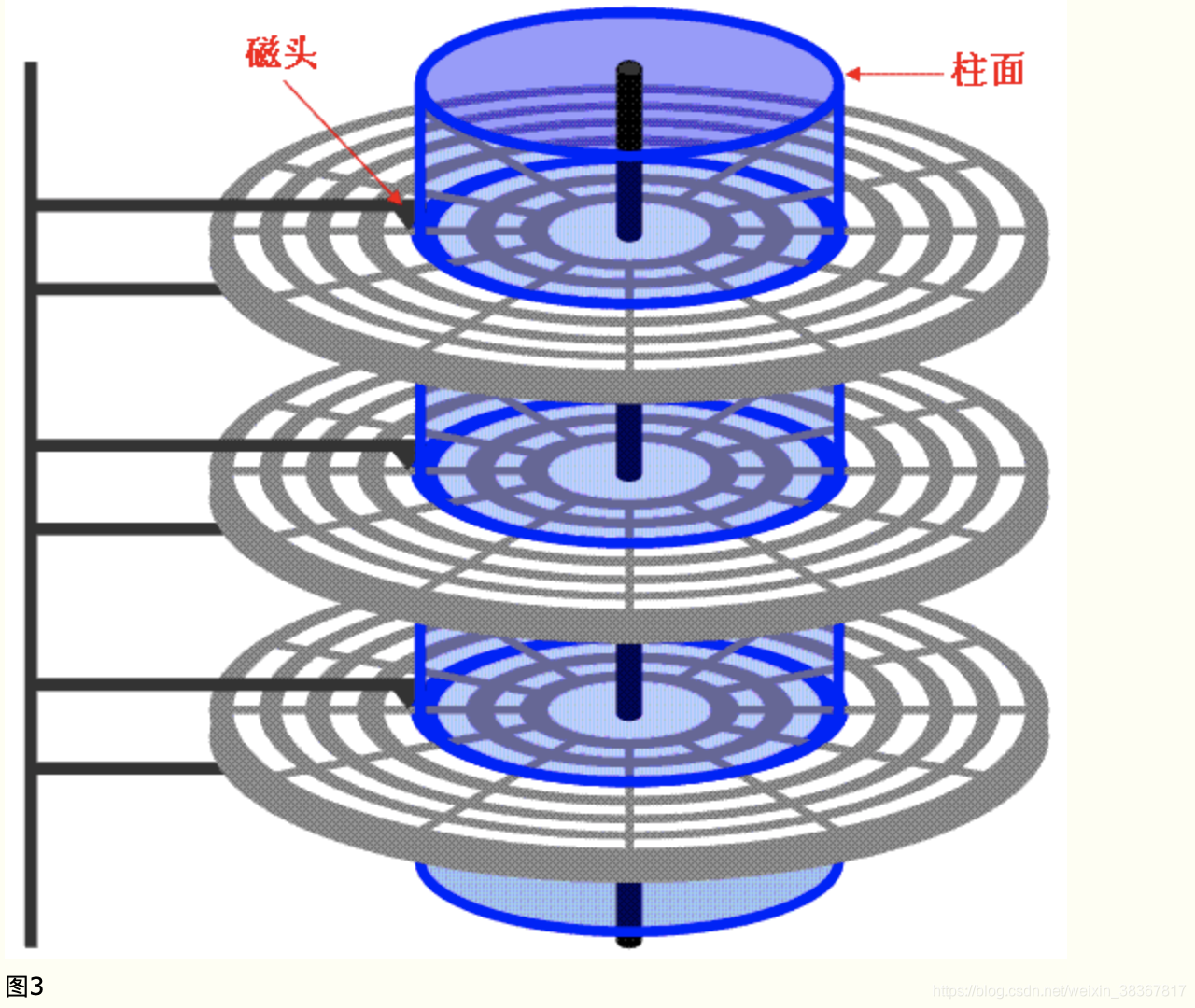
- 磁盘容量计算
存储容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
图3中磁盘是一个 3个圆盘6个磁头,7个柱面(每个盘片7个磁道) 的磁盘,图3中每条磁道有12个扇区,所以此磁盘的容量为:
存储容量 6 * 7 * 12 * 512 = 258048
硬盘块/簇的概念
磁盘块/簇(虚拟出来的)。 块是操作系统中最小的逻辑存储单位。操作系统与磁盘打交道的最小单位是磁盘块。
通俗的来讲,在Windows下如NTFS等文件系统中叫做簇;在Linux下如Ext4等文件系统中叫做块(block)。每个簇或者块可以包括2、4、8、16、32、64…2的n次方个扇区。
为什么存在磁盘块?
读取方便:由于扇区的数量比较小,数目众多在寻址时比较困难,所以操作系统就将相邻的扇区组合在一起,形成一个块,再对块进行整体的操作。
分离对底层的依赖:操作系统忽略对底层物理存储结构的设计。通过虚拟出来磁盘块的概念,在系统中认为块是最小的单位。
Page
操作系统经常与内存和硬盘这两种存储设备进行通信,类似于“块”的概念,都需要一种虚拟的基本单位。所以,与内存操作,是虚拟一个页的概念来作为最小单位。与硬盘打交道,就是以块为最小单位。
扇区、块/簇、page的关系
扇区: 硬盘的最小读写单元
块/簇: 是操作系统针对硬盘读写的最小单元
page: 是内存与操作系统之间操作的最小单元。
扇区 <= 块/簇 <= page
使用B树或者B+树作为索引的原因
一般使用磁盘I/O次数评价索引结构的优劣。
show global status like ‘Innodb_page_size’; 默认16kb
操作系统读写磁盘的基本单位是扇区,而文件系统的基本单位是簇(Cluster)。
也就是说,磁盘读写有一个最少内容的限制,即使我们只需要这个簇上的一个字节的内容,我们也要含着泪把一整个簇上的内容读完。
那么,现在问题就来了
一个父节点只有 2 个子节点,并不能填满一个簇上的所有内容啊?那多余的内容岂不是要浪费了?我们怎么才能把浪费的这部分内容利用起来呢?哈哈,答案就是 B+ 树。
由于 B+ 树分支比二叉树更多,所以相同数量的内容,B+ 树的深度更浅,深度代表什么?代表磁盘 io 次数啊!数据库设计的时候 B+ 树有多少个分支都是按照磁盘一个簇上最多能放多少节点设计的啊!
所以,涉及到磁盘上查询的数据结构,一般都用 B+ 树啦。
B树、B+树
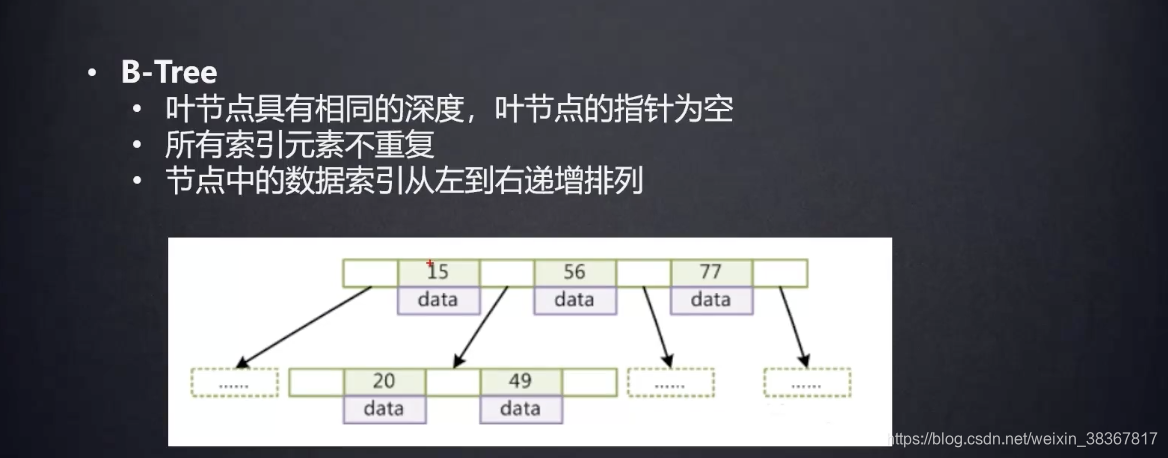
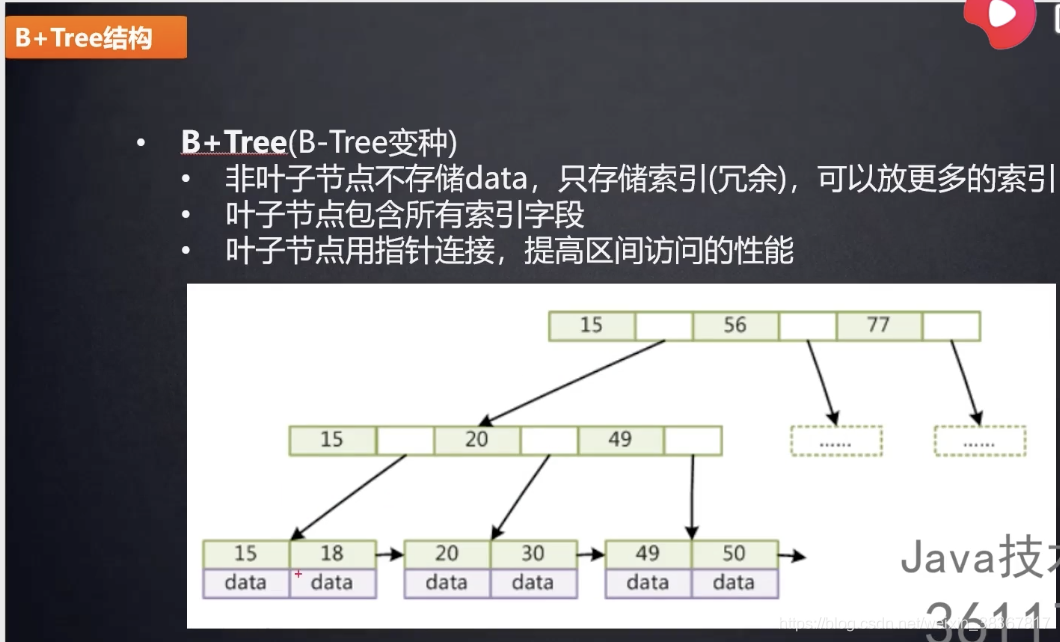 B+树只存储索引的key,没存放data,而且B+树的索引出现了很多次。
B+树只存储索引的key,没存放data,而且B+树的索引出现了很多次。
B+说因为没放data,所以块(页)可以存更多的索引数据。
如果索引用BigInteger存放占8字节(B),指针占6字节,块一共16kb,所以可以放1170个索引key和指针,如果一共三层,且一个索引key+data=1kb,则一块可以存放16个真正结点数据(key+data),则三层就可以存放真正的结点数据1170117016,则三层就可以存放2000多万个数据。
MyISAM索引文件和数据文件是分离的(聚集索引)

.frm 即frame存放表结果定义数据
frm即frame 框架
.MYD即MyISAM Data
.MYI 即MyISAM Index 存放索引数据
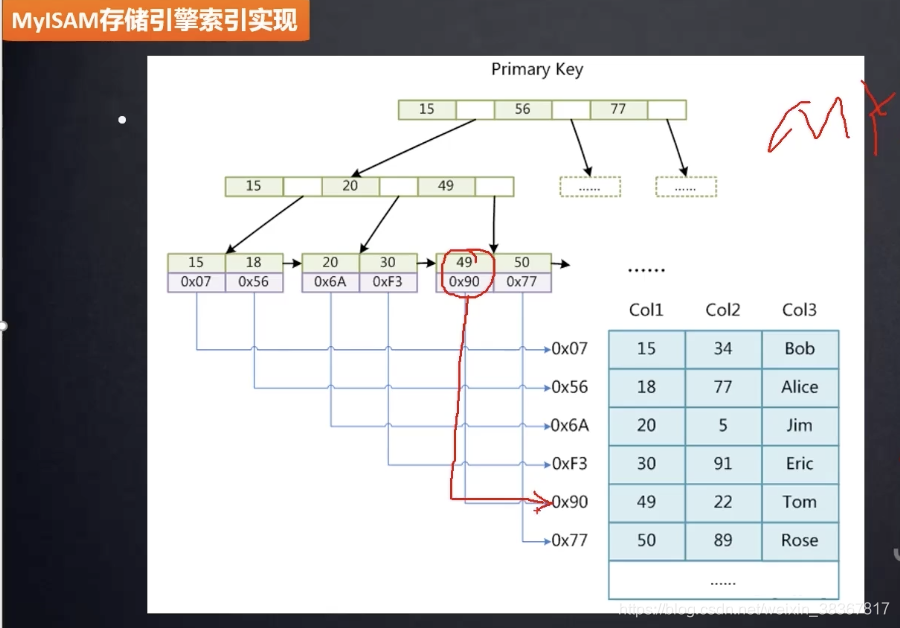
key存放索引元素,data存放索引所在行的磁盘文件地址指针,拿到这个地址指针可以到MYD中快速定位数据。
Innodb(非聚集索引)
 innodb将索引和数据文件合并放在一个文件里面即ibd文件。
innodb将索引和数据文件合并放在一个文件里面即ibd文件。
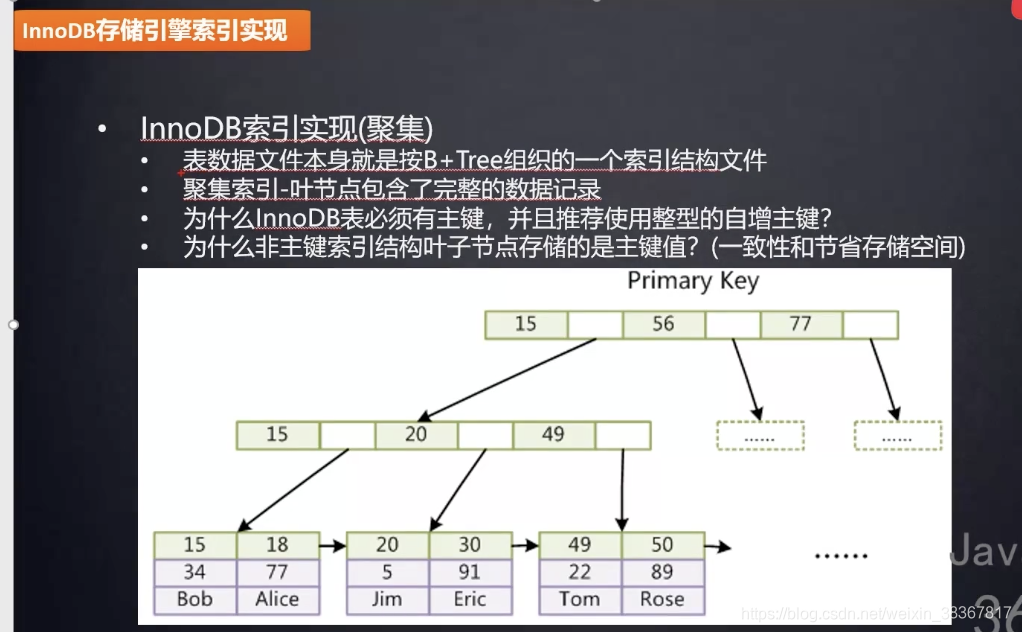
聚集索引
索引和数据聚集在一个文件里面,比如innodb的主键索引。
非聚集索引要通过MYI和MYD文件找到数据,而聚集索引通过ibd文件一个文件全部搞定。
所以聚集索引的效率比非聚集索引的效率高。
为什么InnoDB表必须有主键?
推荐使用整型的自增主键
Mysql实际的时候,InnoDB数据就是按照主键组织的。
为什么推荐使用整型,就是因为整型比较比uuid那些快,磁盘占用空间也比uuid少。
也有Hash查找,但是Hash索引对于范围查找就会失效了。
