第五章、创建高性能的索引
存储引擎使用索引:1、在索引中找到对应值,2、据匹配的索引记录找到对应数据行。
一、索引基础
1、索引特点
- 索引可以包含一个或者多个列的值,如果索引包含多个列,那么列的顺序也十分重要,因为MySQL只能高效地使用索引的最做前缀列。。
- ORM工具能够产生符合逻辑的、合适的查询,除非只是生存非常基本的查询,否则他很难生成适合索引的查询
- 在MySQL中,索引在存储引擎层而不是服务器层实现的,所以,并没有统一的索引标准:不同存储引擎的索引的工作方式并不一样,也不是所有的存储引擎都支持所有类型的索引。
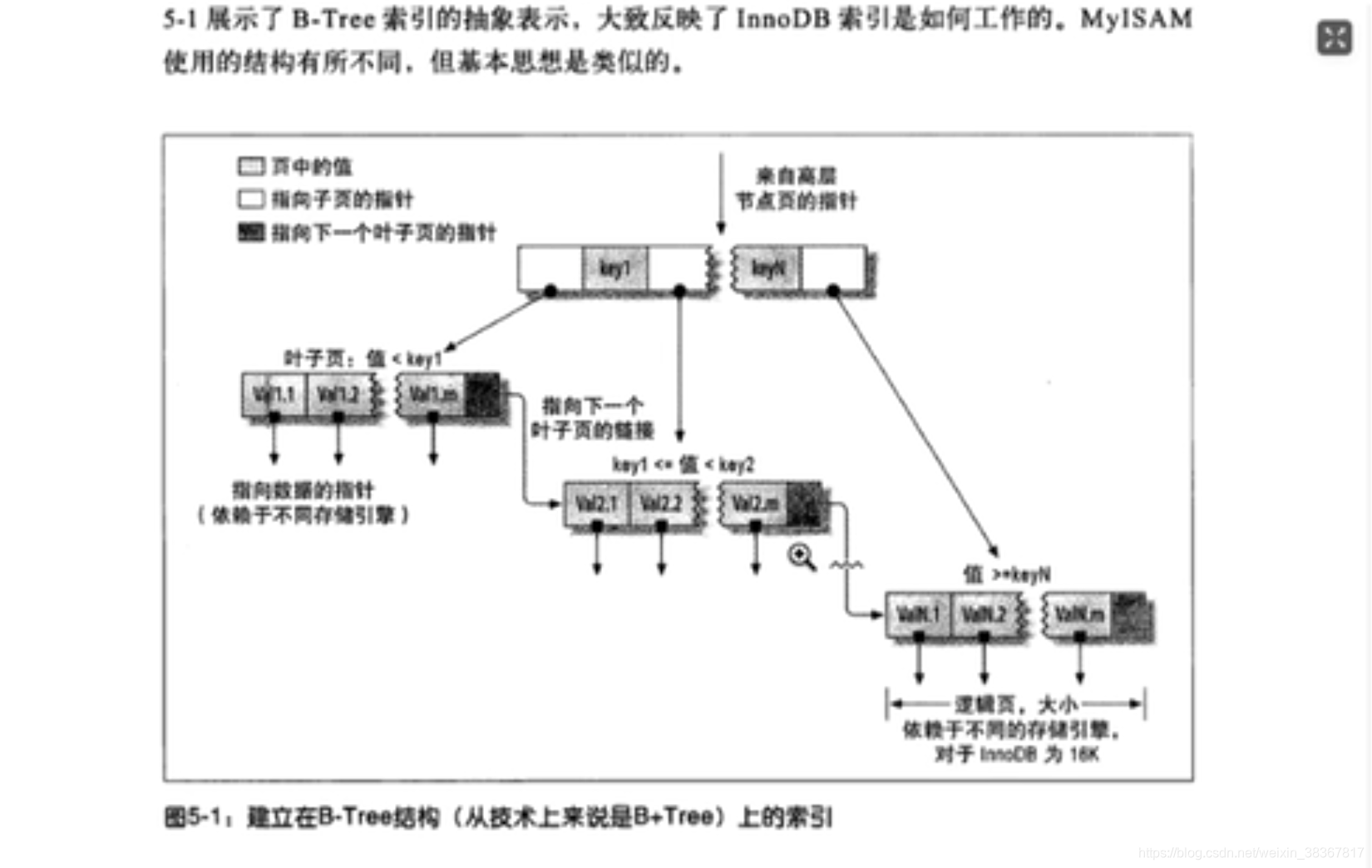
如果没有特别指明类型,我们所说的索引多半是B-Tree(mysql的InnoDB是B+树)。
B-Tree意味着所有的值都是按照顺序存储的,很适合范围查找,并且每一个叶子页到根的距离相同,B-Tree能够加快访问数据的速度,从索引的根结点开始进行搜索,适用于键值完全匹配、键值范围或键前缀查找。
B-Tree还可以用于查询中的ORDER BY(正序反序)和GROUP BY。
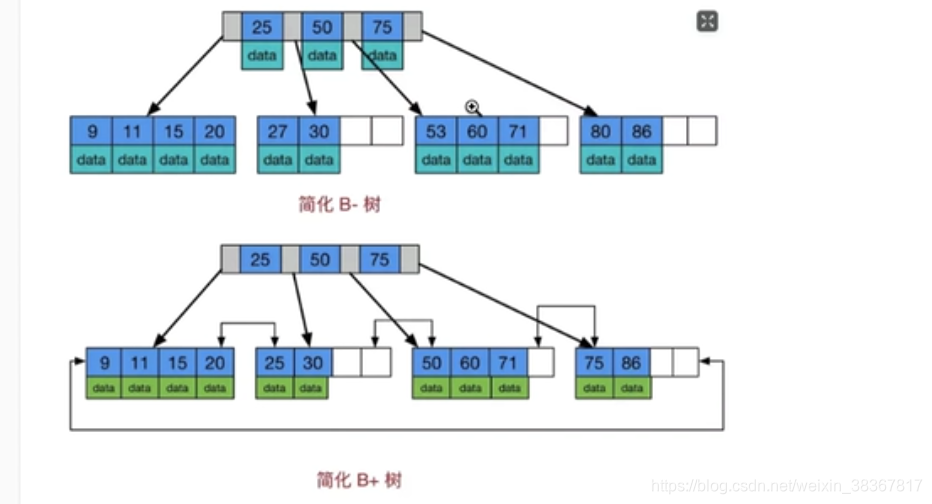
B-树和B+树区别:
B-树每个节点都有数据,而B+树只有叶子节点有数据。
2、B-Tree索引的限制
- 如果不是按照索引的最左列开始查找,则无法使用索引(逻辑上可以提供)
where c2=‘2’ - 不能跳过复合索引中的列
where c1=‘1’ and c3=‘3’ - 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
where c1=‘1’ and c2 like ‘2%’ and c3=‘3’
3、哈希索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效,只有Memory 引擎显式支持哈希索引。
哈希索引的限制
- 哈希索引只包含哈希值和行指针、不存储字段值,所以不能使用索引中的值来避免读取行(不论如何都会访问数据)
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序
- 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的
- 只支持等值比较查询,不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突
- 如果哈希冲突很多的话,一些索引推护操作的代价也会很高。
InnoDB有“自适应哈希索引”,当某些索引值被非常频繁使用时,会在内存中基于B+Tree索引上再创建一个哈希索引,是完全自动的内部行为,无法控制或配置。
伪哈希索引,举例:以要所搜的长URL建立始希值字段,并加上索引。
4、空间数据索引
空间数据索引(R-Tree),以MyISAM表支持空间索引,可以用作地理数据存储,MySQL的GIS支持并不完善,大部分人都不会用这个特性,开源数据库系统中对GIS的解决方案做的比较好的是PostgreSQL的PostGIS
5、全文索引
适用于MATCH AGAINST操作,而不是普通的WHERE条件操作。
二、索引的优点
三个优点
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O
索引的三星系统
- 索引将相关的记录放到一起则获得一星
就是whee后面的等值谓词,可以匹配索引列顺序
where后面的谓词和索引列匹配的越多,索引片越窄,最终扫描的数据行也是越小 - 如果索引中的数据顺序和查找中的排序一致则获得二星
退免排序,如果结果集采用现有顺序读取,那么就会避免一次排序,避免提前物化结果集 - 如果索引中的列包含了查询中需要的全部列则获得三星
避免每一个索引行查询,都需要去聚族索引进行一次随机IO查询
三、高性能的索引策略
- 1、独立的列
如果查询中的列不是独立的,则 MySQL不会使用索引。
“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数
SELECT * FROM Tablel WHERE Col1+1=5 //表达式
SELECT * FROM Table2 WHERE TO_DAYS(col1)… //函数 - 2、前缀索引和索引选择性
1、通常可以索引开始的部分字符,可以大大节约索引空间,但也会降低索引的选择性
2、索引的选择性是指,不重复的索引值(也称为基数, cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间,选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行
3、MySQL无法使用前缀索引做 ORDER BY和 GROUP BY,也无法做覆盖扫描 - 3、选择合适的索引列顺序
正确的索引列顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要
在一个多列B-Tree索引中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列
将选择性最高的列放到索引最前列 - 4、聚簇索引
并不是一种单独的索引类型,而是一种数据存储方式,
聚簇:表示数据行和相邻的键值紧紧存储在一
起, InnoDB通过主键聚簇数据,如果没有定义主键, InnoDB会选择一个唯一的非空索引替代,如果没有这样的索引,会隐式定义一个主键来作为聚簇索引
聚簇索引优点
更快的数据访问
缺点
- 最大限度提高了I/O密集型应用的性能,但如果数据全部放入内存中,则访问顺序的就不太重要,没有优势
- 插入速度严重依赖插入顺序,按主键顺序插入是加载数据到 InnoDB表中速度最快的方法
- 更新聚集索引的代价很高
- 更多的页分裂page split问题,占用更多空间,全表扫描变慢。
- 非聚集索引(二级索引)可能比中更大,二级索引叶子节点包含了主键列,二级索引需要2次索引查找
最好避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是对于IO密集型的应用 - 覆盖索引:如果一个索引包含(或者说覆盖)所有需要查询的字段的值,就称为覆盖索引
- MySQL有两种方式可以生成有序的结果:通过排序操作或按索引顺序扫描
如果 EXPLAIN出来的type列的值为 index,则说明MySQL使用了索引扫描来做排序 - 重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引,应该避免这样创建重复索引
- 索引可以让查询锁定更少的行
8.1)InnoDB行锁是通过给索引上的索引项加锁来实现的,意味着只有通过索引条件检索数据,InnoDB才使用行级锁,否则, InnoDB将使用表锁
8.2)由于 MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的
8.3),当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引, InnoDB都会使用行锁来对数据加锁
84).即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL通过判断不同执行计划的代价来决定的,如果 MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
四、维护索引和表
主要3个工作,找到并修复损坏的表,维护准确的索引统计信息,减少碎片。
1、CHECK TABLE检查表是否损坏, ALTER TABLE innodb_tb1 ENGINE= INNODB;修复表
还可以使用一些存储引擎的工具,如 myisamchk,或者将数据导出一份再重新导入;
如果损坏的表系统区域或是表的”行数据”区域,而不是索引,可以从备份中恢复,或者尝试从损坏的数据文件中尽可能的恢复数据。
如果是 InnodB引擎的表出现了损坏,一定是发送了严重的错误,比如硬件问题内存或硬盘,或从外部操作了数据文件,或InnoDB的缺陷(不太可能),常见类似错误是由于尝试使用的rsync备份InnoB导致的
如果遇到数据损坏,最重要的是找出是什么导致了损坏,而不只是简单修复,否则很可能还会不断损坏。
可以通过设置 innodb_force_recovery参数进入 InnoDB强制恢复模式来修复数据。还可以使用开源的 InnodB数据恢复工具箱( InnoDB Data Recovery Toolkit)直接从InnoDB数据文件恢复出数据。
2.更新索引统计信息
MySQL查询优化器会通过2个API来了解存储引擎的索引值的分布信息;
records_in_range()通过向存储引擎传入两个边界值获取在这个范围大概有多少条记录,对于 innodb不精确
info()返回各种类型的数据,包括索引的基数.
通过运行 ANALYZE TABLE重新生成统计信息;
InnoDB通过抽样的方式来计算统计信息,首先随机读取少量索引页面,以此为样本计算统计信息
innodb_stats_persistent默认ON
innodb_stats_ persistent-sample_pages 20
innodb_stats transient_ sample_pages 8
表的大小发生非常的变化(变化超过1/16或新插入20亿行)计算索引统计信息:
InnoDB打开某些INFORMATION SCHEMA表或使用 SHOW TABLE和SHOW INDEX或 MySQL客户端开启自动补全功能时都会触发索引统计信息的更新,如果有大量数据,可能会导致严重的问题,开关
innodb_stats_on_metadata OFF
4.可以使用SHoW INDEX FROM表名命令来查看索引的基数
5.B-Tree索引可能会碎片化,这会降低查询的效率
InnoDB ALTER TABLE table_name ENGIN=InnoDB;
消除表(聚集索引)的碎片化,索引碎片需要重建索引消除;
MyISAM OPTIMIZE TABLE
