一、NoSql数据库(内存数据库,非关系型数据库)有哪些?
1、redis
2、mongdb
3、memcache
4、tair(淘宝自研发)
二、什么是Redis?
1、Redis是完全开源免费的,是一个高性能的key-value数据库
2、Redis是单线程的基于C语言写的
3、Redis没有windows版本的只有linux版本的
三、关系型数据库和非关系型数据库的区别?
关系型数据库:数据是存放到硬盘的,每次读取数据都是io操作,效率比较低
非关系型数据库:数据是放到内存里的,也有一些持久化操作的机制
四、Redis应用场景:
1、Token令牌的生成!!!
2、可以实现缓存查询数据,可以减轻关系型数据库的访问压力!!!
3、分布式锁!!!
4、延迟操作:比如下了订单没有支付,库存减少了,可以设置超时时间,超时了库存增加!!!
具体例子,比如下单30分钟未支付自动更新订单状态
1、采用定时任务,30分钟后检查该笔订单是否已经支付(性能不好,不推荐)
2、根据key有效期时间回调实现(推荐)
实现
1、创建订单的时候绑定一个订单token(不用订单编号是因为不安全)存放在redis中(有效期只有30分钟)
2、token过期时执行回调方法判断订单状态
5、分布式消息中间件
6、日志
7、短信验证码的code
8、实现计数器
五、为什么Redis没有Windows版本的只有Linux版本的?
1、Redis的底层采用Nio中的IO多路复用机制,使用一个线程维护多个的Redis客户端连接,能够非常好的支持并发和保证线程安全问题
2、在windows中select选择器是使用for循环,容易空轮询,时间复杂度为O(n)
3、在linux中是采用epoll实现事件驱动回调,不会存在空轮训的情况,只对活跃的socket连接实现主动回调,这样性能上有很大的提升,所以时间复杂度为O(1)
六、Redis中分为16(0~15)个库的作用?
不同的库中的key是可以相同的,相同库的key是不能相同的
七、Redis内存不会满吗?
redis默认没有设置内存上限,一般是为可申请内存的大小,也可以配置,maxmemory ,当数据达到限定大小后,会选择配置的策略淘汰数据
比如:maxmemory 300mb。
八、Redis中有哪些数据类型?
1、String(字符串类型):最大能存储 512MB
2、Hash(哈希):是一个键值(key=>value)对集合
3、List(列表):简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
4、Set(集合):集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)
5、zset(sorted set:有序集合):和 set 一样也是string类型元素的集合,且不允许重复的成员
九、Redis存放对象的方式有哪些?
1、使用json的序列化和反序列化
优点:直观、可视,跨语言
缺点:占内存,不安全
2、使用redis自带的序列化方式(序列化成二进制),实体类要实现序列化接口
优点:安全、二进制比较不占内存
缺点:不可视,二进制不能跨语言,只能转换成java对象,不能转换成其他语言的对象,json可以跨语言
十、全量同步与增量同步的区别?
1.全量同步:就是每天定时(避开高放弃)或者是采用一种周期的实现将数据拷贝另外一个地方。
频率不是很大,但是可能会造成数据的丢失。
2.增量同步:采用行为操作对数据的实现同步,频率非常高、对服务器同步的压力也是非常大的、保证数据不丢失。
十一、RDF与AOF实现持久化的区别?
1、AOF,基于数据日志操作实现持久化,增量同步,appendonly.aof文件
开启aof:redis.conf中修改appendonly为yes
三种aof模式:
1、appendonly always:有数据改变就写入,同步次数多,io操作频繁
2、appendonly everysec(默认):使用缓冲区,每秒定时从缓冲区写入到aof文件中,可能存在丢失
3、appendonly no 从不同步。高效但是数据不会持久化,是否开启aof
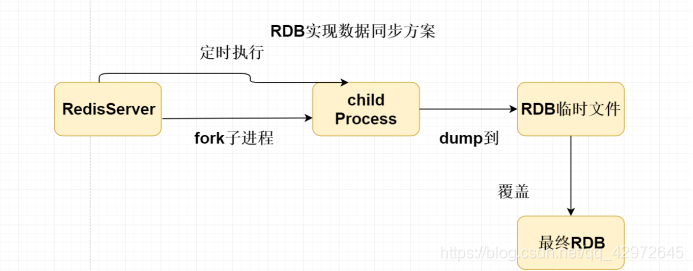
2、RDB(默认),定时持久化机制==,全量同步==,有一个临时RDB文件和最终RDB文件,每次持久化的时候会生成RDB临时文件覆盖上一次的RDB临时文件,Redis宕机之后临时文件就成为了最终RDB文件,Redis宕机恢复之后是使用最终dump.RDB文件恢复到内存中,定时执行的时候会开出一个fork子进程进行同步数据到硬盘。比如:90秒后判断key的变化次数有没有超过10次,有就进行持久化
注意:如果aof与rdb都开启优先使用aof
十二、MySQL与Redis如何保持数据一致性?
1、直接清理redis缓存,重新查询
2、直接采用mq订阅mysql binlog(update、insert、del操作都会记录)日志文件增量同步到Redis中
3、使用alibaba的canal(底层就是方法二)
十三、SpringBoot整和Redis注解版本
1、主类上加@EnableCache
2、方法上加@Cacheable(cacheName=“分类目录”,key="‘一般为方法名,要加单引号’")
3、对象实现序列化接口
十四、Redis六大内存淘汰策略:内存空间满,自动驱逐老数据
1、noeviction(默认):当内存使用达到阈值的时候,执行命令当内存使用达到阈值的时候,执行命令直接报错
2、allkeys-lru:在所有的key中,优先移除最近未使用的key。(推荐)
3、allkeys-random:在所有的key中,随机移除某个key。
4、volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
5、volatile-random:在设置了过期时间的键空间中,随机移除某个key。
6、volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
十五、Redis中的事务
Redis事务操作:Redis中没有回滚,但是有取消提交事务
Multi:开启事务,把key和value放加入到队列中,保持原子性
EXEC:提交事务
Discard:取消提交事务
Watch:可以监听一个或者多个key,在提交事务之前是否有发生了变化 如果发生边了变化就不会提交事务,没有发生变化才可以提交事务
watch name //启动监听
multi //开启事务
set name xiaoxiao //添加key-value
exec //提交事务
十六、Redis与Mysql中的事务有哪些区别?
Redis事务没有隔离性,同一时间对同一条数据操作,没有锁,谁最后提交数据就是怎么样的
Mysql事务具有隔离性,同一时间对同一条数据操作,会有行锁,事务提交释放锁
十七、取消事务和回滚事务的区别?
回滚事务:取消事务和释放行锁
取消事务:单纯取消事务
十八、什么是分布式锁?举个场景
本地锁:在多个线程中,保证只有一个线程执行(线程安全的问题)
分布式锁:在分布式中,保证只有一个jvm执行(多个jvm线程安全问题)
比如集群中每个jar都是相同的,jar包中有个定时任务,多个jar会重复执行这个定时任务,这时候就可以采用分布式锁解决,任务调度重复性问题
十九、解决分布式锁核心思路:
1、获取锁:多个不同的jvm同时创建一个标记(全局唯一的标记),谁能创建成功谁就获取锁
2、释放锁:释放该全局唯一的标记,其他的jvm重新进入到获取锁资源
3、超时锁:根据超时策略来决定怎么处理
####二十 、实现分布式锁的三种方式:
1、基于数据库方式实现:谁先获取到行锁,谁就获取到分布式锁
2、基于zk方式实现:采用临时节点+事件通知
3、Redis方式实现:使用setnx命令方式,创建一个key,谁先成功创建这个key谁就获取到分布式锁
4、采用框架,比如Redis官网有一个redis解决分布式锁的框架redission
set:如果key不存在则创建,存在则修改原值
setnx:如果key不存在则创建,返回1,存在则不执行任何操作,返回0。
二十一、Redis和zk实现分布式锁的优缺点?
获取锁:差不多
释放锁:差不多
超时锁:zk是用session超时,效率会低些,关闭当前Session连接,自动的删除当前的zk节点路径,其他线程重新进入到获取锁阶段。redis key到期自动释放锁
二十二、如果业务逻辑达到超时时间还没结束怎么办?
方法一:根据自己写的业务逻辑判断大概时间设置key的超时时间
方法二:在提交事务的时候检查锁是否已经超时,如果已经超时则回滚,否则提交(推荐)
二十三、分布式锁的应用场景?
1、分布式任务调度平台保证任务的幂等性
2、分布式全局id的生成
二十四、Redis集群实现高可用的三种方式?
1、传统的主从复制
2、主从复制+哨兵机制
3、分片集群
二十五、Redis主从复制原理
1、从redis.conf中:slaveof指向主的ip和端口号还有主服务的密码
2、启动之后主从建立socket长连接
3、采用全量(发送二进制dump.rdb文件,而不是aof)和增量(aof)的形式将数据同步给从redis服务器,首次从节点启动的时候,主节点同步数据是全量的形式,之后主写数据是采用增量的
4、网络出现问题,从节点再次连接主节点时,主节点补发缺少的数据,每次数据增量同步
主master:做读写操作
从slaveof:只读,把写操作交给主节点
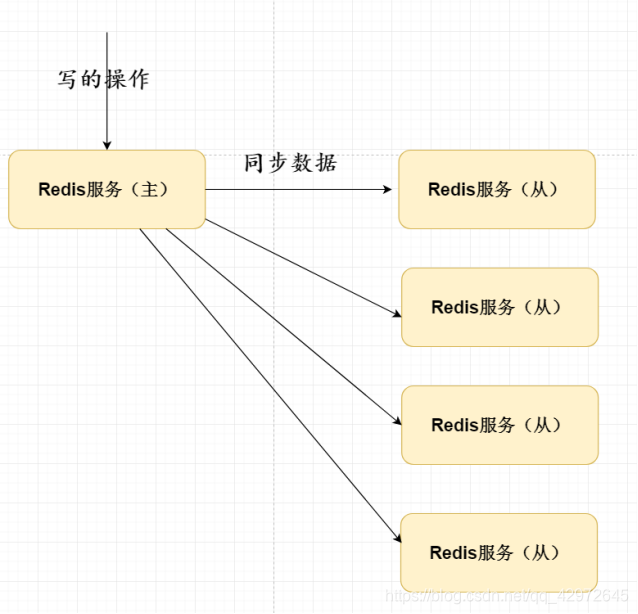
二十六、传统的一主多从会存在哪些问题?
1、如果主节点存在了问题,整个Redis环境是不可以实现写的操作,需要人工更改配置变为主操作
如何解决该问题:使用哨兵机制可以帮助解决Redis集群主从选举策略。
2、同步的服务器多,效率低,所以采用树状形式
二十七、Redis哨兵机制的作用?
Redis的哨兵机制就是解决我们以上主从复制存在缺陷(选举问题),解决问题保证我们的Redis高可用,实现自动化故障发现与故障转移。
二十八、哨兵机制原理
1、哨兵机制每隔10s时间就可以获取当前整个Redis集群的环境列表(整个节点结构),采用info replication命令形式。只需要配置监听我们的主节点。
2、多个哨兵都监听同一个主的master节点,订阅到相同都通道,有新的哨兵加入都会向通道中发送自己服务的信息,该通道的订阅者可以发现新哨兵的加入,随后相互建立长连接。Redis本身有通道,哨兵订阅到相同通道就集群了
3、Master的故障发现 单个哨兵会向主的master节点发送ping的命令,如果master节点没有及时的响应,哨兵会认为该master节点为“主观不可用状态”会发送给其他都哨兵确认该Master节点是否不可用,当前确认的哨兵节点数>=quorum(可配置),会实现重新选举
二十九、为什么哨兵集群数量要和Redis从节点数量一致?
保证选举公平性,哨兵只做选举,不做主从复制
三十、传统哨兵机制存在哪些问题?
Redis哨兵集群模式,每个节点都保存全量同步数据,冗余的数据比较多;而在Redis Cluster模式中集群中采用分片集群模式,可以减少冗余数据,缺点就是构建该集群模式成本非常高,
三十一、Redis分片集群
Redis3.0开始官方推出了集群模式 RedisCluster,原理采用hash槽的概念,预先分配16384个卡槽,并且将该卡槽分配给具体服务的节点;通过key进行==crc16(key)%16384 ==获取余数,余数就是对应的卡槽的位置,一个卡槽可以存放多个不同的key,从而将读或者写转发到该卡槽的服务的节点。 最大的有点:动态扩容、缩容。
redis5.0分配卡槽比较方便,3和4分配很麻烦,要安装插件
/usr/redis/bin/redis-cli --cluster create 192.168.212.163:7000 192.168.212.163:7001
192.168.212.163:7002 192.168.212.163:7003 192.168.212.163:7004 192.168.212.163:7005
--cluster-replicas 1
1代表比例都为1,前三个为主,后三个为从,默认是没有转发功能的,这个命令后要加-c 代表集群,就有转发了,转发是你访问的key不在这台redis上时可以给你转发到别的redis上,只有主节点上有卡槽,从节点没有
三十二、Redis分片集群的扩容和缩容
扩容时会指定的节点上分配
缩容会平均的分配到每个节点上
三十三、Redis安全相关内容:对数据库压力大
1、缓存穿透:访问redis中不存在的key,绕过redis直接访问数据库,频繁的高并发查询,导致缓存无用
解决方案:
1、接口实现api的限流,防御ddos,接口频率限制
2、从数据库和redis都查询不到数据的情况下,把数据库的空值写入缓存中,加上短时间的有效期(只适合单个key,也会影响正常使用,不推荐)
3、布隆过滤器
2、缓存击穿:高并发情况下访问热点key,热点key又突然过期了,所有的请求都直接访问数据库
解决方案:
1、使用分布式锁解决,对查询数据库上锁,适合服务器集群,让其中一个查询数据到缓存,其他的直接读缓存
2、本地锁与分布式锁一样的
3、软过期,对热点key设置无限有效期,获取异步延长时间
3、缓存雪崩:和缓存击穿差不多,是多个热点key同时失效,或者redis重启且没有持久化
解决方案:
集群化分摊部署key
三十四、基于布隆过滤器解决缓存穿透问题
布隆过滤器:公开的数据结构算法,不是redis独有的,适用于判断一个元素在集合中是否存在,但是可能存在误判的问题,概率是非常非常低的。默认百分3的概率误判,误判概率越低,数组长度越长,设置多少合适?取决于项目
预热机制:在生产环境中,要提前把热点key先缓存到redis中,使用布隆过滤器把数据先放到redis缓存中,查询redis缓存时从布隆过滤器中查,布隆中没有就代表redis缓存中没有
缓存击穿使用布隆过滤器解决:
1、预热:把数据库中数据放到布隆中
2、查询布隆过滤器,布隆中不存在就代表数据库中没有这个key,zhijiu
3、查询redis
4、redis中不存在,再查询数据库
误判情况:
查询id=66的,布隆过滤器中存在(其实应该是不存在),redis中也没有,才查询数据库
==========================================================================
redis的key和value都不能为null
jedis,java客户端连接redis的工具,默认不支持集群,默认不支持重定向
问题:分布式中是不存在强一致性的,只能最终一致性,zk不是强一致性的吗?
多级缓存采用装饰模式实现
大部分的缓存框架都会有淘汰策略(Redis内存慢进行淘汰策略,先进先出)、持久机制这些基本功能,而EhCache没有持久化机制
使用Redis Key自动过期机制
当我们的key失效时,可以执行我们的客户端回调监听的方法。
需要在Redis中配置:
notify-keyspace-events “Ex”
版本号码 乐观锁
value用uuid判断是否是自己线程
单机版和集群版Redis分布式锁实现方式不同
怎么知道当前节点是否为主节点?
通过命令:info replication
哨兵如何选举主节点?
redis从节点宕机了怎么办?
小项目用哨兵,大项目用cluser
